サマリー
本テーマは、動画における時間的構造のモデル理解をいかに評価・改善するかを扱う。代表的な論文は、広く使われているベンチマークが言語事前知識や単一フレームの手がかりに過度に依存した回答を許容していることを示し、より密な時間的ベンチマーク、キーフレームベースの推論タスク、長コンテキストのワールドモデル評価を導入することで、マルチフレームおよび長距離の一貫性をより適切に検証する手法を提案している。
テーマの状況
現在の動画システムは、アノテーションが粗すぎて真の時間的理解を検証できないベンチマークで評価されることが多い。TemporalBenchは、多くの一般的な動画QA設定が言語事前知識や静的な視覚的手がかりで解けてしまうことを実証し、イベントの進行、長距離依存関係、細粒度の動作差異を対象とした、より密な人手作成のキャプションと質問の必要性を示している。並行して、Video Infilling and Predictionは動画理解をキーフレーム間のマルチホップ推論として定式化し、詳細なテキスト記述を用いてモデルが時間的文脈から欠落フレームや未来フレームを推論できるかを検証している。
関連する研究系列は、この問題意識を評価から生成的ワールドモデルにおける表現と記憶へと拡張している。Long-Context State-Space Video World Modelsは、限られたアテンションウィンドウにより既存システムが以前に見た領域を忘却し、シーンを再訪した際に持続性が破綻することを示している。同研究は状態空間モデルによる長期状態追跡を提案し、過去に観測された環境に対する検索・推論の指標を導入しており、動画モデルが拡張された時間・空間範囲にわたり一貫した時間的・空間的表現を維持できるかを検証するという、より広い潮流を反映している。
- Let's Think Frame by Frame: Evaluating Video Chain of Thought with Video Infilling and Prediction
- TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models
- Long-Context State-Space Video World Models
インフォグラフィクス(日本語)
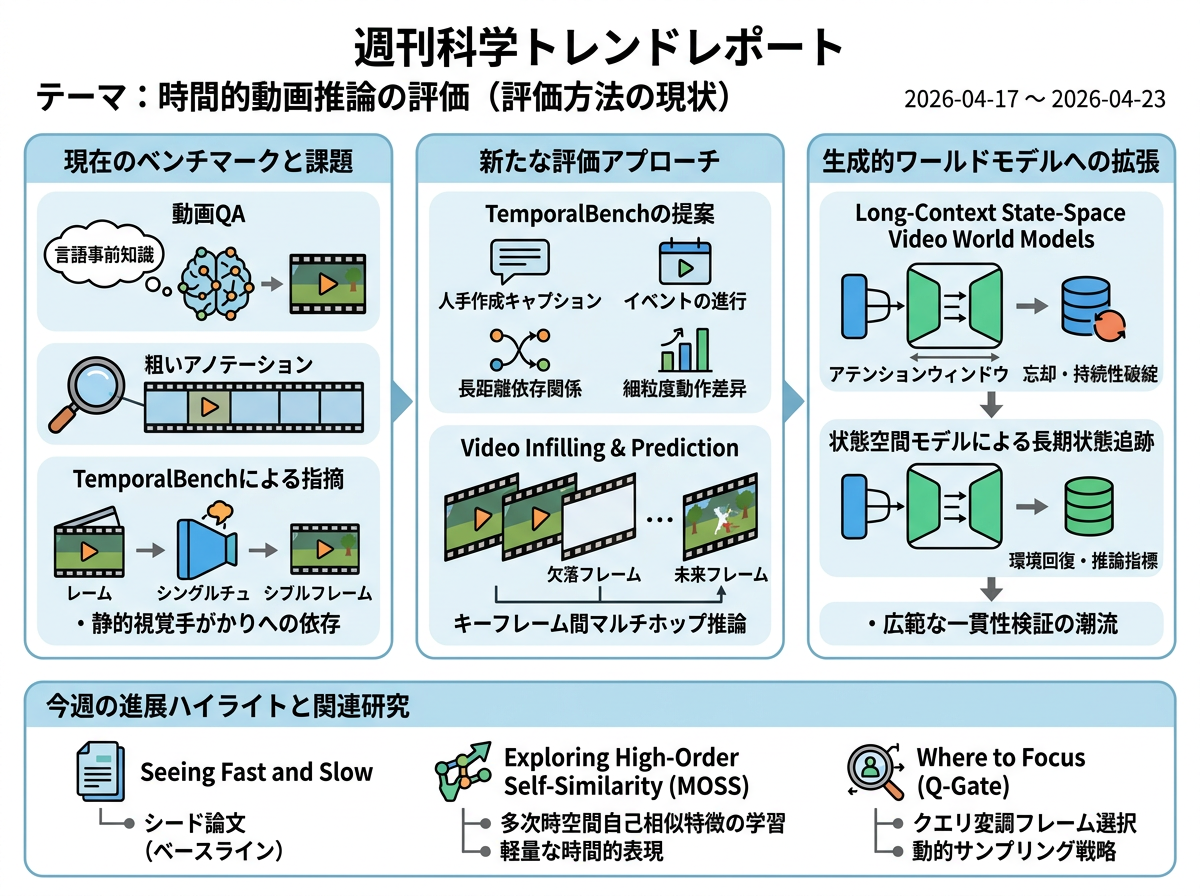
今週の進展
