サマリー
今週の論文は、マルチモーダル基盤モデルの幅広い汎用性を犠牲にせず、いかに効率化するかに焦点を当てている。一般的なビジョン・言語タスクおよび科学的応用の両面において、クロスモーダル処理をどの段階で行うべきか、事前学習済みのビジョン・言語知識をどう再利用できるか、そしてコンパクトな適応で高い下流タスク性能を維持できるかが再検討されている。
テーマの状況
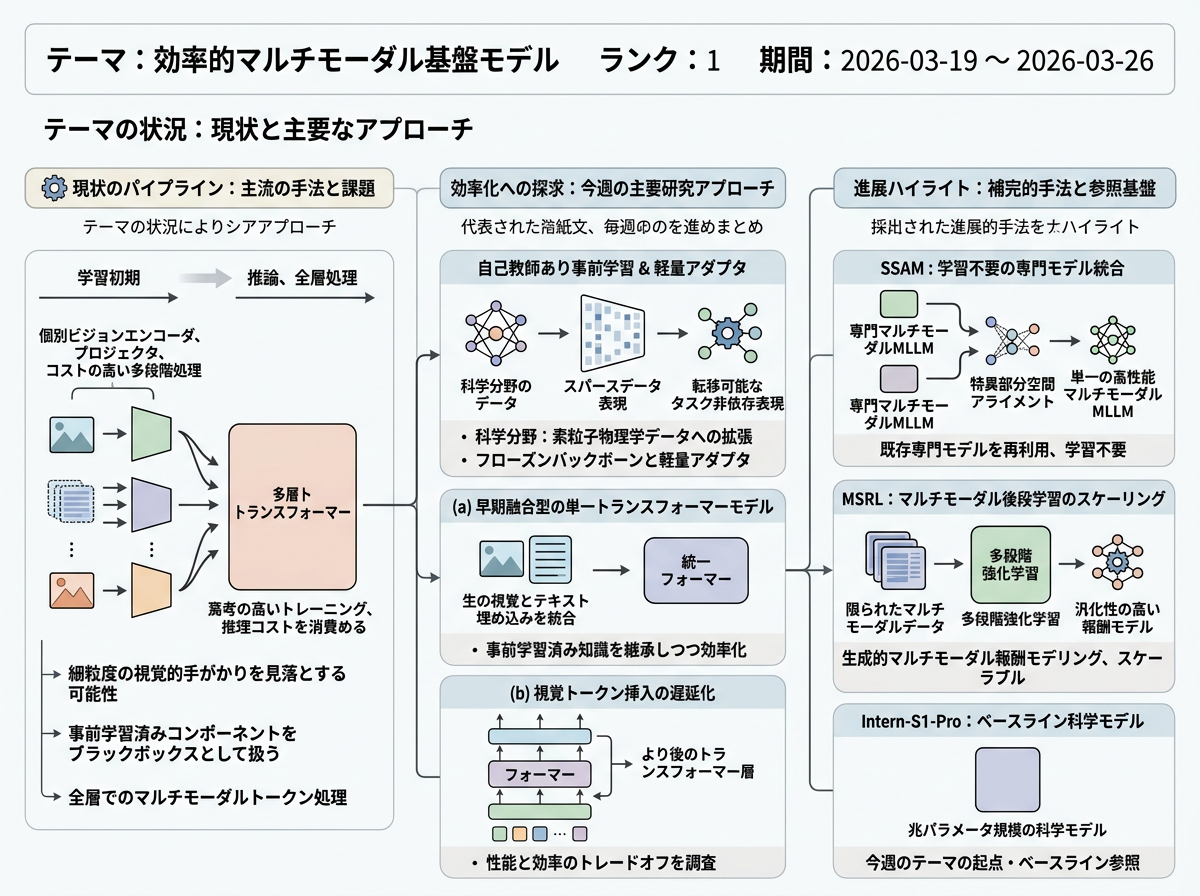
大規模言語モデルはマルチモーダルシステムの開発を加速させてきたが、多くのオープンソースのビジョン・言語モデルは依然として個別のビジョンエンコーダ、プロジェクタ、そしてコストの高い多段階処理に依存している。代表的な論文群は共通の課題を提起している。すなわち、現行のパイプラインは細粒度の視覚的手がかりを見落とす可能性があり、事前学習済みコンポーネントをブラックボックスとして扱い、マルチモーダルトークンをモデルの全層で処理する際に多大な学習・推論コストを課すという問題である。
これに対し、今週の代表的な研究はより経済的なマルチモーダル設計を探求している。ある論文は、事前学習済みのビジョンモデルと言語モデルの知識を継承しつつ、生の視覚埋め込みとテキスト埋め込みを統合する早期融合型の単一トランスフォーマーモデルを提案している。別の論文は、マルチモーダルトークン処理にトランスフォーマーのどの層が実際に必要かを調査し、視覚トークンの挿入をより後の層に移すことで性能と効率のトレードオフを明らかにしている。また、科学分野の研究は同様の基盤モデルの論理をスパースな素粒子物理学の検出器データに拡張し、自己教師あり事前学習がフローズンバックボーンと軽量アダプタを通じて転移可能なタスク非依存の表現を生成できるかを検証している。
- HaploVL: A Single-Transformer Baseline for Multi-Modal Understanding
- Platonic Grounding for Efficient Multimodal Language Models
- FM4NPP: A Scaling Foundation Model for Nuclear and Particle Physics
インフォグラフィクス(日本語)
今週の進展
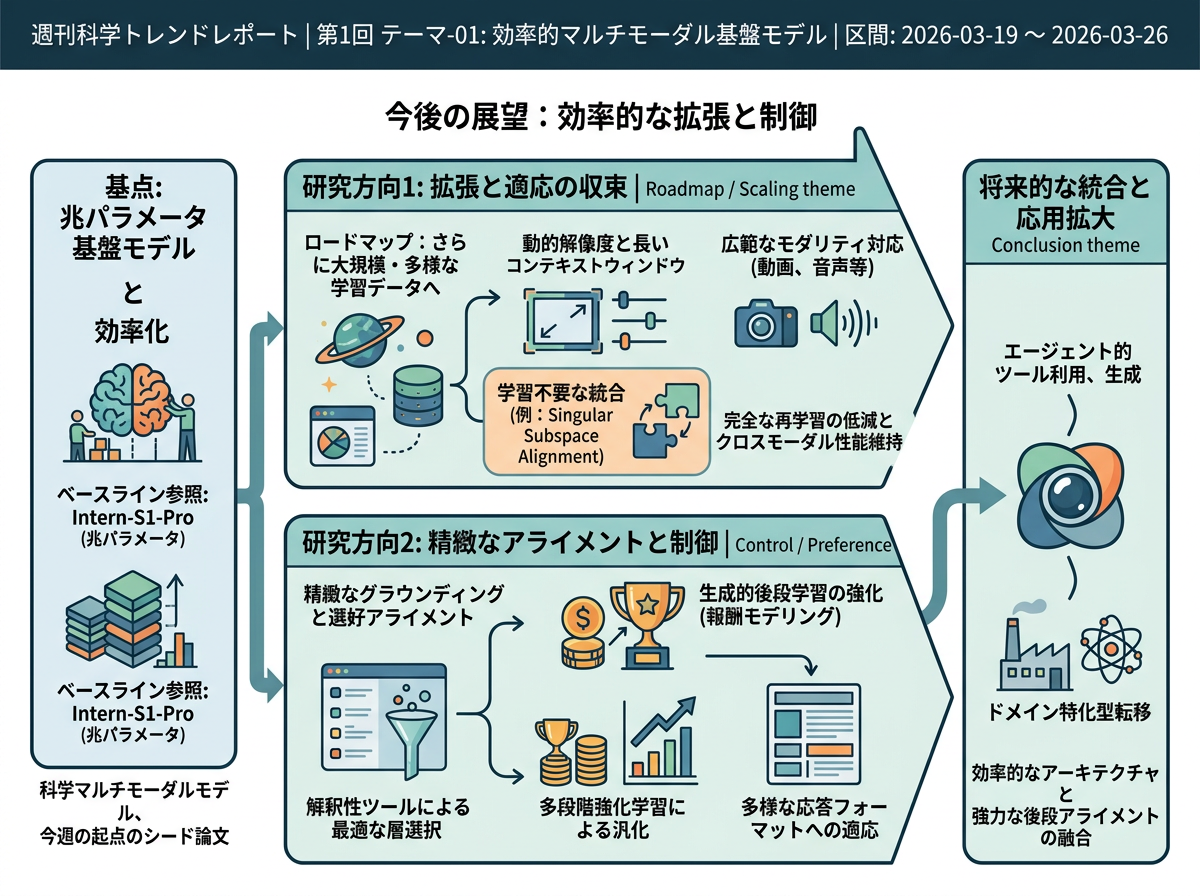
