Summary
This week's papers focus on making multimodal foundation models more efficient without sacrificing broad utility. Across general vision-language and scientific settings, they revisit where cross-modal processing should happen, how pretrained vision and language knowledge can be reused, and whether compact adaptation can preserve strong downstream performance.
Situation
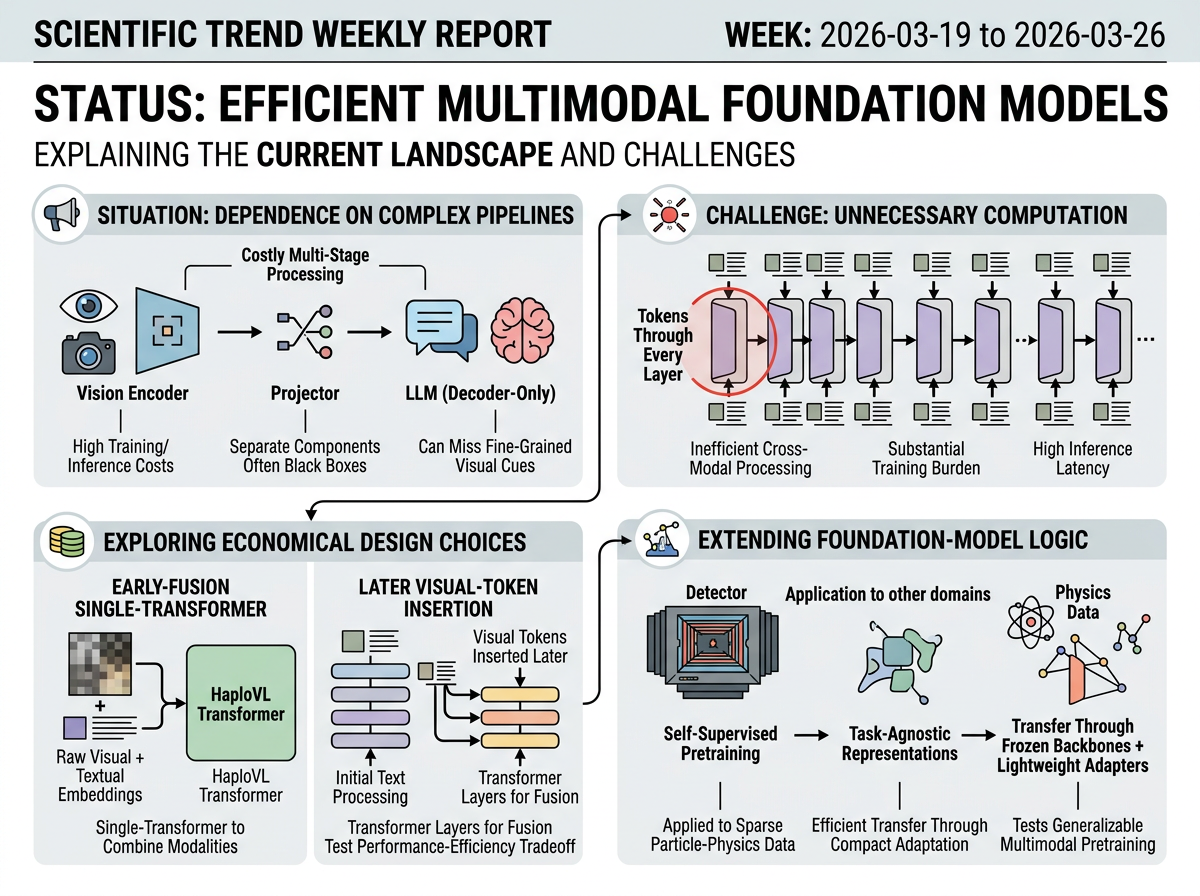
Large language models have accelerated the development of multimodal systems, but many open-source vision-language models still depend on separate vision encoders, projectors, and costly multi-stage processing. The representative papers frame a shared concern: current pipelines can miss fine-grained visual cues, treat pretrained components as black boxes, and impose substantial training or inference costs when multimodal tokens are processed through every layer of the model.
In response, this week's representative work explores more economical multimodal design choices. One paper proposes an early-fusion single-transformer model that combines raw visual and textual embeddings while inheriting prior knowledge from pretrained vision and language models. Another investigates which transformer layers are actually necessary for multimodal token processing and shifts visual-token insertion to later layers to expose a performance-efficiency tradeoff. A scientific-domain study extends the same foundation-model logic to sparse particle-physics detector data, testing whether self-supervised pretraining can produce task-agnostic representations that transfer through frozen backbones and lightweight adapters.
Infographic (English)
Progress
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale <See Details on Fugu-MT>
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale is the seed paper anchoring this week's theme. It remains the baseline reference for interpreting this week's progress.
SSAM: Singular Subspace Alignment for Merging Multimodal Large Language Models <See Details on Fugu-MT>
SSAM introduces a training-free method to merge separately trained multimodal experts into a single model via singular-subspace alignment. Unlike prior work that reduced multimodal cost within a single architecture, SSAM reuses existing specialist models without any multimodal training data to handle combined input modalities.
MSRL: Scaling Generative Multimodal Reward Modeling via Multi-Stage Reinforcement Learning <See Details on Fugu-MT>
MSRL extends the efficiency theme from architecture design to scalable multimodal post-training, applying multi-stage reinforcement learning to reward models under limited multimodal data. Compared with prior RLVR-based training, it learns more generalizable reward-inference capabilities and scales generative multimodal reward modeling more effectively.
