サマリー
今週の評価研究は、狭いベンチマーク設定を超え、LLMおよびVLMベースのエージェントに対するより広範なテストへと進展した。コンピュータ操作、GUI、ソフトウェアエンジニアリングの各領域において、代表的な論文は、現実の環境、多様なタスク、知覚・グラウンディングからマルチステップ実行に至る一連のプロセスをより的確に反映するベンチマークが進歩の鍵であると主張している。
テーマの状況
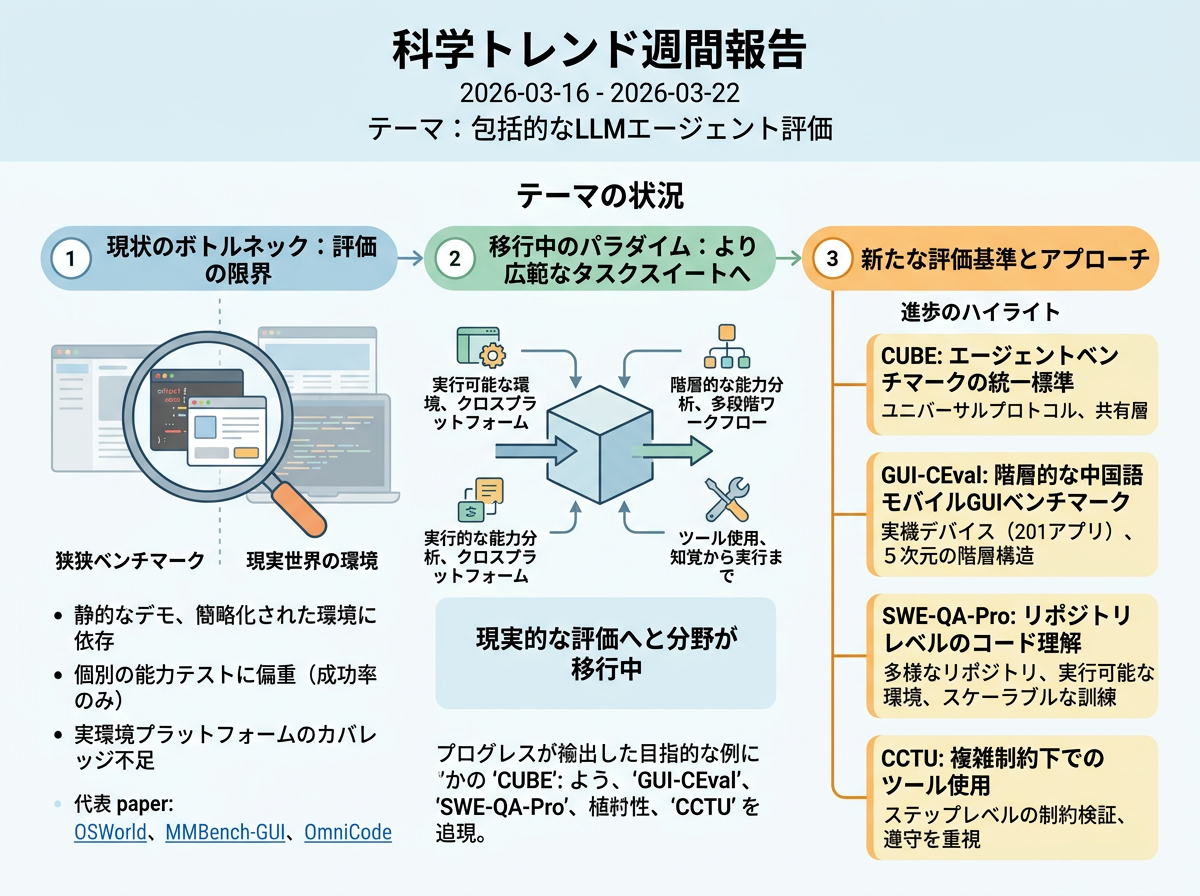
近年の論文は、評価がエージェント研究の進展における主要なボトルネックであると指摘している。OSWorldは、多くのマルチモーダルエージェントベンチマークが静的なデモンストレーションや簡略化された環境に依存しており、GUIとCLIインターフェース、複数のアプリケーション、主要オペレーティングシステムにまたがるオープンエンドなコンピュータ操作を捉えきれないと論じている。MMBench-GUIもGUIエージェントについて同様の指摘を行い、現行のベンチマークは個別の能力テストに偏り、主に成功率に焦点を当て、実環境プラットフォームや操作効率のカバレッジが不足していると述べている。
OmniCodeはこの批判をソフトウェアエンジニアリングに拡張し、一般的なコーディングベンチマークがパッチ生成などの個別タスクに過度に集中しており、実際の開発における多様な作業を反映していないと指摘している。これらの指摘を総合すると、実行可能な環境、クロスプラットフォーム対応、階層的な能力分析、効率性を考慮した指標、マルチステップ・マルチツールのワークフローを包含するより広範なタスクスイートを通じて、より現実的な評価へと分野が移行しつつあることが示されている。
- OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
- MMBench-GUI: Hierarchical Multi-Platform Evaluation Framework for GUI Agents
- OmniCode: A Benchmark for Evaluating Software Engineering Agents
インフォグラフィクス(日本語)
今週の進展
CUBE: A Standard for Unifying Agent Benchmarks <See Details on Fugu-MT>
CUBEは、評価・RL訓練・データ生成のためにエージェントベンチマークへのアクセスを統一するユニバーサルプロトコル標準を提案している。 従来の独立型ベンチマークとは異なり、共有プロトコル層を追加することで、準拠するプラットフォームがカスタム統合なしに任意の準拠ベンチマークを利用可能にしている。
