サマリー
今週の研究は、GUI対応のVLM/LLMエージェントの構築から、プラットフォーム・能力レベル・障害モードを横断したより厳密な評価への移行を反映している。代表的な論文は、現行のベンチマークが依然として狭すぎる——単一プラットフォーム上のタスク成功率に限定されることが多い——一方で、グラウンディング精度、運用効率、ハルシネーション診断、プライバシーを考慮した実行の測定が不十分であると主張している。
テーマの状況
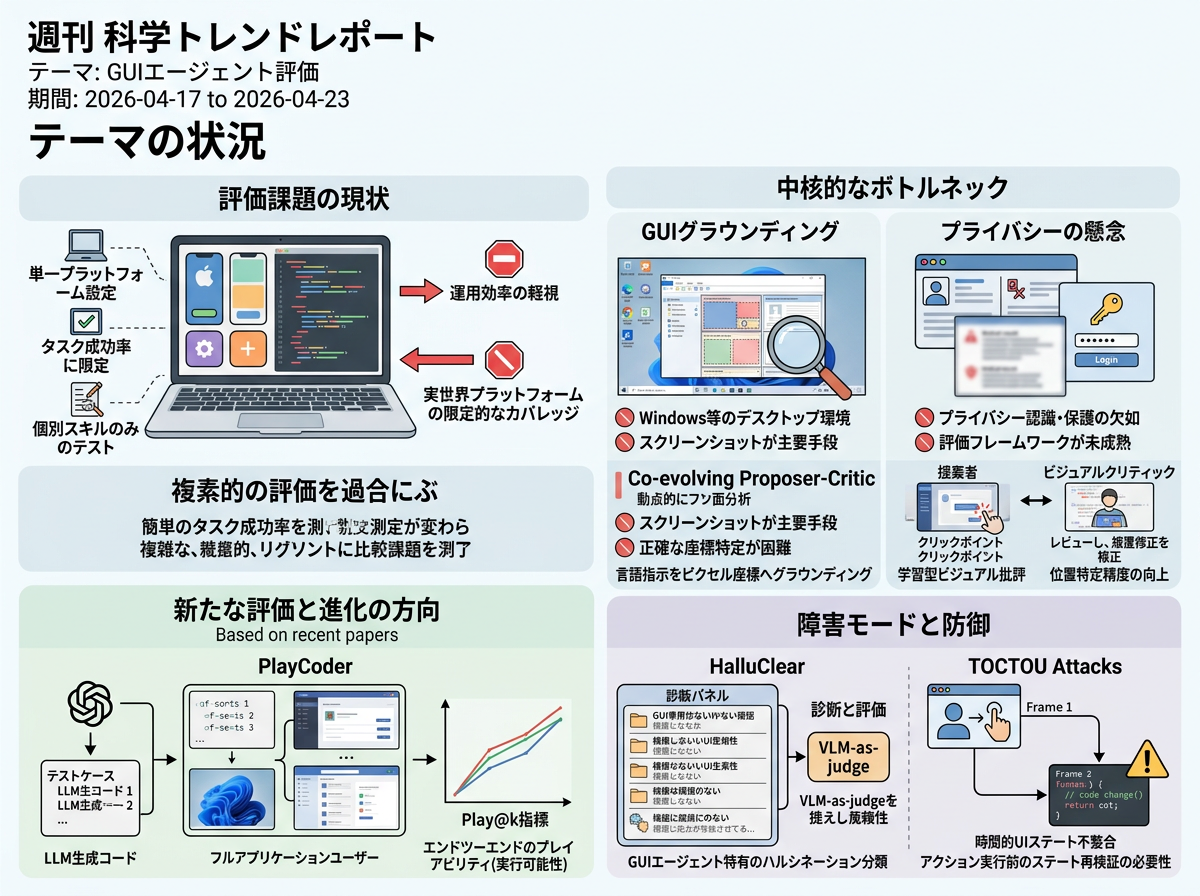
視覚言語モデルやマルチモーダル言語モデルの性能向上に伴い、GUIエージェントはソフトウェア環境全体にわたる複雑なインタラクションの自動化にますます活用されるようになっている。しかし、代表的な論文は、評価がこの進歩に追いついていないことを強調している。既存のベンチマークは、インターフェース理解から実行に至る一連の流れではなく個別のスキルをテストすることが多く、成功率に主眼を置いて運用効率を軽視し、デスクトップシステムやクロスアプリケーション設定といった実世界プラットフォームのカバレッジが限定的である。
各論文の導入部では、特に重要な2つのギャップも指摘されている。第一に、正確なGUIグラウンディングが依然として中核的なボトルネックであり、特に構造化されたインターフェースメタデータが利用できずスクリーンショットが主要なインタラクション手段となるWindows等のデスクトップ環境で顕著である。第二に、現実的な展開においてはプライバシーの懸念が生じる。GUIエージェントは機密性の高い個人情報を含むスクリーンショットを頻繁に処理するが、プライバシー認識・保護・プライバシー制約下でのタスク実行を測定するための成熟したベンチマークやフレームワークはまだ存在しない。
- WinClick: GUI Grounding with Multimodal Large Language Models
- MMBench-GUI: Hierarchical Multi-Platform Evaluation Framework for GUI Agents
インフォグラフィクス(日本語)
今週の進展
