サマリー
今週のテーマは、世界モデル、動画生成モデル、マルチビュー生成モデルを表面的な視覚品質を超えて評価するベンチマーク研究に焦点を当てている。代表的な論文は、一般的な評価プロトコルがピクセルやもっともらしさの指標に過度に依存しており、身体化タスクの有用性、物理法則への準拠、3D整合性といった重要な特性を見落としていると主張している。さまざまなドメインにおいて、新たな評価は知覚的に優れた出力と下流利用に必要な機能的信頼性との間に繰り返し現れるギャップを明らかにしている。
テーマの状況
代表的な論文の序論は、急速に進歩する生成モデルや身体化モデルにとって評価が中心的なボトルネックであると位置づけている。WorldArenaは、身体化世界モデルが計画、意思決定、訓練、方策評価のためのメンタルシミュレータとしてますます扱われているにもかかわらず、既存のベンチマークは主に動画品質を評価するのみで、予測が行動整合的か、物理的に根拠があるか、身体化タスクに実際に有用かどうかを十分に測定していないと主張している。PhysicsMindは物理的推論と予測について同様の指摘をしている:視覚的に説得力のある生成や強力なマルチモーダル知覚は基本的な力学への準拠を保証せず、現在のモデルは依然として外見のヒューリスティクスに頼ったり、物理的にもっともらしくない軌道を生成したりしている。
共通する第二の懸念は、従来の評価設定がタスクの構造に対して狭すぎるか不適合であるということである。MVGBenchは、マルチビュー生成においてペアワイズの2D指標は誤解を招く可能性があると指摘している。有効なビューが複数存在しうるため、独立した画像スコアリングでは3D整合性が無視されるからである。これらの論文は全体として、包括的ベンチマーキングへの明確なシフトを示している:知覚的指標を法則認識・タスク認識・整合性認識の指標と組み合わせ、可能な場合は実環境とシミュレーション環境を使用し、モデルの品質が魅力的な出力から信頼できる世界理解へと転移するかどうかを検証するものである。
- MVGBench: Comprehensive Benchmark for Multi-view Generation Models
- PhysicsMind: Sim and Real Mechanics Benchmarking for Physical Reasoning and Prediction in Foundational VLMs and World Models
- WorldArena: A Unified Benchmark for Evaluating Perception and Functional Utility of Embodied World Models
