Summary
This week's evaluation work pushes beyond narrow benchmark settings toward broader tests for LLM- and VLM-based agents. Across computer-use, GUI, and software-engineering domains, representative papers argue that progress now depends on benchmarks that better reflect real environments, heterogeneous tasks, and the full chain from perception and grounding to multi-step execution.
Situation
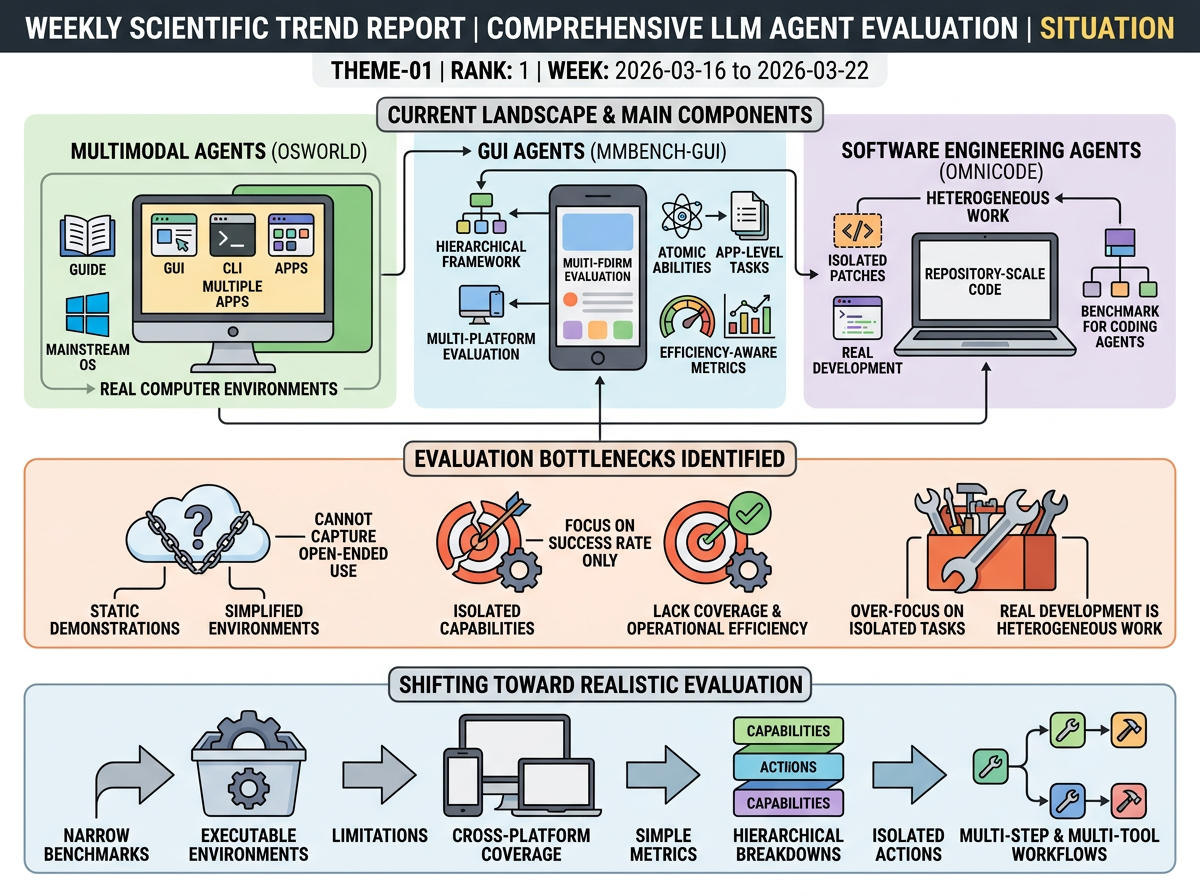
Recent papers identify evaluation as a major bottleneck for agent progress. OSWorld argues that many multimodal-agent benchmarks rely on static demonstrations or simplified environments, which cannot capture open-ended computer use across GUI and CLI interfaces, multiple applications, and mainstream operating systems. MMBench-GUI makes a similar case for GUI agents, noting that current benchmarks often test isolated capabilities, focus mainly on success rate, and lack coverage of real-world platforms and operational efficiency.
