Summary
This week's progress centers on making diffusion-based multimedia generation more temporally coherent and controllable as these models expand from images into video and audio. The key recurring gaps are video flicker when image diffusion models are applied frame by frame and limited fine-grained event timing in text-to-audio systems. New work addresses these through flow-matching dubbing, unified multimodal video-to-audio conditioning, and streaming video stylization via distilled autoregressive diffusion transformers.
Situation
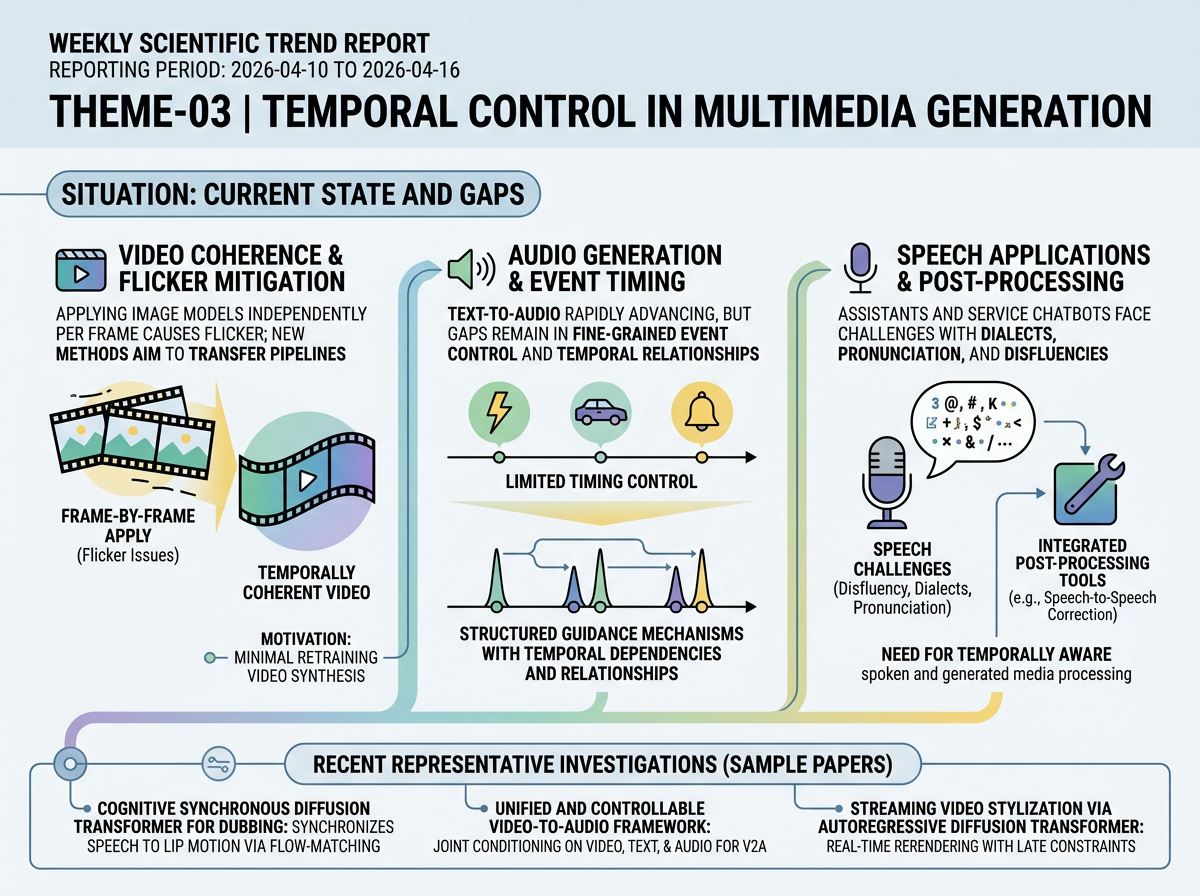
Diffusion models have become a dominant generative framework in image synthesis and are now being actively extended to video and audio. For video, applying image diffusion models independently per frame causes visible flicker, motivating methods that transfer existing image pipelines to coherent video with minimal retraining. For audio, text-to-audio generation has advanced rapidly, but the key unmet need is finer control over when sound events occur and how multiple events relate over time, prompting structured guidance mechanisms that encode temporal dependencies more explicitly.
In parallel, speech applications in assistants, chatbots, and customer service face challenges from dialectal variation, pronunciation differences, and everyday disfluencies. These issues motivate integrated post-processing tools such as speech-to-speech disfluency correction, highlighting a broader demand for temporally aware processing across spoken and generated media.
