サマリー
本テーマは、現実的かつ制御された条件下で、科学研究や複雑な情報探索を行うLLMベースエージェントをどのように評価するかに焦点を当てている。代表的な論文は、現行の評価が標準化されたツール環境、制御された検索、コストを考慮したスコアリング、および強力なエージェント間ベースラインを欠いていると主張し、既存システムが推論集約型の研究タスクで依然として苦戦していることを示している。
テーマの状況
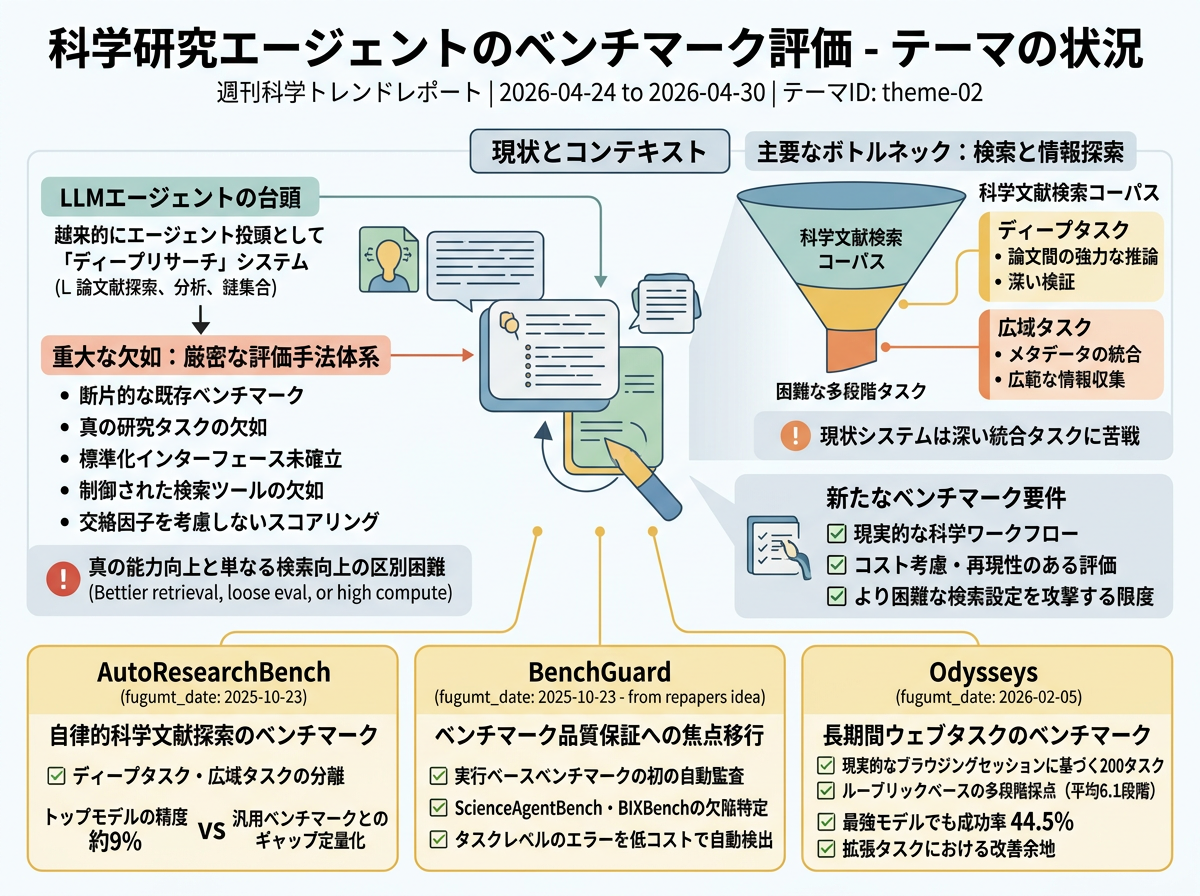
LLMエージェントは文献探索・分析・統合のための「ディープリサーチ」システムとしてますます位置づけられているが、その実際の能力を測定するための十分に厳密な方法が欠如している。既存のベンチマークは断片的であり、真正な研究タスク、汎用エージェント向けの標準化されたインターフェース、制御された検索ツール、またはツールアクセスや推論コストなどの交絡因子を考慮したスコアリング方式が欠けていることが多い。そのため、性能向上がより強力な推論・計画能力に由来するのか、単により良い検索アクセス、緩い評価、またはより多くの計算量に由来するのかを判断することが困難である。
検索と情報探索が中心的なボトルネックとして特定されている。科学文献検索はこれらのシステムを研究するための制御されたコーパスを提供するが、現在のエビデンスによれば、エージェントは論文間の推論、メタデータの統合、あるいは広範な情報収集と深い多段階検証の組み合わせが求められるタスクで依然として困難を抱えている。そのため新たなベンチマーク提案は、より現実的な科学ワークフロー、コストを考慮した再現可能な評価、および現在の限界を露呈させるより困難な検索設定に焦点を当てている。
- DeepWideSearch: Benchmarking Depth and Width in Agentic Information Seeking
- AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
- SAGE: Benchmarking and Improving Retrieval for Deep Research Agents
インフォグラフィクス(日本語)
今週の進展
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery <See Details on Fugu-MT>