インフォグラフィクス(日本語)

今週の進展
LoViF 2026 The First Challenge on Holistic Quality Assessment for 4D World Model (PhyScore) <See Details on Fugu-MT>
LoViF 2026 PhyScoreチャレンジは、7つの生成モデルからの1,554本の動画を用いた共有コンペティションとして、包括的な4D世界モデル評価を具現化した。 より広範な指標を求める以前の要請と比較して、包括的品質に関するモデル間の直接比較を可能にする標準化されたコンペティション設定を提供している。
A Benchmark for Interactive World Models with a Unified Action Generation Framework <See Details on Fugu-MT>
iWorld-Benchは、33万本の動画クリップと統一的な行動生成フレームワークにより、世界モデルのインタラクション関連能力を対象としたベンチマークを導入した。 受動的な動画出力に焦点を当てた従来の評価と比較して、多様な視点、天候、シーンにわたる行動条件付きダイナミクスを明示的にテストしている。
Reconstruction or Semantics? What Makes a Latent Space Useful for Robotic World Models <See Details on Fugu-MT>
本研究は、行動条件付き動画モデルのための6つの潜在エンコーダを体系的に比較し、視覚的忠実度、計画性能、下流方策の成功を評価した。 視覚的にもっともらしいロールアウトを重視していた従来のアプローチと比較して、潜在表現が信頼性のあるロボット計画と制御を支援するかどうかを直接測定している。
今後の展望
今後の展望(要約)
近い将来の研究では、世界モデルの総合的なベンチマークが、より広く標準化された評価セットへ拡張されていく可能性が高い。対象モデルやアーキテクチャ、物理表現、長い時間範囲、複雑な場面、多様な物体領域が増え、評価も「もっともらしい動画」だけでなく、介入、行動選択、計画、方策性能、身体性をもつ意思決定に実際に役立つかへ近づいていくだろう。
インフォグラフィクス(日本語)
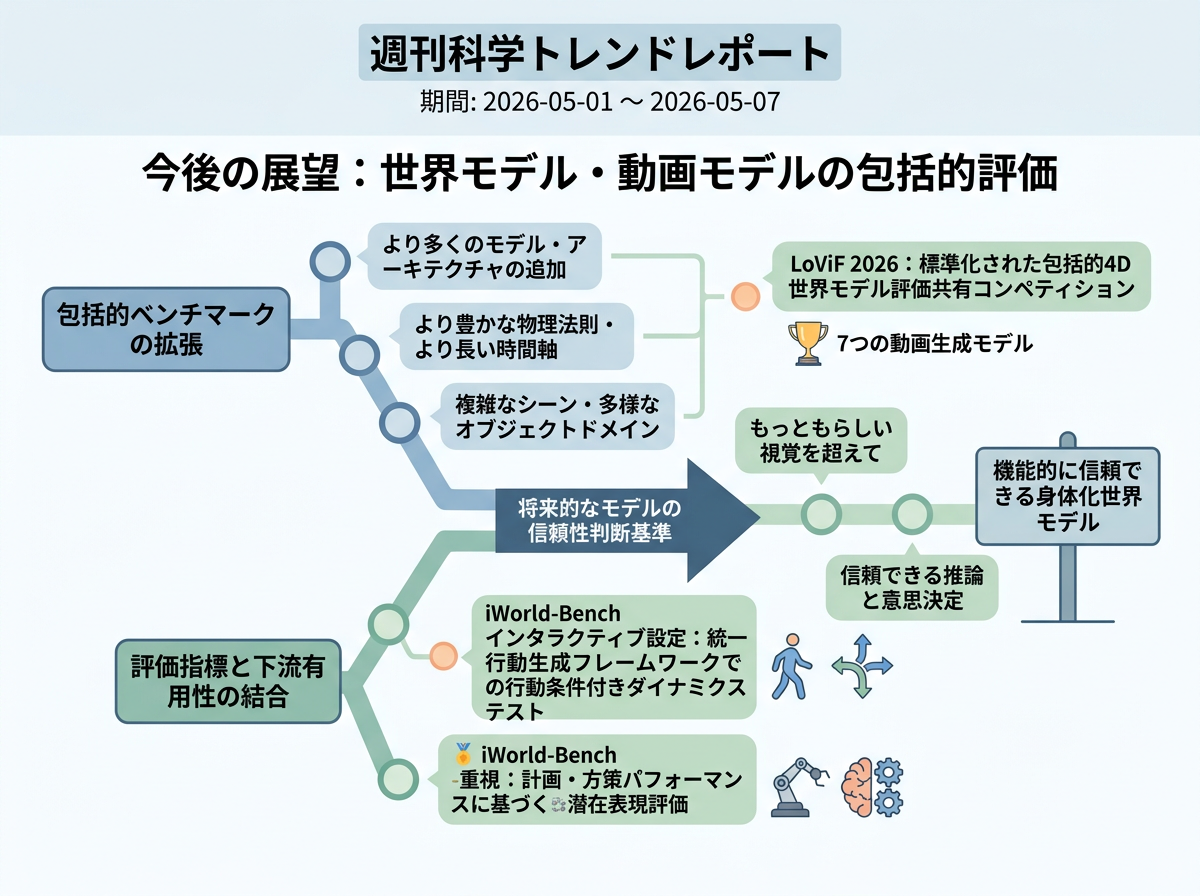
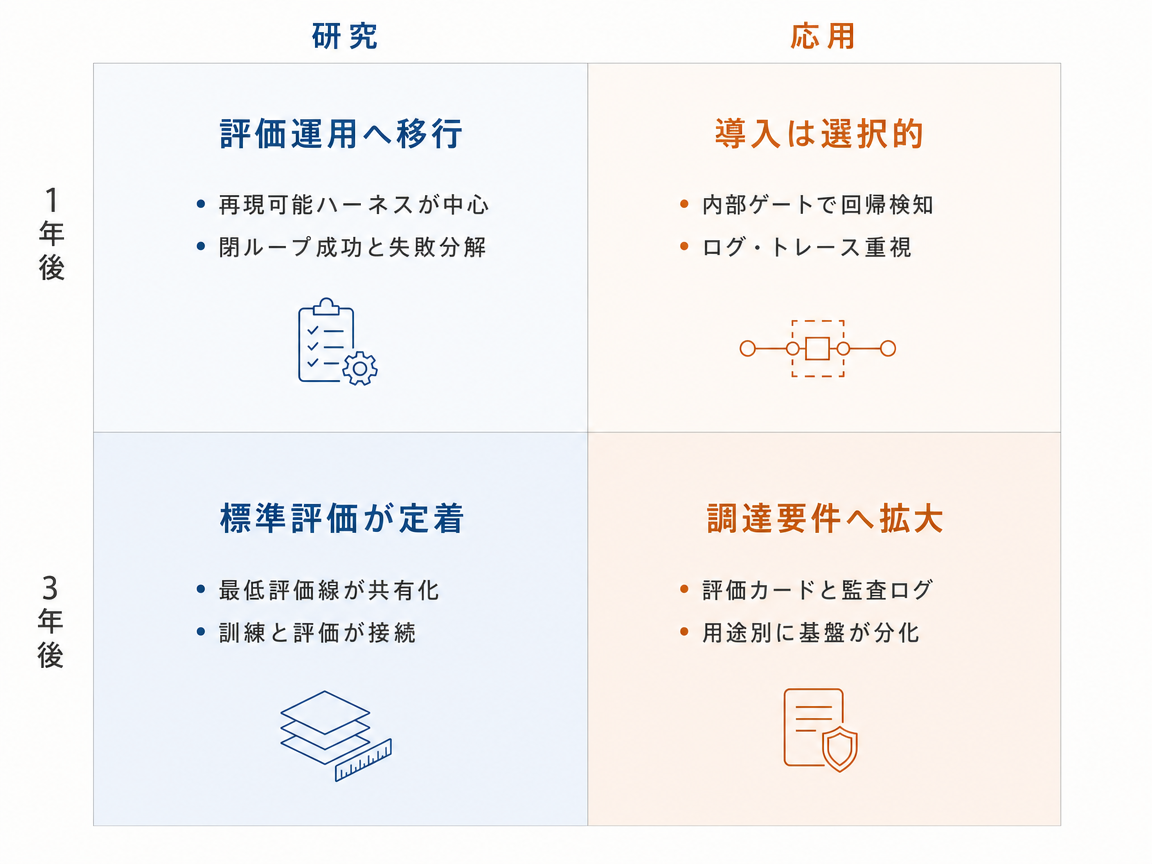
3年後を想定した動き
