サマリー
今週の進展は、拡散モデルが画像から動画・音声へと拡張される中で、マルチメディア生成の時間的一貫性と制御性の向上に焦点を当てている。主な未解決課題として、画像拡散モデルをフレームごとに適用した際の動画のちらつき、およびテキストから音声への生成システムにおけるイベントタイミングの細粒度制御の限界が繰り返し挙げられている。今週の新たな研究は、フローマッチングによるダビング、統合的なマルチモーダル動画→音声条件付け、および蒸留された自己回帰拡散トランスフォーマーによるストリーミング動画スタイライゼーションを通じて、これらの課題に取り組んでいる。
テーマの状況
拡散モデルは画像合成における主要な生成フレームワークとなっており、現在は動画と音声への拡張が活発に進められている。動画においては、画像拡散モデルをフレームごとに独立して適用すると目に見えるちらつきが発生するため、既存の画像パイプラインを最小限の再学習で一貫性のある動画に転用する手法が求められている。音声においては、テキストから音声への生成は急速に進歩しているが、音声イベントの発生タイミングや複数イベント間の時間的関係をより細かく制御するという重要なニーズが未解決であり、時間的依存関係をより明示的にエンコードする構造化されたガイダンス機構が求められている。
それと並行して、アシスタント、チャットボット、カスタマーサービスにおける音声アプリケーションは、方言の変異、発音の違い、日常的な非流暢性といった課題に直面している。これらの課題は、音声から音声への非流暢性修正などの統合的な後処理ツールの必要性を動機づけており、音声メディアおよび生成メディア全般にわたる時間的に意識された処理への幅広い需要を浮き彫りにしている。
- DisfluencyFixer: A tool to enhance Language Learning through Speech To Speech Disfluency Correction
- DiffSynth: Latent In-Iteration Deflickering for Realistic Video Synthesis
- DegDiT: Controllable Audio Generation with Dynamic Event Graph Guided Diffusion Transformer
インフォグラフィクス(日本語)

今週の進展
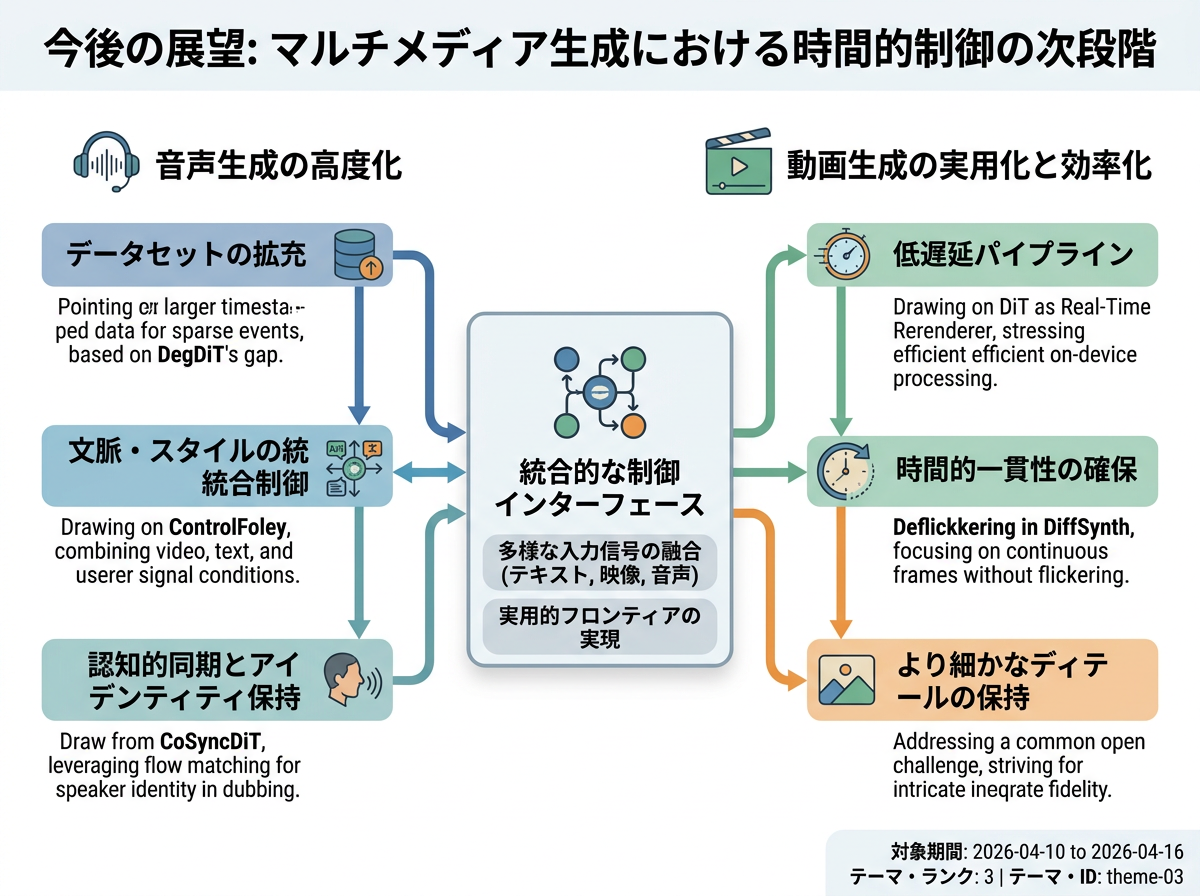
CoSyncDiT: Cognitive Synchronous Diffusion Transformer for Movie Dubbing <See Details on Fugu-MT>
生成された音声を唇の動きに同期させつつ話者のアイデンティティを保持する、フローマッチングに基づく映画ダビングフレームワークを提案。 従来のダビング手法で用いられていた明示的な持続時間レベルのアライメントを、認知的同期拡散トランスフォーマーに置き換えることで、より自然な同期を実現。
ControlFoley: Unified and Controllable Video-to-Audio Generation with Cross-Modal Conflict Handling <See Details on Fugu-MT>