Seeing Fast and Slow: Learning the Flow of Time in Videos <See Details on Fugu-MT>
「Seeing Fast and Slow: Learning the Flow of Time in Videos」は、今週のテーマの起点となるシード論文である。 今週の進展を解釈するためのベースライン参照として位置づけられる。
Exploring High-Order Self-Similarity for Video Understanding <See Details on Fugu-MT>
MOSSは、多様な動画タスクにおける動作モデリングのために多次時空間自己相似特徴を学習する軽量モジュールを導入している。 代表論文のベンチマーク中心のアプローチと比較して、最小限の追加計算コストで時間的動作理解を改善するコンパクトな表現メカニズムを提供する。
Where to Focus: Query-Modulated Multimodal Keyframe Selection for Long Video Understanding <See Details on Fugu-MT>
Q-Gateはキーフレーム選択を動的なモダリティルーティング問題として扱い、長時間動画理解のためにクエリに関連するフレームサンプリングを可能にしている。 従来の固定キーフレーム推論設定と比較して、質問に応じてフレーム選択を適応させるプラグアンドプレイ戦略を提供し、長コンテキストの時間的評価に直接対応している。
今後の展望
今後の展望(要約)
近い将来、時間方向の動画評価はより厳密で細かくなる可能性が高い。ベンチマークは、言語的な先入観だけで解ける抜け道を減らし、モデルが多くのフレームにわたって出来事、物体、場面状態を追跡できるかを試す方向に進むだろう。評価指標も、複数フレームにまたがる推論、長期記憶、時空間的な位置特定、細かなキャプション生成へ広がりそうだ。同時にモデル研究は、単なる弱点診断から、軽量な動きモジュールや質問に関係するキーフレーム選択のような、コンパクトな時間表現へ移りつつある。長文脈の状態空間型ワールドモデルと合わせると、単に文脈窓を大きくするのではなく、長い時間にわたって有用な記憶を効率よく保つ動画システムへ向かう流れが見える。
インフォグラフィクス(日本語)
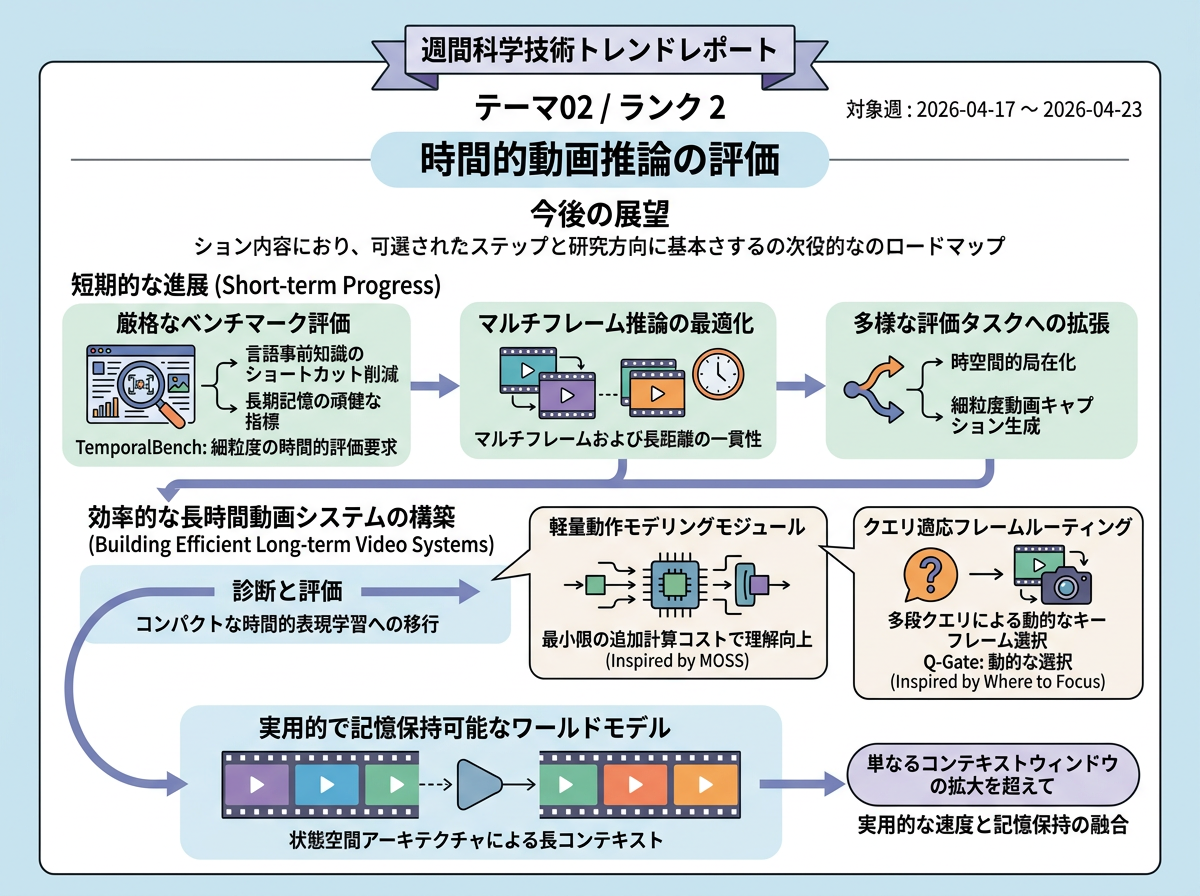
3年後を想定した動き