標準的な進み方では、今後3年で評価の中心は見た目の品質から、世界モデルや動画モデルを安定して検査できる実行可能な信頼性基盤へ移る。1年目には、WorldArena、PhysicsMind、MVGBenchのような最近のベンチマークが、タスク、シミュレータ設定、プロンプト、乱数シード、カメラ経路、行動系列を定めた、より固定的なテストパッケージになる。こうした行動系列により、ロボティクスやシミュレーションのチームは、モデルが計画、物理予測、3D一貫性のどこで失敗するかを調べやすくなる。1年目の終わりには、有力な研究所がこれらの評価セットを回帰テストとして扱い始める。つまり、動画の見た目が良くなっていても、新しいモデル版の信頼性が下がった場合にそれを発見する検査として使う。続く数年で、この実践は論文用の追加実験ではなく、モデル開発の通常工程になる。3年間の大きな流れは、表面的なリアルさだけでなく、推論や行動にどれだけ役立つかで世界モデルを比較し、機能的な失敗を診断する標準評価スイートへの移行である。
対抗シナリオでは、現実らしく見える出力だけでは不十分だという方向性は受け入れられるが、完全な評価にかかるコストが今後3年の普及を遅らせる。1年目には、資金力のある研究所がWorldArena、PhysicsMind、MVGBenchのような広い評価スイートを実行し、訓練改善や、計画、行動の有用性、物理、3D一貫性の検査に使う。一方で他のグループは、完全な身体性評価やシミュレータベースのテストに必要な計算資源、エンジニアリング、基盤整備を用意しにくいため、部分的な結果や安価な視覚指標を報告する。この差は分野内に長く残る分断を生む。大組織はモデルが計画や行動を本当に支えるかを調べられるが、小規模研究室や導入企業は、狭い独自テスト、ベンダーのデモ、見た目のもっともらしさに頼りがちになる。3年後ごろには、総合評価は望ましい標準として存在しているが、利用は均一ではない。主な変化は新しい評価方針の拒否ではなく、特に信頼できるモデル検査が高価なロボティクスやシミュレーションの現場で、その評価にアクセスできる組織とできない組織の差が広がることである。
可能性シナリオでは、今後3年で、単なるスコア表から閉ループ評価へのより大きな転換が起こる。閉ループ評価では、プランナや方策がモデルのロールアウトを使って実際に行動し、その成功率を直接測る。1年目には研究者はまだ総合指標を使うが、タスク成功率や物理監査と食い違う場合には、それらの指標だけでは不完全だと見なし始める。物理テストもより分解され、接触、保存則、剛体のふるまい、その他の力学的制約を別々に確認するようになる。2年目には、閉ループでの成功と、物理法則ごとの適合度が、身体性をもつ世界モデル研究で期待される証拠になる。同時に訓練は、動画品質だけでなく、方策の成果を高め、力学違反を減らすことも最適化対象にし始める。応用チームは、シミュレーション、計画、方策訓練にモデルを使う前に、ロールアウトログ、方策成功率の差分、物理テストの合格率を求めるようになる。3年目までには、安全上重要な身体性AI向けに、認証済みまたは認証準備済みの世界モデルが認識されたカテゴリになる可能性があり、総合スコアは診断には有用でも、信頼や導入の主な根拠ではなくなる。