動画・テキスト・参照音声を統合的に条件として音声合成を行う、統一的な動画→音声フレームワークを導入。 従来のV2A手法で問題となっていたテキスト制御性の弱さや視覚・テキスト間の矛盾に対処し、複数モダリティとスタイル制御を単一システムで処理。
DiT as Real-Time Rerenderer: Streaming Video Stylization with Autoregressive Diffusion Transformer <See Details on Fugu-MT>
リアルタイム使用向けに蒸留された自己回帰拡散トランスフォーマーに基づく、ストリーミング動画スタイライゼーションフレームワークを提示。 テキストガイドおよびリファレンスガイドの両モードで少ステップのリアルタイム再レンダリングを達成し、従来のオフライン専用動画スタイライゼーションパイプラインを超える進展を実現。
今後の展望
今後の展望(要約)
近い将来の研究は、時間的に制御された生成をより高速かつ実用的にすることに注力すると考えられる。これらの成果は、オフラインでの視覚品質向上のみに注力するのではなく、アイデンティティ・リップシンク・フレーム間一貫性を維持する低遅延で一貫性のある動画パイプラインへの関心の高まりを示唆している。
音声面では、代表的な制御可能音声生成論文が、稀なイベントをカバーするためのより大規模なタイムスタンプ付きデータセットの必要性を指摘している一方、今週のマルチモーダル動画→音声研究は、タイミングとスタイルの矛盾を統合的に解決するために動画・テキスト・参照信号を組み合わせることへの関心の高まりを示している。
インフォグラフィクス(日本語)
3年後を想定した動き
そうしたモジュール統合が定着するなら、その後およそ3年で研究は、イベントグラフ、アラインされた潜在タイムライン、クロスモーダル同期目的、そして一貫性・タイミング忠実度・編集可能性に関する標準化されたベンチマークといった、モダリティ横断の共有時間抽象を中心に組織化されていく可能性が高いが、そのために単一の万能アーキテクチャが支配的になる必要はない。同じ条件の下で、応用スタックはより明示的にタイムライン認識型になり、安定した動画生成、構造化された音声制御、日常的な発話クリーンアップや吹き替え支援が制作ツールチェーン内で連携するようになり、とくにクリエイターのワークフロー、多言語ローカライズ、スタイライズされたメディア制作、そして予測可能なタイミングが不可欠なインタラクティブ・コンテンツにおいて、その傾向が強まるだろう。
もしその評価シフトがおよそ3年にわたって維持されるなら、研究はますます時間を明示的に扱う目標を中心に据えるようになり、ハイブリッドなマルチモーダル・システムはコヒーレンス・モジュール、イベントグラフ条件付け、同期認識型損失を内部に組み込み、密なタイムスタンプ付きデータセットは本格的なベンチマーク公開では当たり前になっていく。その経路では、長尺での一貫性、希少イベントのタイミング、動画と音声のアラインメントが標準的なベンチマーク・トラックとなり、スケール偏重のシステムが優位を保ちにくくなる。応用では同じ論理により、吹替、クリエイティブ動画、語学指導、そして一部のアクセシビリティ志向スピーチ・ツールで、時間品質が運用実務の中に入り、QAダッシュボードや購買要件がフリッカー安定性、同期誤差、イベント・タイミング、残留する非流暢性を追跡し始める。それにより、より信頼できる本番吹替とスタイライズ、インタラクティブメディア向けのより制御しやすい音声生成、より洗練されたスピーチ・クリーンアップ機能が可能になるが、それでも最も強い採用は、消費者向け全般への普遍的展開ではなく、プレミアム製品やワークフロー上重要な製品に集中するだろう。