VLAA-GUI: Knowing When to Stop, Recover, and Search, A Modular Framework for GUI Automation <See Details on Fugu-MT>
VLAA-GUI: Knowing When to Stop, Recover, and Search, A Modular Framework for GUI Automationは、今週のテーマを定着させるシード論文である。 今週の進展を解釈するためのベースライン参照として位置づけられる。
PlayCoder: Making LLM-Generated GUI Code Playable <See Details on Fugu-MT>
PlayCoderは、LLM生成アプリケーションがテストケースの正解だけでなくエンドツーエンドでプレイ可能かどうかをベンチマークすることで、GUI評価の範囲を拡張した。 コードレベルの正確性に焦点を当てた従来の評価と比較し、43アプリの多言語ベンチマークと実行可能なプレイアビリティを対象とするPlay@k指標を導入している。
Measure Twice, Click Once: Co-evolving Proposer and Visual Critic via Reinforcement Learning for GUI Grounding <See Details on Fugu-MT>
本論文は、静的な一貫性ヒューリスティクスを、言語指示をピクセル座標にグラウンディングするための学習型ビジュアルクリティックに置き換えることで、GUIエージェントの中核的なボトルネックに取り組んでいる。 共進化する提案者-批評者アプローチにより、モデルが画面上のビジュアル提案から選択できるようになり、固定的な選択戦略を上回る位置特定精度の向上を実現している。
HalluClear: Diagnosing, Evaluating and Mitigating Hallucinations in GUI Agents <See Details on Fugu-MT>
