Summary
This week's theme concerns adapting and evaluating speech models when labeled in-domain data are scarce, domains shift, or speech departs from typical patterns. The representative papers span dysarthria severity assessment, low-resource ASR domain adaptation, and dysfluency detection, each emphasizing self-supervised representations or synthetic data generation to improve modeling under limited supervision.
Situation
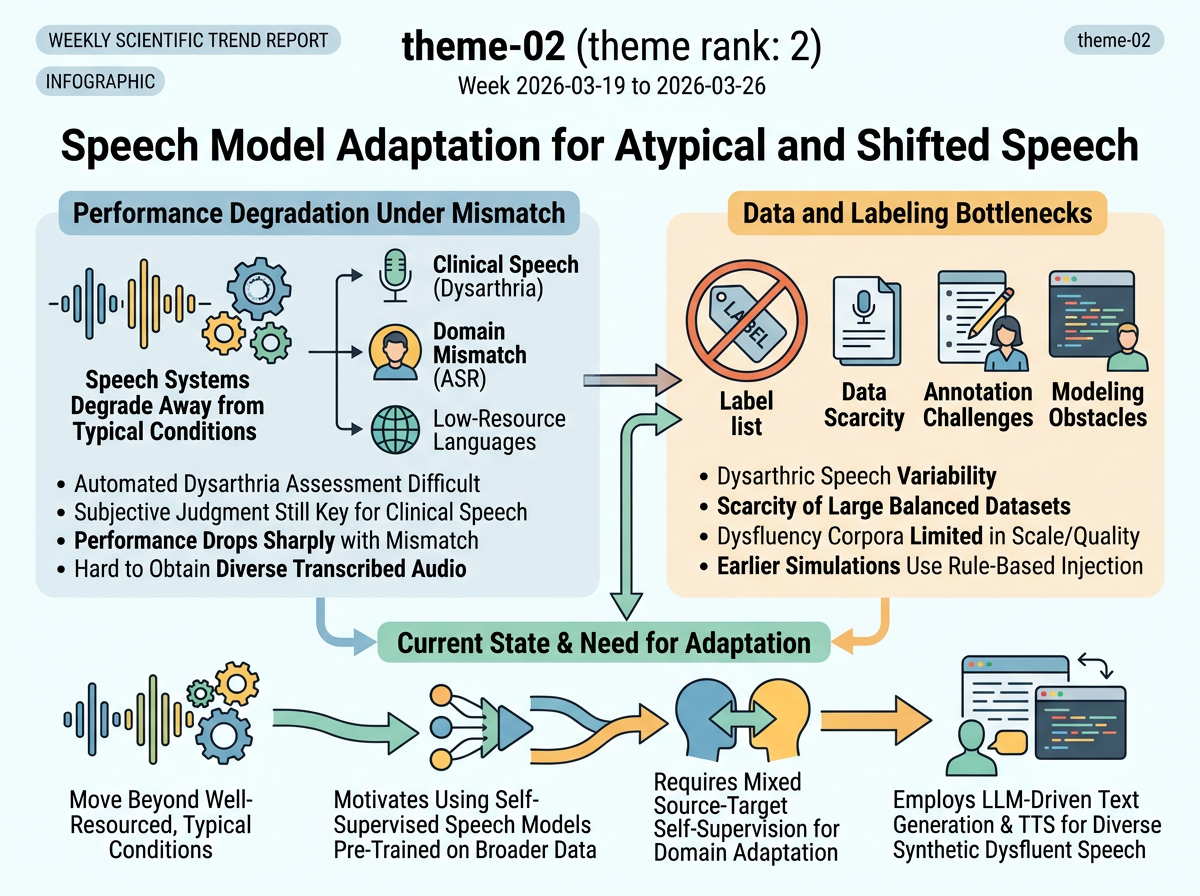
Speech systems often degrade when they move away from well-resourced, typical speech conditions. In clinical speech, dysarthria assessment still relies heavily on subjective auditory-perceptual judgment, while the variability of dysarthric speech and the scarcity of large balanced datasets make automated assessment difficult. In ASR more broadly, performance drops sharply under domain mismatch, especially for low-resource languages where diverse transcribed audio is hard to obtain.
Data and labeling bottlenecks are central obstacles for reliable model development and evaluation across these settings. Existing dysfluency corpora are limited in scale or annotation quality, and earlier simulation pipelines use rule-based dysfluency injection that may not reflect natural patterns. Against this background, the representative papers motivate using self-supervised speech models pre-trained on broader data, mixed source-target self-supervision for domain adaptation, and LLM-driven text generation paired with TTS to produce more diverse synthetic dysfluent speech for downstream detection.
Infographic (English)
Progress
Adapting Self-Supervised Speech Representations for Cross-lingual Dysarthria Detection in Parkinson's Disease <See Details on Fugu-MT>
Proposes representation-level language-shift alignment to adapt self-supervised speech features for cross-lingual dysarthria detection in Parkinson's disease. Whereas prior work focused on within-language or within-domain adaptation, this directly addresses language mismatch between source representations and target Parkinsonian speech across Czech, German, and Spanish.
Demonstration of Adapt4Me: An Uncertainty-Aware Authoring Environment for Personalizing Automatic Speech Recognition to Non-normative Speech <See Details on Fugu-MT>
Presents Adapt4Me, an uncertainty-aware human-in-the-loop environment for personalizing ASR to non-normative speech without expert supervision. Compared with the prior emphasis on model-side adaptation strategies, this adds a practical authoring workflow combining Bayesian active learning with user-driven data selection and validation.