OmniCode extends this critique to software engineering, where common coding benchmarks over-focus on isolated tasks such as patch generation instead of the heterogeneous work of real development. Together, these introductions point to a field shifting toward more realistic evaluation through executable environments, cross-platform coverage, hierarchical capability breakdowns, efficiency-aware metrics, and broader task suites spanning multi-step and multi-tool workflows.
Infographic (English)
Progress
CUBE: A Standard for Unifying Agent Benchmarks <See Details on Fugu-MT>
CUBE proposes a universal protocol standard that unifies access to agent benchmarks for evaluation, RL training, and data generation. Unlike earlier standalone benchmarks, it adds a shared protocol layer so compliant platforms can use any compliant benchmark without custom integration.
GUI-CEval: A Hierarchical and Comprehensive Chinese Benchmark for Mobile GUI Agents <See Details on Fugu-MT>
GUI-CEval introduces a Chinese mobile GUI benchmark built on physical devices across four device types and 201 mainstream apps. Compared with prior GUI benchmarks, it adds real-device coverage and a hierarchical five-dimension structure spanning atomic abilities to app-level tasks.
SWE-QA-Pro: A Representative Benchmark and Scalable Training Recipe for Repository-Level Code Understanding <See Details on Fugu-MT>
SWE-QA-Pro provides a benchmark for repository-level code understanding built from diverse repositories with executable environments. Compared with narrower coding benchmarks, it shifts software-engineering evaluation toward repository-scale understanding and pairs it with a scalable training recipe.
CCTU: A Benchmark for Tool Use under Complex Constraints <See Details on Fugu-MT>
CCTU evaluates LLM tool use under complex constraints with 200 curated test cases and executable step-level constraint verification. Compared with benchmarks centered on final task success, it emphasizes constraint compliance and stepwise checking during tool-using workflows.
Outlook
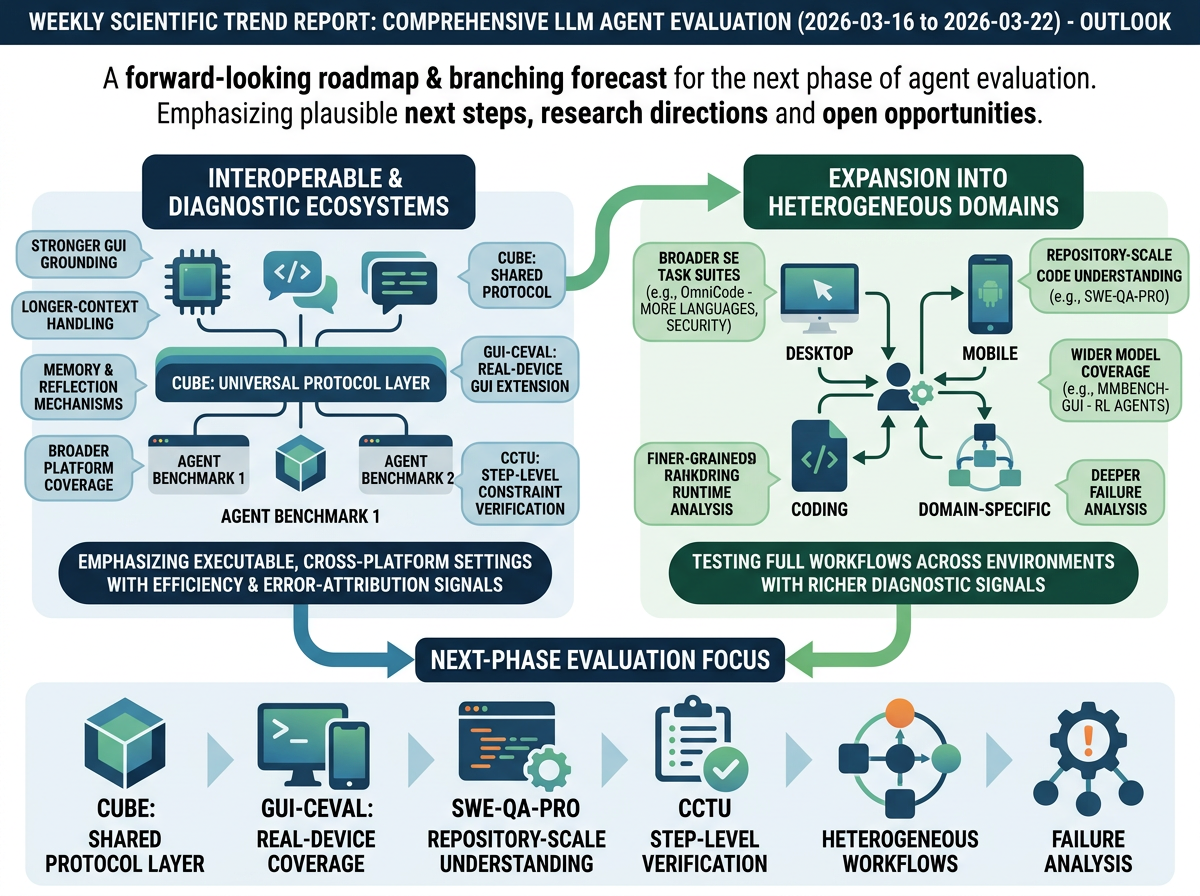