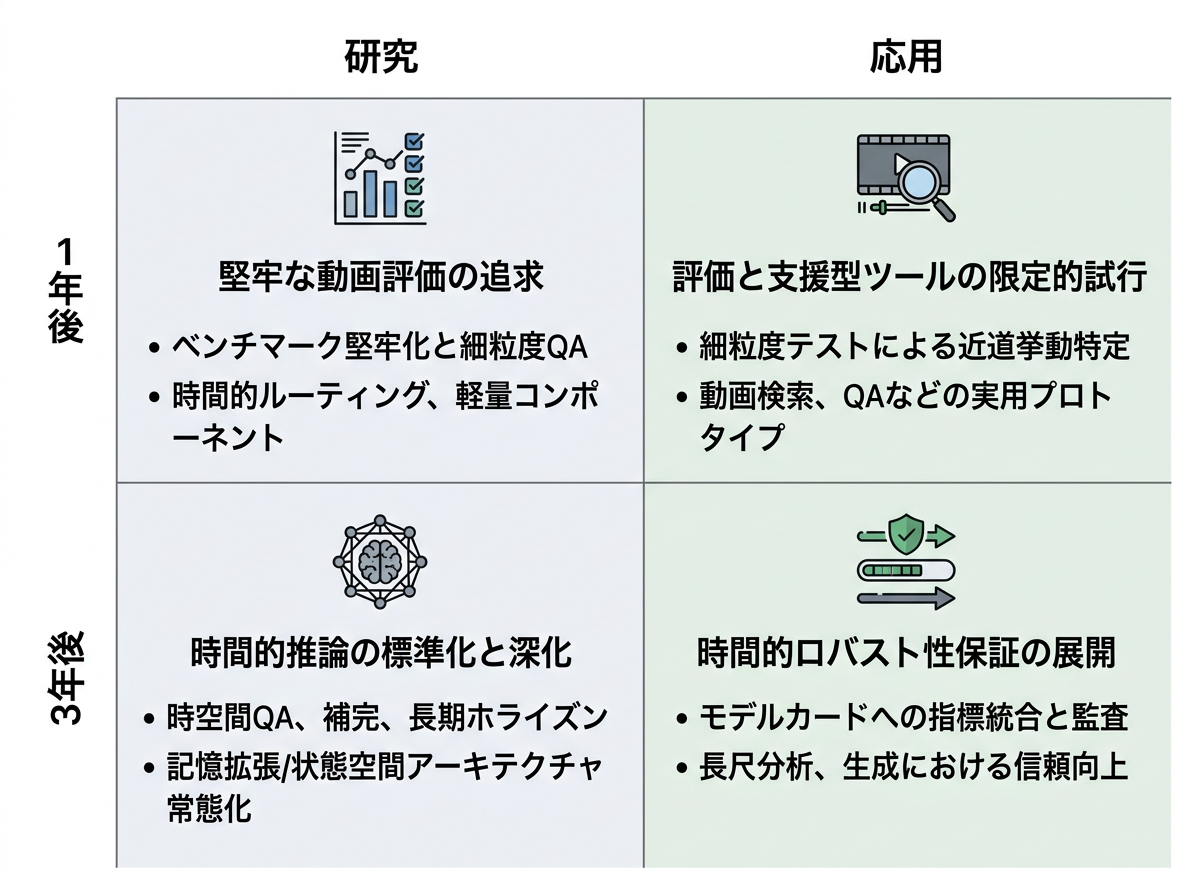
今後1年ほどで、時間方向の動画研究では、より厳しい評価を標準的に使う動きが強まりそうだ。出来事の順序、物体の持続性、欠けたフレームの推測、時間的な位置特定などを調べるテストが増えるだろう。モデル側では、キーフレーム選択、メモリトークン、動きに敏感なモジュール、注意機構と状態空間ブロックを組み合わせた構成が使われやすくなる。状態空間手法は、時間に沿って小さな実行中メモリを保てる点が重要である。3年ほど先には、時間推論が広い動画スコアの中に隠れた弱点ではなく、動画AIの標準的な報告項目になる可能性がある。研究用スイートは、理解、予測、位置特定、生成の一貫性、長期記憶をまとめて試すようになるだろう。実利用では、長い動画の分析やレビューの信頼性が高まり、モデルカード、調達時の確認、メディア検証、シミュレーション、監視映像レビュー、対話型コンテンツ、産業・警備用途、一部の科学動画ワークフローで時間的な頑健性スコアが使われ始める。
今後1年は、分野全体として時間方向のより厳しいテストへ進むが、密なアノテーションと長時間動画の計算コストが広い合意形成を遅らせそうだ。運転、スポーツ、料理、監視などの領域では、狭い実世界ベンチマークを作るグループが出てくるだろう。一方で、多くの研究者は正解データを安く作れるため、合成環境やゲーム風の環境を使い続ける可能性が高い。軽量な時間アダプタ、動きモジュール、キーフレーム選択、追加メモリは、最先端規模の予算がなくても試せるため広がるだろう。3年ほどで、このコスト差は二層構造の研究エコシステムを生むかもしれない。オープンな研究コミュニティは有用だが不完全な代理指標として合成ベンチマークに頼り、先端企業研究所は状態空間メモリ、検索、注意機構を組み合わせた独自の長期ワールドモデルを進めるだろう。運転、手術、監視、工業検査などでは認証向けの実世界ベンチマークが一部現れる可能性があるが、範囲は狭く費用も高いため、応用の進展は資金のある分野に偏り、一般的な時間動画QAはまれな失敗例への信頼性不足に制約され続ける。
今後1年で、時間方向の動画テストを厳しくする現在の流れは、監査に使いやすい形へ進む可能性がある。ベンチマーク作成者は、よりきれいな版、データ漏えい対策、再現可能な人間ベースライン、モデルが近道ではなく本当に時間的証拠を使っているかを調べる敵対的プローブを追加するかもしれない。先端研究所も、システムカードで時間推論スコアを一般的な動画QAスコアから分けて示し始める可能性がある。