HalluClearは、GUIエージェント特有のハルシネーションの診断・評価・軽減のための専用スイートを提供している。 従来の広範なタスク成功指標と比較し、GUI特有のハルシネーション分類体系と、VLM-as-judgeの信頼性を向上させる3段階評価ワークフローを導入している。
Temporal UI State Inconsistency in Desktop GUI Agents: Formalizing and Defending Against TOCTOU Attacks on Computer-Use Agents <See Details on Fugu-MT>
本論文は、時間的UIステート不整合(TOCTOU攻撃)をデスクトップGUIエージェントの固有の障害モードとして定式化している。 静的な画面を前提とした従来のスクリーンショット後クリック方式と比較し、アクション実行前のステート再検証の必要性を実証し、軽量な3層防御を提案している。
今後の展望
今後の展望(要約)
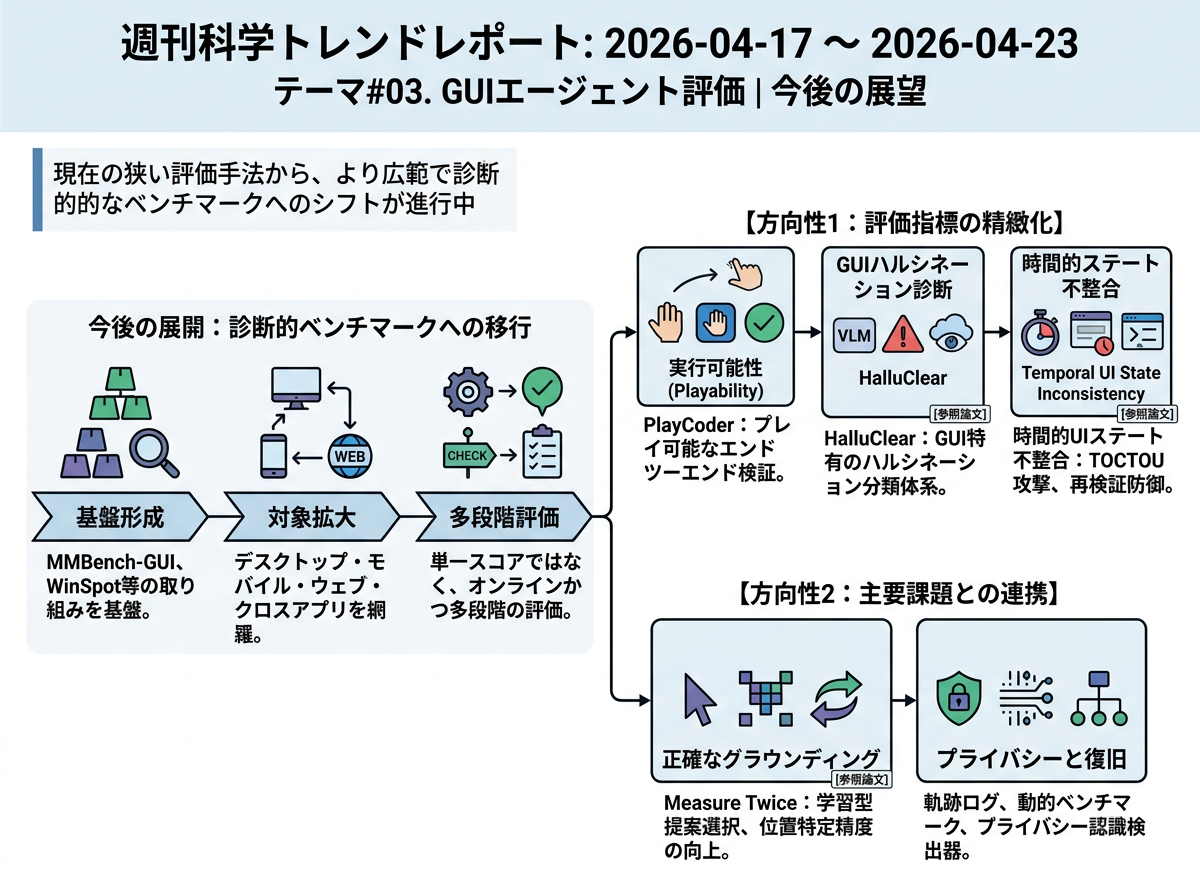
GUIエージェント評価は、単一スコアのランキングから、より広い診断型ベンチマークへ移っていく可能性が高い。新しいテストは、デスクトップ、モバイル、Web、複数アプリをまたぐ作業を対象にし、タスク完了だけでなく、画面上の位置理解、効率、実行可能性、存在しないUI要素の幻覚、画面状態が変わったときの一貫性も評価する。この流れは、マルチプラットフォームGUIベンチマーク、デスクトップ上のグラウンディング、実行可能な操作性、幻覚分析の研究を反映している。もう一つの方向は、既知の弱点である正確な位置特定とプライバシー配慮型の実行に、評価をより近づけることだ。今後のベンチマークは、操作履歴、動的なUI状態、プライバシー検出器を使い、スクリーンショットが隠蔽・制約されてもエージェントが信頼できる行動を取れるかを調べるだろう。
インフォグラフィクス(日本語)
3年後を想定した動き
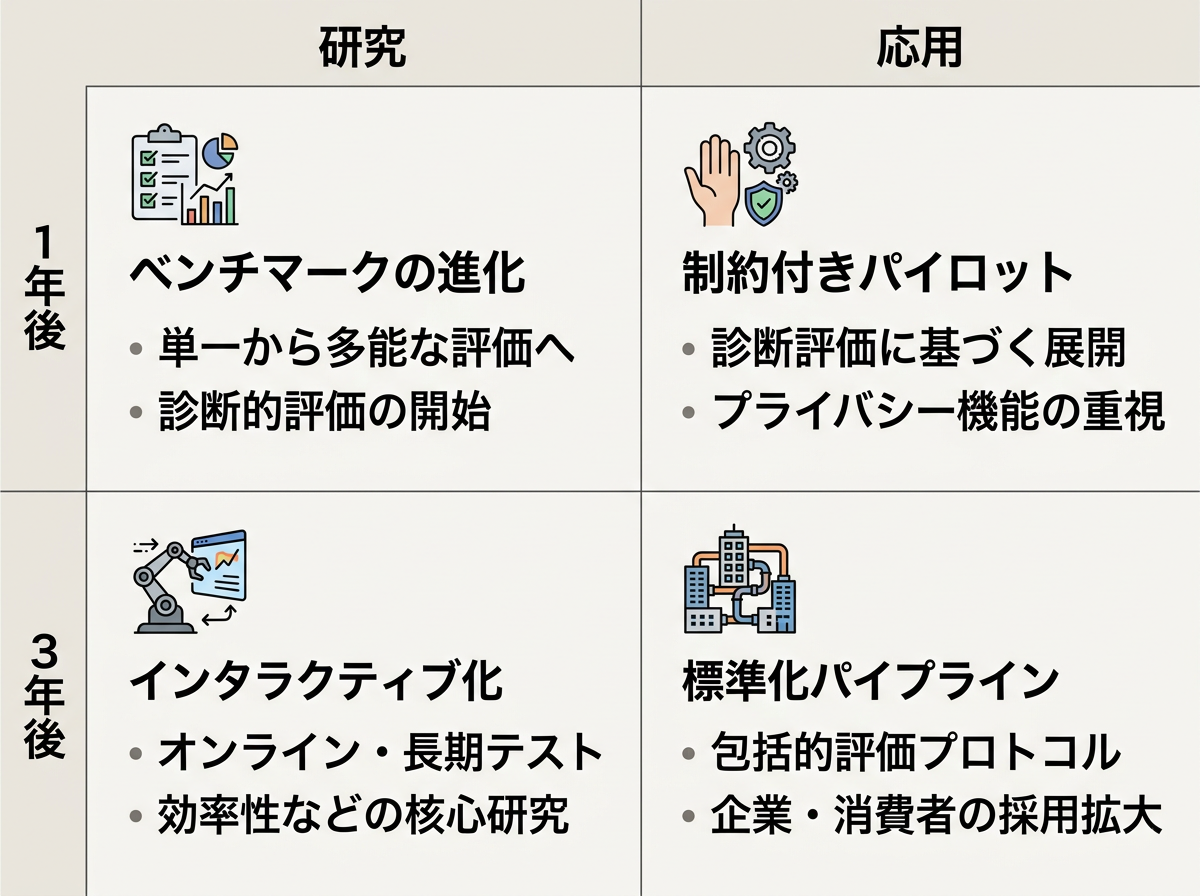