1年後・3年後の研究/応用インフォグラフィクス
参照論文
- MVGBench: Comprehensive Benchmark for Multi-view Generation Models - 著者: Xianghui Xie, Chuhang Zou, Meher Gitika Karumuri, Jan Eric Lenssen, Gerard Pons-Moll, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- PhysicsMind: Sim and Real Mechanics Benchmarking for Physical Reasoning and Prediction in Foundational VLMs and World Models - 著者: Chak-Wing Mak, Guanyu Zhu, Boyi Zhang, Hongji Li, Xiaowei Chi, Kevin Zhang, Yichen Wu, Yangfan He, Chun-Kai Fan, Wentao Lu, Kuangzhi Ge, Xinyu Fang, Hongyang He, Kuan Lu, Tianxiang Xu, Li Zhang, Yongxin Ni, Youhua Li, Shanghang Zhang, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- WorldArena: A Unified Benchmark for Evaluating Perception and Functional Utility of Embodied World Models - 著者: Yu Shang, Zhuohang Li, Yiding Ma, Weikang Su, Xin Jin, Ziyou Wang, Xin Zhang, Yinzhou Tang, Chen Gao, Wei Wu, Xihui Liu, Dhruv Shah, Zhaoxiang Zhang, Zhibo Chen, Jun Zhu, Yonghong Tian, Tat-Seng Chua, Wenwu Zhu, Yong Li, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0