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale <See Details on Fugu-MT>
Intern-S1-Pro:兆パラメータ規模の科学マルチモーダル基盤モデルであり、今週のテーマの起点となるシード論文である。 今週の進展を解釈するためのベースライン参照として位置づけられる。
SSAM: Singular Subspace Alignment for Merging Multimodal Large Language Models <See Details on Fugu-MT>
SSAMは、個別に学習されたマルチモーダル専門モデルを特異部分空間アライメントにより単一モデルに統合する、学習不要の手法を導入した。 単一アーキテクチャ内でマルチモーダルコストを削減する従来手法とは異なり、SSAMはマルチモーダル学習データを一切使わずに既存の専門モデルを再利用し、複合的な入力モダリティを処理する。
MSRL: Scaling Generative Multimodal Reward Modeling via Multi-Stage Reinforcement Learning <See Details on Fugu-MT>
MSRLは効率化のテーマをアーキテクチャ設計からスケーラブルなマルチモーダル後段学習に拡張し、限られたマルチモーダルデータの下で報酬モデルに多段階強化学習を適用した。 従来のRLVRベースの学習と比較して、より汎化性の高い報酬推論能力を獲得し、生成的マルチモーダル報酬モデリングをより効果的にスケールさせる。
今後の展望
近い将来の方向性としては、効率的なマルチモーダルアーキテクチャ設計とスケーリングを考慮した適応の収束が有力である。代表的な論文群は、より大規模で多様な学習データ、より長いコンテキストウィンドウ、動的解像度、そしてより広範なモダリティ対応(例:動画や音声)を指し示している。今週の進展は、単一モデルの効率化を超えて、マルチモーダル専門モデルの学習不要な統合やよりスケーラブルなマルチモーダル後段学習へとテーマを拡張することで、この方向性を補強している。今後の研究は、完全なエンドツーエンドのマルチモーダル再学習の必要性を低減しつつ、強力なクロスモーダル性能を維持することを目指すと考えられる。