今後1年で、GUIエージェント評価は最終結果だけを見る方式から、各操作を点検する診断型へ進む可能性が高い。これらのテストは、エージェントの手順記録であるトラジェクトリログを使い、誤クリック、不要に多い操作、存在しないUI要素の幻覚、状態追跡の失敗、プライバシー上のミスを見つける。36か月後には、デスクトップ、モバイル、Web、複数アプリをまたぐ作業を対象に、実行中に画面が変わる対話型オンラインベンチマークへ広がるだろう。主な研究課題は、正確な位置特定、効率的な計画、安定した状態追跡、失敗後の回復、プライバシーを守ったタスク完了になる。実運用では、より細かい評価が、企業向けや消費者向けの限定されたワークフローを承認する手順の一部になる。
近い将来、より広いGUIエージェント用ベンチマークは、同じタスクでも再現性が崩れやすいという問題を明らかにするだろう。原因には、アカウント状態、アプリのバージョン、通知、プライバシーマスク、以前のエージェント操作による画面変化がある。そのため研究は、リセット機能、ログ、UI状態のスナップショット、バージョン記録、失敗を再生できるトレースを備えた、計測機能の強いベンチマーク環境へ向かう可能性が高い。36か月後には、先進的なベンチマークは静的なランキング表というより、継続的な評価サービスに近くなるかもしれない。そこでは、バージョン管理されたアプリ、リセット可能なアカウント、プライバシー条件の異なるタスク状態、制御されたUI変化、長い操作履歴の分析が維持される。エージェントは、変化し続けるが再現可能なGUI状態の中で、グラウンディング、効率、プライバシー遵守、回復力、時間的な一貫性を保てるかで評価される。実用面では、規制分野や高信頼性が必要な自動化は、モデルやソフトウェア更新の前後に自動チェックを繰り返すCIのようなテストパイプラインに依存し、導入判断も単なる成功率ではなく監査可能な証拠に基づくようになる。
今後1年で、プライバシーを意識したGUI評価は、完全なスクリーンショットと、敏感な領域を隠したサニタイズ済みスクリーンショットの両方でエージェントをテストするようになる可能性が高い。サニタイズは個人情報などを隠せる一方で、正しいボタン、入力欄、メニューを見つけるための視覚的な手がかりまで消してしまうことがある。ベンチマークは、失敗の原因が位置理解の弱さなのか、隠しすぎなのか、隠し足りなさなのか、あるいは画面変化後の混乱なのかを示す必要がある。