Outlook
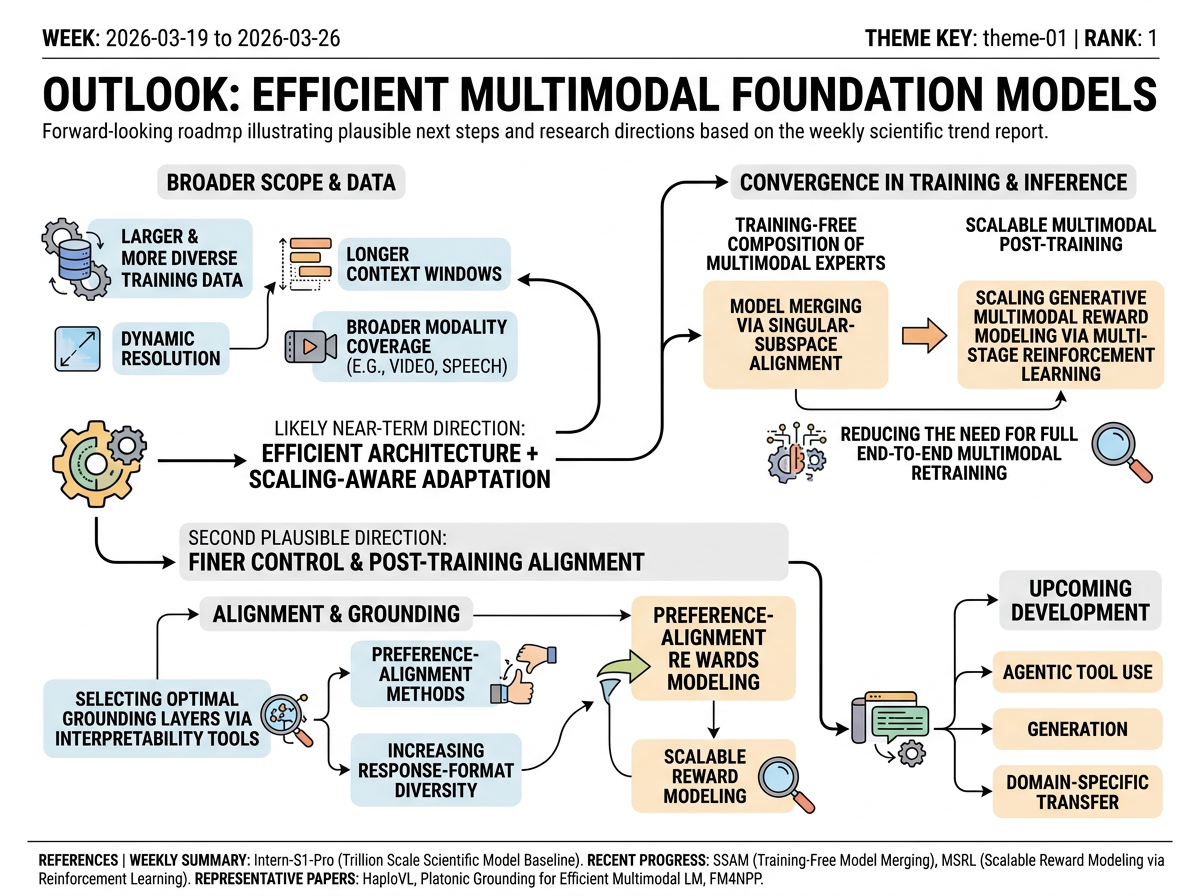
A likely near-term direction is convergence between efficient multimodal architecture design and scaling-aware adaptation. The representative papers point to larger and more diverse training data, longer context windows, dynamic resolution, and broader modality coverage (e.g., video and speech). This week's progress reinforces that trajectory by extending the theme beyond single-model efficiency to training-free composition of multimodal experts and more scalable multimodal post-training, suggesting that upcoming work will aim to preserve strong cross-modal performance while reducing the need for full end-to-end multimodal retraining.
A second plausible direction is finer control over where and how multimodal grounding and alignment occur. Future-work sections in the representative papers highlight selecting optimal grounding layers via interpretability tools, increasing response-format diversity, and applying preference-alignment methods. This week's movement toward scalable reward modeling supports that trajectory: efficient multimodal systems may increasingly pair compact architectural grounding with stronger post-training alignment, before expanding into agentic tool use, generation, and domain-specific transfer.
Infographic (English)
References
- HaploVL: A Single-Transformer Baseline for Multi-Modal Understanding - Authors: Rui Yang, Lin Song, Yicheng Xiao, Runhui Huang, Yixiao Ge, Ying Shan, Hengshuang Zhao, / <See Details on Fugu-MT> / License: CC-BY-4.0
- Platonic Grounding for Efficient Multimodal Language Models - Authors: Moulik Choraria, Xinbo Wu, Akhil Bhimaraju, Nitesh Sekhar, Yue Wu, Xu Zhang, Prateek Singhal, Lav R. Varshney, / <See Details on Fugu-MT> / License: CC-BY-4.0
- FM4NPP: A Scaling Foundation Model for Nuclear and Particle Physics - Authors: David Park, Shuhang Li, Yi Huang, Xihaier Luo, Haiwang Yu, Yeonju Go, Christopher Pinkenburg, Yuewei Lin, Shinjae Yoo, Joseph Osborn, Jin Huang, Yihui Ren, / <See Details on Fugu-MT> / License: CC-BY-4.0