Summary
This theme addresses how to evaluate and improve models' understanding of temporal structure in video. Representative papers show that widely used benchmarks often over-reward language priors or single-frame cues, and they introduce denser temporal benchmarks, keyframe-based reasoning tasks, and long-context world-model evaluations to better probe multi-frame and long-range consistency.
Situation
Current video systems are frequently tested with benchmarks whose annotations are too coarse to verify genuine temporal understanding. TemporalBench demonstrates that many popular video QA settings can be solved through language priors or static visual clues, motivating denser human-written captions and questions that target event progression, long-range dependencies, and fine-grained action differences. In parallel, Video Infilling and Prediction frames video understanding as multi-hop reasoning across keyframes, using detailed textual descriptions to test whether models can infer missing or future frames from temporal context.
A related line of work extends this concern from evaluation to representation and memory in generative world models. Long-Context State-Space Video World Models shows that limited attention windows cause existing systems to forget previously seen regions, breaking persistence when scenes are revisited. It proposes long-term state tracking via state-space models and introduces metrics for retrieval and reasoning over previously observed environments, reflecting a broader shift toward testing whether video models preserve coherent temporal and spatial representations over extended horizons.
Infographic (English)

Progress
Seeing Fast and Slow: Learning the Flow of Time in Videos <See Details on Fugu-MT>
Seeing Fast and Slow: Learning the Flow of Time in Videos is the seed paper anchoring this week's theme. It remains the baseline reference for interpreting this week's progress.
Exploring High-Order Self-Similarity for Video Understanding <See Details on Fugu-MT>
MOSS introduces a lightweight module that learns multi-order spatio-temporal self-similarity features for motion modeling across diverse video tasks. Relative to the benchmark-centric focus of the representative papers, this adds a compact representation mechanism that improves temporal motion understanding with minimal extra compute.
Where to Focus: Query-Modulated Multimodal Keyframe Selection for Long Video Understanding <See Details on Fugu-MT>