3年ほどで、こうした兆候は、認証可能な時間動画評価というより正式な分野へ発展するかもしれない。研究者は、版管理されたベンチマークを維持し、領域ごとの失敗パターンを調べ、評価者がどのフレームを使ったか見られるように、点検可能なメモリと追跡可能なキーフレーム選択を持つモデルを設計するだろう。応用面では、一部の分野や法域で、高リスクな動画AIの調達や適合性評価に時間動画テストが組み込まれる可能性がある。評価企業やベンチマーク提供者は時間テストサービスを販売し、明示的な時間的根拠、状態空間メモリ、キーフレーム選択を持つシステムが、安全重視の導入で有利になるだろう。
1年後・3年後の研究/応用インフォグラフィクス
参照論文
- Let's Think Frame by Frame: Evaluating Video Chain of Thought with Video Infilling and Prediction - 著者: Vaishnavi Himakunthala, Andy Ouyang, Daniel Rose, Ryan He, Alex Mei, Yujie Lu, Chinmay Sonar, Michael Saxon, William Yang Wang / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models - 著者: Mu Cai, Reuben Tan, Jianrui Zhang, Bocheng Zou, Kai Zhang, Feng Yao, Fangrui Zhu, Jing Gu, Yiwu Zhong, Yuzhang Shang, Yao Dou, Jaden Park, Jianfeng Gao, Yong Jae Lee, Jianwei Yang, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- Long-Context State-Space Video World Models - 著者: Ryan Po, Yotam Nitzan, Richard Zhang, Berlin Chen, Tri Dao, Eli Shechtman, Gordon Wetzstein, Xun Huang, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0