The next phase of agent evaluation is likely to move toward more interoperable and diagnostic benchmark ecosystems. OSWorld and MMBench-GUI call for stronger GUI grounding, longer-context handling, memory and reflection mechanisms, broader platform coverage, and finer-grained runtime analysis. This week's progress aligns with that trajectory: CUBE offers a shared protocol layer for benchmark interoperability, GUI-CEval extends real-device GUI coverage, and CCTU adds step-level constraint verification. Near-term evaluation appears poised to emphasize executable, cross-platform settings with efficiency and error-attribution signals alongside task success.
A second direction is expansion into more heterogeneous and specialized domains. OmniCode argues for broader software-engineering task suites covering additional languages and categories such as security fixing, while SWE-QA-Pro extends evaluation to repository-scale code understanding. MMBench-GUI further notes that future work should include wider model coverage—including RL-based agents—and deeper failure analysis. The field is thus converging on benchmarks that test full workflows across desktop, mobile, coding, and domain-specific environments, with richer diagnostic signals as a basis for tracking realistic progress.
Infographic (English)
References
- OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments - Authors: Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, Tao Yu, / <See Details on Fugu-MT> / License: CC-BY-4.0
- MMBench-GUI: Hierarchical Multi-Platform Evaluation Framework for GUI Agents - Authors: Xuehui Wang, Zhenyu Wu, JingJing Xie, Zichen Ding, Bowen Yang, Zehao Li, Zhaoyang Liu, Qingyun Li, Xuan Dong, Zhe Chen, Weiyun Wang, Xiangyu Zhao, Jixuan Chen, Haodong Duan, Tianbao Xie, Chenyu Yang, Shiqian Su, Yue Yu, Yuan Huang, Yiqian Liu, Xiao Zhang, Yanting Zhang, Xiangyu Yue, Weijie Su, Xizhou Zhu, Wei Shen, Jifeng Dai, Wenhai Wang, / <See Details on Fugu-MT> / License: CC-BY-4.0
- OmniCode: A Benchmark for Evaluating Software Engineering Agents - Authors: Atharv Sonwane, Eng-Shen Tu, Wei-Chung Lu, Claas Beger, Carter Larsen, Debjit Dhar, Rachel Chen, Ronit Pattanayak, Tuan Anh Dang, Guohao Chen, Gloria Geng, Kevin Ellis, Saikat Dutta, / <See Details on Fugu-MT> / License: CC-BY-SA-4.0