Q-Gate treats keyframe selection as a dynamic modality-routing problem, enabling query-relevant frame sampling for long-video understanding. Compared with earlier fixed keyframe reasoning setups, it offers a plug-and-play strategy that adapts frame selection to the question, directly addressing long-context temporal evaluation.
Outlook
Outlook Summary
Near-term work is likely to make temporal video evaluation stricter and more detailed. Benchmarks should reduce language-prior shortcuts and test whether models can track events, objects, and scene state across many frames. Metrics will likely expand toward multi-frame reasoning, long-horizon memory, spatio-temporal localization, and fine-grained captioning. At the same time, model work is shifting from diagnosis to compact temporal representations, such as lightweight motion modules and query-relevant keyframe routing. Together with long-context state-space world models, this points toward efficient video systems that keep useful memory over longer horizons without relying only on larger context windows.
Infographic (English)
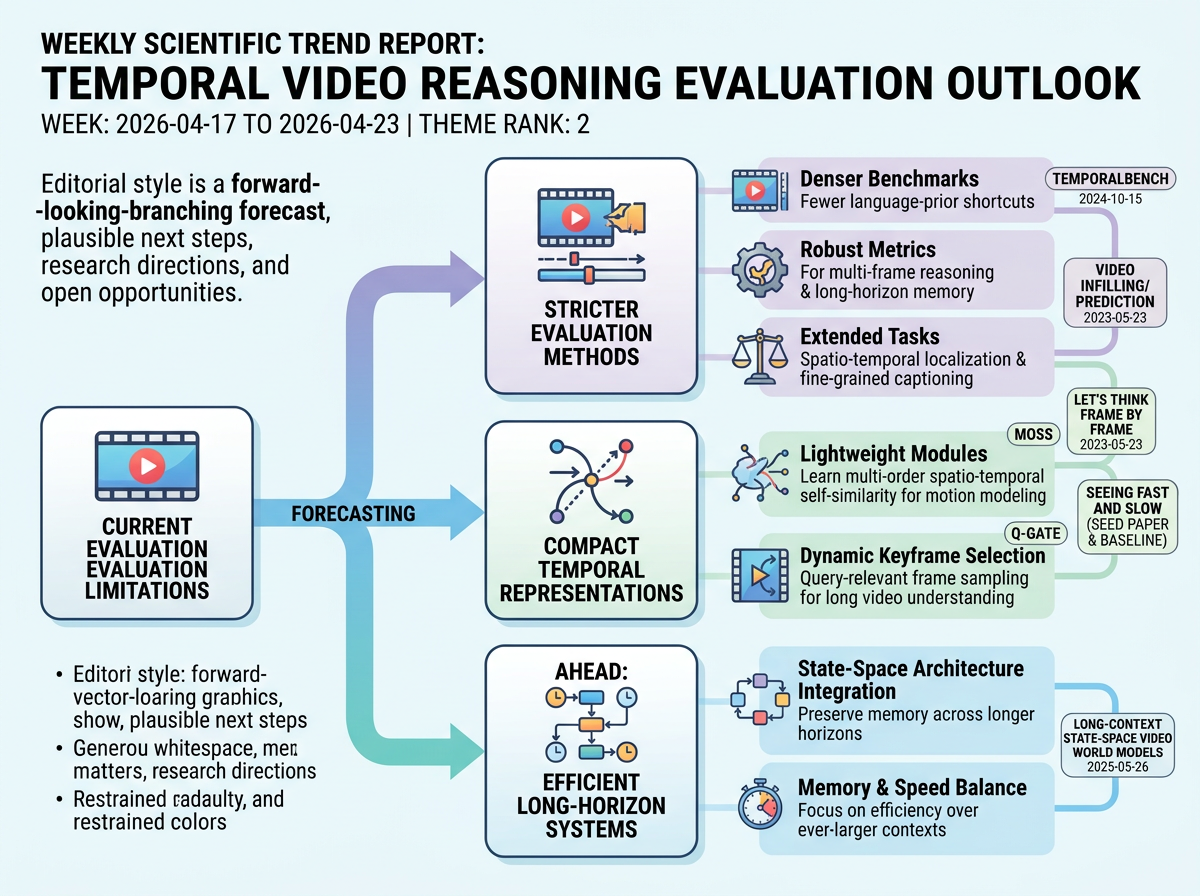
Three-Year Movement
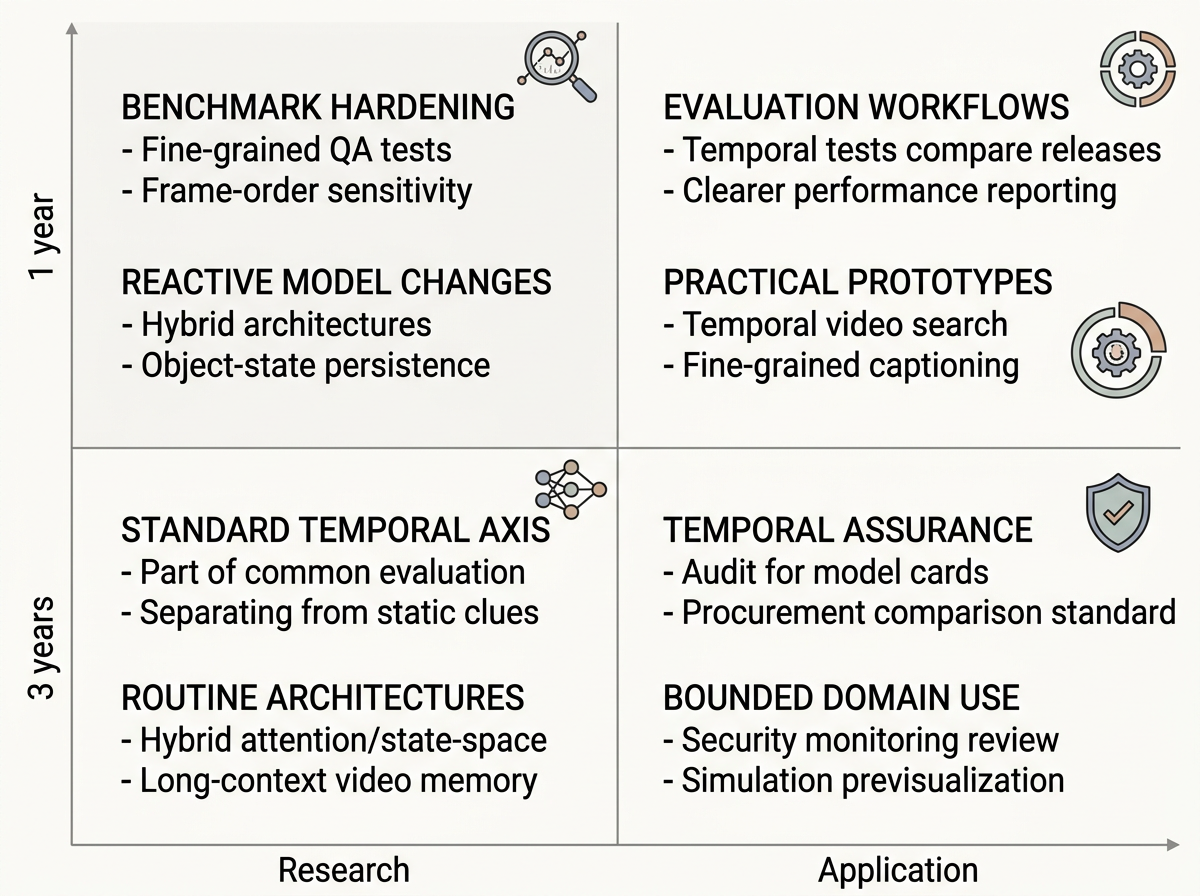
Over the next year, temporal video research is likely to turn stricter evaluation into normal practice, with tests for event order, object persistence, missing-frame inference, and temporal localization. Models will likely add keyframe routing, memory tokens, motion-sensitive modules, and hybrid attention plus state-space blocks, where state-space methods keep compact running memory over time. Around three years out, temporal reasoning could become a standard reporting category for video AI rather than a hidden weakness inside broad video scores. Research suites would test understanding, prediction, localization, generation consistency, and long-horizon memory together. Memory-augmented and state-space-style designs would become common options for long-video systems. In use, the main change would be credible long-video analysis and review, with temporal robustness scores appearing in model cards, procurement checks, and early audits for media verification, simulation, monitoring review, interactive content, industrial or security review, and selected scientific video workflows.
In the next year, the field still moves toward stricter temporal tests, but dense annotation and long-video compute costs slow broad convergence. Some groups build narrow real-world benchmarks for domains such as driving, sports, cooking, or surveillance, while many others use synthetic or game-like environments because ground truth is cheaper. Lightweight temporal adapters, motion modules, keyframe routing, and memory add-ons spread because they can be tested without