もし同じ経路が約3年にわたって強まり続ければ、研究は選好最適化、データフィルタリング、対象を絞ったファインチューニングを通じて時間的観測性をモデル開発に直接組み込み始め、同時にタイムライン構造の形式が、プロンプティング、評価、編集の間のより一般的なインターフェースになっていくはずだ。その経路では、計測済みパイプラインが日常運用の副産物として再利用可能な時間アノテーションを生成するため、不足しがちなタイムスタンプ付き学習データの問題の一部は緩和される。応用面での進展は、その場合、本番の吹替、発話クリーンアップ、スタイライズ、同期型メディアの各パイプラインで最も明確に現れ、時間ダッシュボードやQAゲートが、公開前にフリッカー、タイミングドリフト、同期失敗、残留する非流暢性を捕捉し、対話型ツールが即時の品質フィードバック付きでタイミング制御を提供するようになるだろう。このより強い36か月版であっても、アーキテクチャは依然として重要だが、より信頼される観測性スタックを持つプラットフォームは、主に主観的レビューに依存するチームよりも速く反復し、時間制御をより確実に運用へ載せられる。
参照論文
- DisfluencyFixer: A tool to enhance Language Learning through Speech To Speech Disfluency Correction - 著者: Vineet Bhat, Preethi Jyothi and Pushpak Bhattacharyya / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- DiffSynth: Latent In-Iteration Deflickering for Realistic Video Synthesis - 著者: Zhongjie Duan, Lizhou You, Chengyu Wang, Cen Chen, Ziheng Wu, Weining Qian, Jun Huang, Fei Chao, Rongrong Ji / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- DegDiT: Controllable Audio Generation with Dynamic Event Graph Guided Diffusion Transformer - 著者: Yisu Liu, Chenxing Li, Wanqian Zhang, Wenfu Wang, Meng Yu, Ruibo Fu, Zheng Lin, Weiping Wang, Dong Yu, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0