もう一つの有力な方向性は、マルチモーダルのグラウンディングとアライメントがどこで・どのように行われるかに対するより精緻な制御である。代表的な論文の今後の課題セクションでは、解釈性ツールによる最適なグラウンディング層の選択、応答フォーマットの多様化、選好アライメント手法の適用が挙げられている。今週のスケーラブルな報酬モデリングへの動きはこの方向性を支持するものであり、効率的なマルチモーダルシステムは、コンパクトなアーキテクチャ的グラウンディングとより強力な後段学習アライメントを組み合わせた上で、エージェント的ツール利用、生成、ドメイン特化型転移へと拡大していく可能性がある。
インフォグラフィクス(日本語)
参照論文
- HaploVL: A Single-Transformer Baseline for Multi-Modal Understanding - 著者: Rui Yang, Lin Song, Yicheng Xiao, Runhui Huang, Yixiao Ge, Ying Shan, Hengshuang Zhao, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- Platonic Grounding for Efficient Multimodal Language Models - 著者: Moulik Choraria, Xinbo Wu, Akhil Bhimaraju, Nitesh Sekhar, Yue Wu, Xu Zhang, Prateek Singhal, Lav R. Varshney, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- FM4NPP: A Scaling Foundation Model for Nuclear and Particle Physics - 著者: David Park, Shuhang Li, Yi Huang, Xihaier Luo, Haiwang Yu, Yeonju Go, Christopher Pinkenburg, Yuewei Lin, Shinjae Yoo, Joseph Osborn, Jin Huang, Yihui Ren, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0