36か月後には、この方向は動的な保護実行テストへ進むだろう。保護実行トレースは、エージェントが何を見たか、何が隠されたか、なぜ情報が表示または非表示にされたか、どの操作を行ったか、マスキングやUIのずれから回復できたかを記録する。進歩は、タスク成功率、操作ステップ数、プライバシー露出、位置理解の正確さ、頑健性の間のトレードオフとして測られる。応用では、エージェントは定義済みのワークフロー種別に限って導入され、可視範囲の予算、プライバシー検出器、部分表示でも位置を理解するモジュール、画面利用を後から確認できる監査記録が必要になる。
1年後・3年後の研究/応用インフォグラフィクス
参照論文
- WinClick: GUI Grounding with Multimodal Large Language Models - 著者: Zheng Hui, Yinheng Li, Dan zhao, Tianyi Chen, Colby Banbury, Kazuhito Koishida, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- MMBench-GUI: Hierarchical Multi-Platform Evaluation Framework for GUI Agents - 著者: Xuehui Wang, Zhenyu Wu, JingJing Xie, Zichen Ding, Bowen Yang, Zehao Li, Zhaoyang Liu, Qingyun Li, Xuan Dong, Zhe Chen, Weiyun Wang, Xiangyu Zhao, Jixuan Chen, Haodong Duan, Tianbao Xie, Chenyu Yang, Shiqian Su, Yue Yu, Yuan Huang, Yiqian Liu, Xiao Zhang, Yanting Zhang, Xiangyu Yue, Weijie Su, Xizhou Zhu, Wei Shen, Jifeng Dai, Wenhai Wang, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0