Outlook
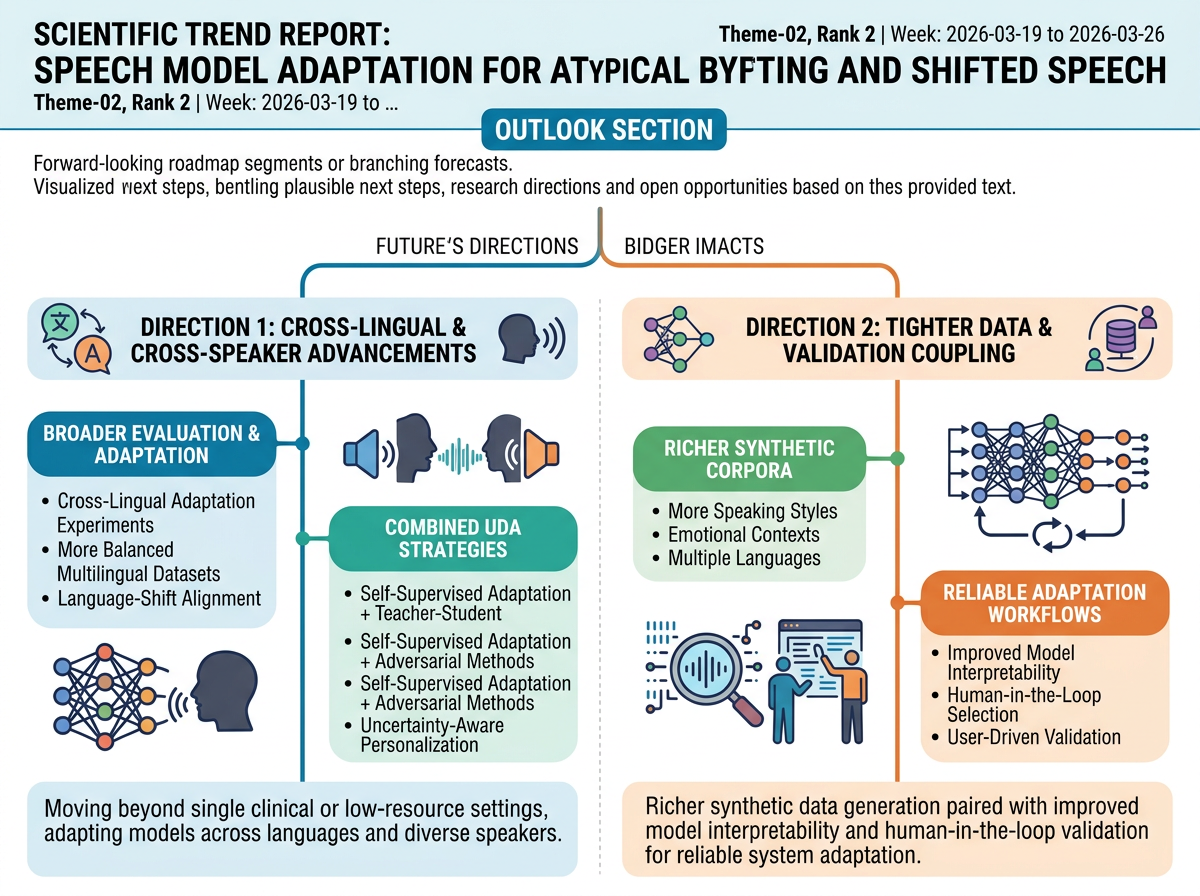
The most likely near-term direction is broader cross-lingual and cross-speaker evaluation and adaptation, moving beyond single clinical or low-resource settings. The representative papers call for more balanced multilingual datasets, cross-lingual adaptation experiments, and combinations of self-supervised adaptation with other UDA strategies such as teacher-student or adversarial methods. This week's progress reinforces that trajectory with new work on language-shift alignment for dysarthric speech and uncertainty-aware personalization for non-normative ASR.
A second direction is tighter coupling between data generation, adaptation, and validation. Future-work sections point to richer synthetic corpora covering more speaking styles, emotional contexts, and languages, alongside improved model interpretability. The weekly progress suggests these data-side advances will increasingly be paired with human-in-the-loop selection and validation workflows, helping systems be adapted more reliably when expert labels remain scarce.
Infographic (English)
References
- Sample-Efficient Unsupervised Domain Adaptation of Speech Recognition Systems A case study for Modern Greek - Authors: Georgios Paraskevopoulos, Theodoros Kouzelis, Georgios Rouvalis, Athanasios Katsamanis, Vassilis Katsouros, Alexandros Potamianos / <See Details on Fugu-MT> / License: CC-BY-4.0
- Speaker-Independent Dysarthria Severity Classification using Self-Supervised Transformers and Multi-Task Learning - Authors: Lauren Stumpf and Balasundaram Kadirvelu and Sigourney Waibel and A. Aldo Faisal / <See Details on Fugu-MT> / License: CC-BY-4.0
- Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection - Authors: Jinming Zhang, Xuanru Zhou, Jiachen Lian, Shuhe Li, William Li, Zoe Ezzes, Rian Bogley, Lisa Wauters, Zachary Miller, Jet Vonk, Brittany Morin, Maria Gorno-Tempini, Gopala Anumanchipalli, / <See Details on Fugu-MT> / License: CC-BY-4.0