frontier-scale budgets. By about three years, this cost pattern could create a two-tier research ecosystem. The open community would rely on synthetic benchmarks as useful but incomplete proxies, while frontier labs combine state-space memory, retrieval, and attention in proprietary long-horizon world models. A few certified real-world benchmarks may appear for sectors such as driving, surgery, surveillance, or industrial inspection, but they would remain narrow and expensive. Applications would advance unevenly, with stronger tools in well-funded verticals and general temporal video QA still limited by weak edge-case reliability.
In the next year, the current push for stricter temporal video tests is likely to become more audit-ready. Benchmark groups may add cleaner versions, leakage controls, reproducible human baselines, and adversarial probes that check whether models really use temporal evidence instead of shortcuts. Frontier labs may also start separating temporal-reasoning scores from general video QA in system cards. Over about three years, these signals could develop into a more formal discipline of certifiable temporal video evaluation. Researchers would maintain versioned benchmarks, study domain-specific failure modes, and design models with inspectable memory and traceable keyframe selection, meaning evaluators can see which frames the system used. In applications, temporal video testing could become part of procurement or conformity assessment for high-risk video AI in some sectors or jurisdictions. Evaluation firms and benchmark providers could sell temporal testing services, while systems with explicit temporal grounding, state-space memory, and keyframe routing gain an advantage in safety-sensitive deployments.
1-Year / 3-Year Research-Application Infographic
References
- Let's Think Frame by Frame: Evaluating Video Chain of Thought with Video Infilling and Prediction - Authors: Vaishnavi Himakunthala, Andy Ouyang, Daniel Rose, Ryan He, Alex Mei, Yujie Lu, Chinmay Sonar, Michael Saxon, William Yang Wang / <See Details on Fugu-MT> / License: CC-BY-4.0
- TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models - Authors: Mu Cai, Reuben Tan, Jianrui Zhang, Bocheng Zou, Kai Zhang, Feng Yao, Fangrui Zhu, Jing Gu, Yiwu Zhong, Yuzhang Shang, Yao Dou, Jaden Park, Jianfeng Gao, Yong Jae Lee, Jianwei Yang, / <See Details on Fugu-MT> / License: CC-BY-4.0
- Long-Context State-Space Video World Models - Authors: Ryan Po, Yotam Nitzan, Richard Zhang, Berlin Chen, Tri Dao, Eli Shechtman, Gordon Wetzstein, Xun Huang, / <See Details on Fugu-MT> / License: CC-BY-4.0