GUI-CEval: A Hierarchical and Comprehensive Chinese Benchmark for Mobile GUI Agents <See Details on Fugu-MT>
GUI-CEvalは、4種類の実機デバイスと201の主要アプリを対象とした中国語モバイルGUIベンチマークを導入している。 従来のGUIベンチマークと比較して、実デバイスでのカバレッジと、原子的能力からアプリレベルのタスクに至る5次元の階層構造を追加している。
SWE-QA-Pro: A Representative Benchmark and Scalable Training Recipe for Repository-Level Code Understanding <See Details on Fugu-MT>
SWE-QA-Proは、多様なリポジトリと実行可能な環境に基づくリポジトリレベルのコード理解ベンチマークを提供している。 より狭いコーディングベンチマークと比較して、ソフトウェアエンジニアリング評価をリポジトリ規模の理解へと移行させ、スケーラブルな訓練手法と組み合わせている。
CCTU: A Benchmark for Tool Use under Complex Constraints <See Details on Fugu-MT>
CCTUは、200件の精選テストケースと実行可能なステップレベルの制約検証により、複雑な制約下でのLLMツール使用を評価している。 最終的なタスク成功に焦点を当てたベンチマークと比較して、ツール使用ワークフロー中の制約遵守とステップごとの検証を重視している。
今後の展望
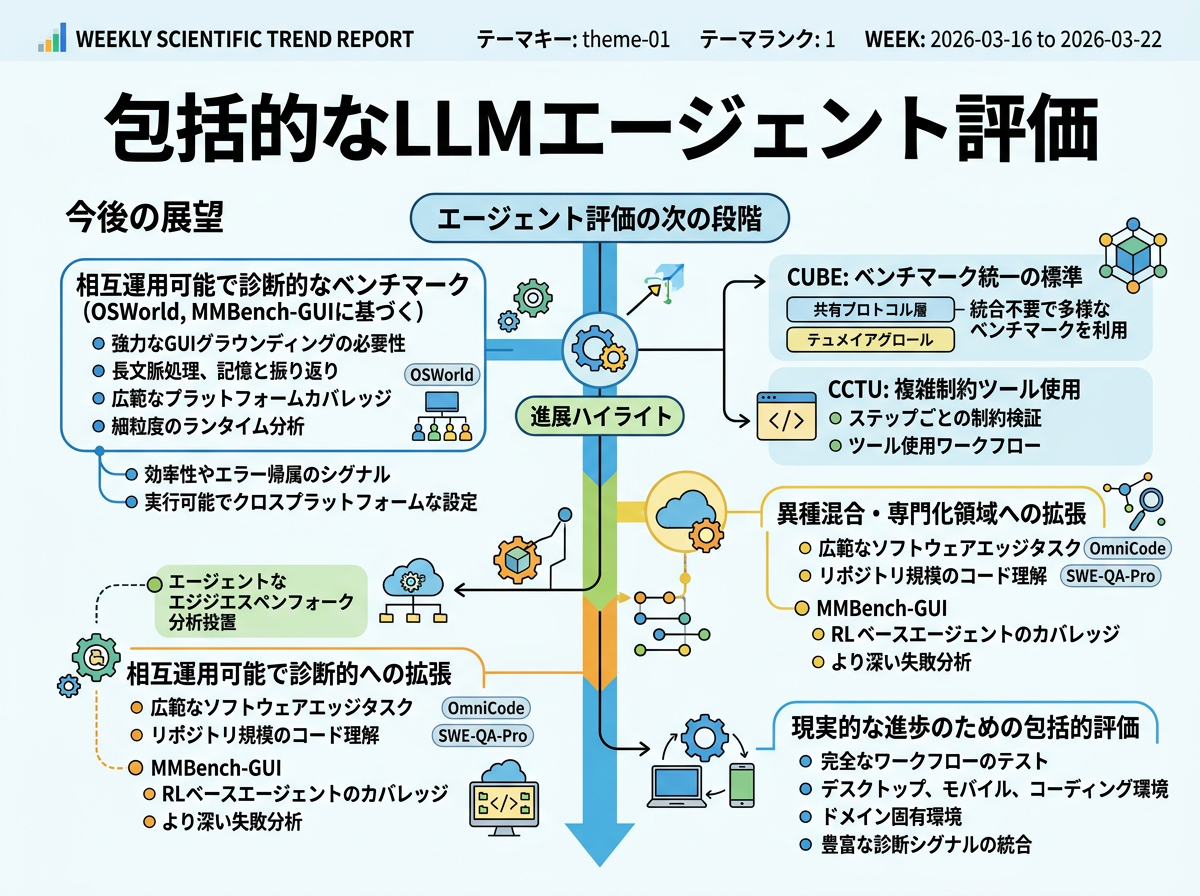
エージェント評価の次の段階は、より相互運用可能で診断的なベンチマークエコシステムへの移行が見込まれる。OSWorldとMMBench-GUIは、より強力なGUIグラウンディング、長文脈処理、記憶と振り返りのメカニズム、より広範なプラットフォームカバレッジ、およびより細粒度のランタイム分析の必要性を訴えている。今週の進展はこの方向性と一致しており、CUBEはベンチマーク相互運用のための共有プロトコル層を提供し、GUI-CEvalは実デバイスGUIカバレッジを拡張し、CCTUはステップレベルの制約検証を追加している。近い将来の評価は、タスク成功に加えて効率性やエラー帰属のシグナルを備えた、実行可能でクロスプラットフォームな設定を重視する方向に進むと考えられる。