AutoResearchBenchは、深層研究タスクと広域研究タスクの2種類を分離した、自律的科学文献探索のためのベンチマークを導入した。 トップモデルでも両タスクタイプで約9%の精度にとどまり、汎用ウェブブラウジングベンチマークが示唆するよりもはるかに大きなギャップを定量化している。
BenchGuard: Who Guards the Benchmarks? Automated Auditing of LLM Agent Benchmarks <See Details on Fugu-MT>
BenchGuardは、実行ベースのエージェントベンチマークに対する初の自動監査フレームワークを提案し、ScienceAgentBenchおよびBIXBenchにおける確認済みの欠陥を特定した。 これにより焦点がベンチマーク作成のみからベンチマーク品質保証へと移行し、タスクレベルのエラーを低コストで自動検出できることを示した。
Odysseys: Benchmarking Web Agents on Realistic Long Horizon Tasks <See Details on Fugu-MT>
Odysseysは実際のブラウジングセッションから導出された200の長期間ウェブタスクを提示し、ルーブリックベースの採点によりライブインターネット上で評価を行った。 二値の合否判定をタスクあたり平均6.1段階の多段階ルーブリックに置き換え、最強モデルでも成功率は44.5%にとどまり、拡張タスクにおける改善余地の大きさを浮き彫りにしている。
今後の展望
今後の展望(要約)
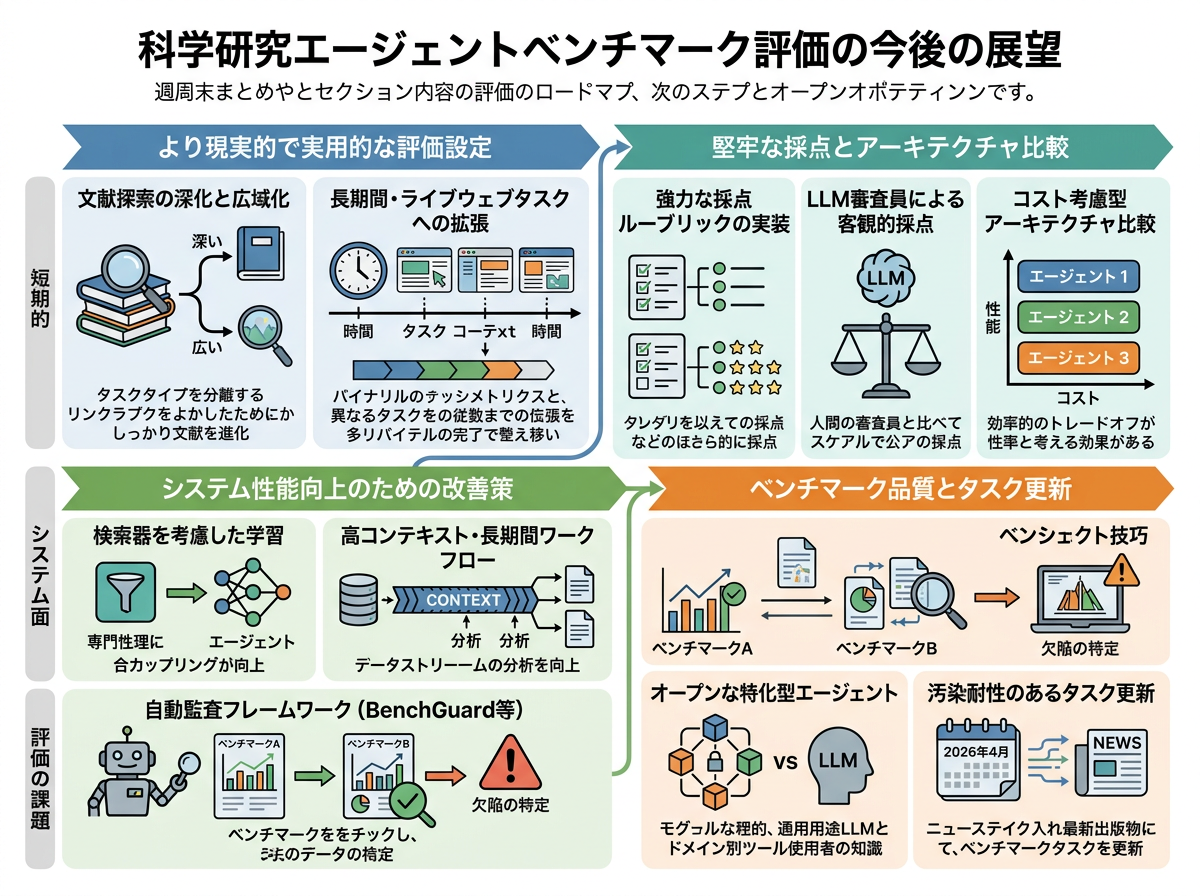
近い将来、研究エージェントの評価は、より現実的で、科学分野に特化し、不正に高得点を取りにくいものになりそうです。新しいベンチマークは、深い文献発見と広いウェブ検索型の探索を分けて測り、より長いライブ課題を加え、主要エージェントでも成功率が低いことを示しています。次の焦点は、最近の論文に基づく課題更新、より強い採点基準とLLM審査、データ漏えい確認、エージェント設計やツール構成ごとの費用対効果の比較です。システム面では、検索、文脈処理、長時間ワークフロー、検索器を意識した訓練が主な改善点になります。ベンチマーク監査も、単なる品質確認ではなく研究テーマの一部になりつつあります。