Infographic (English)
Progress
CoSyncDiT: Cognitive Synchronous Diffusion Transformer for Movie Dubbing <See Details on Fugu-MT>
Proposes a flow-matching movie dubbing framework that synchronizes generated speech with lip motion while preserving speaker identity. Replaces explicit duration-level alignment used in prior dubbing methods with a cognitive synchronous diffusion transformer for more natural synchronization.
ControlFoley: Unified and Controllable Video-to-Audio Generation with Cross-Modal Conflict Handling <See Details on Fugu-MT>
Introduces a unified video-to-audio framework that jointly conditions synthesis on video, text, and reference audio. Addresses weak text controllability and visual-text conflicts that limited earlier V2A methods by handling multiple modalities and style control in one system.
DiT as Real-Time Rerenderer: Streaming Video Stylization with Autoregressive Diffusion Transformer <See Details on Fugu-MT>
Presents a streaming video stylization framework based on an autoregressive diffusion transformer distilled for real-time use. Achieves few-step real-time rerendering with both text-guided and reference-guided modes, advancing beyond prior offline-only video stylization pipelines.
Outlook
Outlook Summary
Near-term work is likely to focus on making temporally controlled generation faster and more practical. These results suggest growing emphasis on low-latency, coherent video pipelines that maintain identity, lip-sync, and frame-to-frame consistency rather than solely improving offline visual quality.
On the audio side, the representative controllable audio paper calls for larger timestamped datasets to cover rare events, while this week's multimodal video-to-audio work shows increasing interest in combining video, text, and reference signals to resolve timing and style conflicts jointly.
Infographic (English)

Three-Year Movement
If those modular integrations prove sticky, then over roughly three years research is likely to organize around shared temporal abstractions across modalities—event graphs, aligned latent timelines, cross-modal sync objectives, and standardized benchmarks for coherence, timing fidelity, and editability—without requiring a single universal architecture to dominate. Under that same condition, application stacks would become more explicitly timeline-aware, with stable video generation, structured audio control, and routine speech cleanup or dubbing assistance working together inside production toolchains, especially for creator workflows, multilingual localization, stylized media production, and interactive content where predictable timing is essential.
If that evaluation shift keeps holding over roughly three years, research would increasingly center on temporally explicit objectives, with hybrid multimodal systems baking in coherence modules, event-graph conditioning, and sync-aware losses, and with dense timestamped datasets becoming normal for serious benchmark releases. Under that path, long-form consistency, rare-event timing, and video-audio alignment become standard benchmark tracks, making it harder for scale-only systems to dominate. In applications, the same logic would push temporal quality into operational practice in dubbing, creative video, language tutoring, and some accessibility-oriented speech tools, where QA dashboards and buyer requirements start tracking flicker stability, sync error, event timing, and residual disfluency. That would enable more dependable production dubbing and stylization, more controllable audio generation for interactive media, and more polished speech-cleanup features, although the strongest uptake would still be concentrated in premium and workflow-critical products rather than universal consumer deployment.
If the same path keeps strengthening over roughly three years, research would start to incorporate temporal observability directly into model development through preference optimization, data filtering, and targeted fine-tuning, while timeline-structured formats become a more common interface between prompting, evaluation, and editing. On that path, part of the scarce timestamped training data problem gets eased because instrumented pipelines generate reusable temporal annotations as a byproduct of routine use. Application-side progress would then show up most clearly in production dubbing, speech cleanup, stylization, and synchronized media pipelines, where temporal dashboards and QA gates catch flicker, timing drift, sync failures, and residual disfluencies before release, and where interactive tools expose timing controls with immediate quality feedback. Even in that stronger 36-month version, architecture would still matter, but platforms with more trusted observability stacks would iterate faster and operationalize temporal control more reliably than teams relying mainly on subjective review.
References
- DisfluencyFixer: A tool to enhance Language Learning through Speech To Speech Disfluency Correction - Authors: Vineet Bhat, Preethi Jyothi and Pushpak Bhattacharyya / <See Details on Fugu-MT> / License: CC-BY-4.0
- DiffSynth: Latent In-Iteration Deflickering for Realistic Video Synthesis - Authors: Zhongjie Duan, Lizhou You, Chengyu Wang, Cen Chen, Ziheng Wu, Weining Qian, Jun Huang, Fei Chao, Rongrong Ji / <See Details on Fugu-MT> / License: CC-BY-4.0
- DegDiT: Controllable Audio Generation with Dynamic Event Graph Guided Diffusion Transformer - Authors: Yisu Liu, Chenxing Li, Wanqian Zhang, Wenfu Wang, Meng Yu, Ruibo Fu, Zheng Lin, Weiping Wang, Dong Yu, / <See Details on Fugu-MT> / License: CC-BY-4.0