もう一つの方向性は、より異種混合で専門化された領域への拡張である。OmniCodeは、セキュリティ修正などの追加カテゴリや言語を網羅する、より広範なソフトウェアエンジニアリングタスクスイートの必要性を主張し、SWE-QA-Proはリポジトリ規模のコード理解への評価拡張を行っている。MMBench-GUIはさらに、RLベースのエージェントを含むより広いモデルカバレッジと、より深い失敗分析を今後の課題として挙げている。このように、本分野はデスクトップ、モバイル、コーディング、ドメイン固有の環境にまたがる完全なワークフローをテストし、現実的な進歩を追跡するための基盤としてより豊富な診断シグナルを備えたベンチマークへと収斂しつつある。
インフォグラフィクス(日本語)
参照論文
- OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments - 著者: Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, Tao Yu, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- MMBench-GUI: Hierarchical Multi-Platform Evaluation Framework for GUI Agents - 著者: Xuehui Wang, Zhenyu Wu, JingJing Xie, Zichen Ding, Bowen Yang, Zehao Li, Zhaoyang Liu, Qingyun Li, Xuan Dong, Zhe Chen, Weiyun Wang, Xiangyu Zhao, Jixuan Chen, Haodong Duan, Tianbao Xie, Chenyu Yang, Shiqian Su, Yue Yu, Yuan Huang, Yiqian Liu, Xiao Zhang, Yanting Zhang, Xiangyu Yue, Weijie Su, Xizhou Zhu, Wei Shen, Jifeng Dai, Wenhai Wang, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- OmniCode: A Benchmark for Evaluating Software Engineering Agents - 著者: Atharv Sonwane, Eng-Shen Tu, Wei-Chung Lu, Claas Beger, Carter Larsen, Debjit Dhar, Rachel Chen, Ronit Pattanayak, Tuan Anh Dang, Guohao Chen, Gloria Geng, Kevin Ellis, Saikat Dutta, / <See Details on Fugu-MT> / ライセンス: CC-BY-SA-4.0