インフォグラフィクス(日本語)
3年後を想定した動き
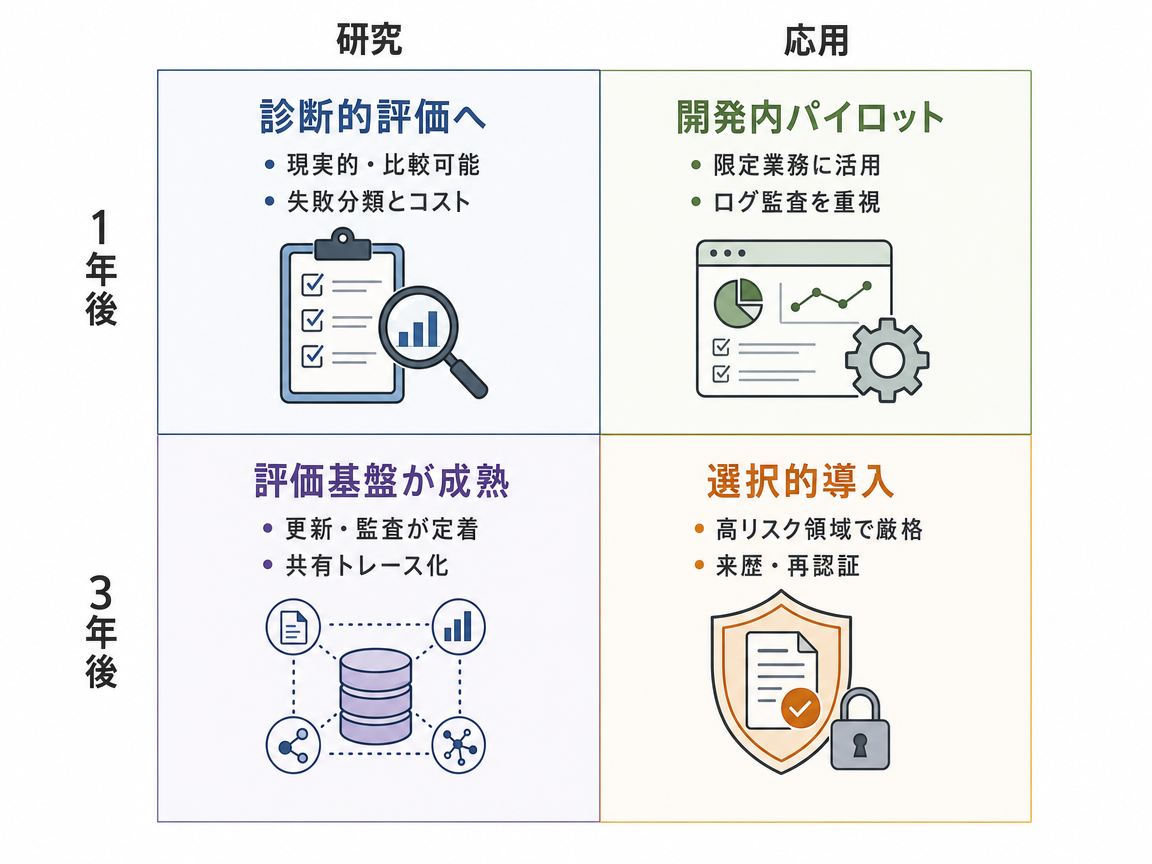
今後1年で、研究エージェントのベンチマークは、より科学的で、頻繁に更新され、失敗原因を診断しやすいものになるでしょう。管理された論文コーパス、標準的なツール接口、費用記録、実行ログ、データ漏えい確認が重視されます。研究者は、BM25、ハイブリッド検索、LLMベース検索器、テスト時スケーリングを、より厳密な採点の下で比較し、検索システムや文脈管理、ツール設定を中核変数として扱うようになります。3年ほどで、最近の課題を定期的に追加する「生きたベンチマーク環境」へ進む可能性があります。これにより、モデルが暗記した例に頼ることは難しくなり、公開前監査、ベースライン、ログ、遅延、費用、採点方法の標準も安定していくでしょう。エージェント設計は、長い文脈の処理、根拠追跡、クエリ計画、引用に基づく回答、検索器を意識した訓練へ向かいます。実利用では、ベンチマーク結果が研究所、出版社、プラットフォーム企業、産業R&D部門のガバナンス層となり、文献監視、証拠マッピング、プロトコル確認、仮説空間の分析には使われますが、汎用的な自律科学発見にはまだ届かないでしょう。
今後1年で、現実的な科学評価への流れは、費用の制約にぶつかる可能性があります。完全なベンチマーク実行には、多数のエージェント試行、大規模な科学コーパス、管理されたツール、専門家レビューが必要になるためです。そのため研究者は、安価な部分集合、代理課題、ライブウェブを使う簡易評価を、完全な評価スイートと照合するようになるでしょう。論文では、費用、実行回数、不確実性を報告することが増えますが、反復的な完全評価は主に資金力のある研究所に限られます。3年ほどで、評価の生態系は二層化するかもしれません。一部のトップ層の組織が、更新され、汚染に強いベンチマークと信頼されるリーダーボードを維持し、多くの研究者は比較しにくい安価な代理評価に頼る形です。実務では、大手AI企業、製薬企業、材料研究チーム、ベンチマーク運営者が、文献レビュー、仮説生成、ワークフロー支援のためにエージェントをより厳密に検証し、高予算または規制分野での信頼は高まる一方、信頼できる検証が高価になり二層市場を強める恐れもあります。
今後1年で、科学エージェントの評価は、最終スコアだけでなく、実行過程のトレース診断へ移る可能性があります。トレースとは、ツール呼び出し、検索結果、中間手順、費用、評価者の判断を含む、エージェント実行の構造化記録です。ベンチマークは、成功したかどうかだけでなく、失敗が悪い検索、間違ったツール順序、文脈あふれ、有用な証拠を集めた後の弱い統合のどれに由来するかを問うようになります。3年ほどで、分野やツールをまたいで科学エージェントの手順を共通に記述する「共有トレース・オントロジー」に収束するかもしれません。そうなれば、多数の成功例と失敗例を大規模に分析でき、ライブ課題の最中に繰り返し起こる失敗パターンを自動検出できます。ベンチマークと実運用中の監視は、同じ可観測性スタックを使うため、密接に結びつくでしょう。応用面では、科学エージェント基盤は、来歴管理、監査証跡、デバッグ品質、回帰検出で競争し、高リスク組織はエージェント支援の主張が重要な場合にトレース水準の証拠を求めるようになります。
1年後・3年後の研究/応用インフォグラフィクス
参照論文
- DeepWideSearch: Benchmarking Depth and Width in Agentic Information Seeking - 著者: Tian Lan, Bin Zhu, Qianghuai Jia, Junyang Ren, Haijun Li, Longyue Wang, Zhao Xu, Weihua Luo, Kaifu Zhang, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite - 著者: Jonathan Bragg, Mike D'Arcy, Nishant Balepur, Dan Bareket, Bhavana Dalvi, Sergey Feldman, Dany Haddad, Jena D. Hwang, Peter Jansen, Varsha Kishore, Bodhisattwa Prasad Majumder, Aakanksha Naik, Sigal Rahamimov, Kyle Richardson, Amanpreet Singh, Harshit Surana, Aryeh Tiktinsky, Rosni Vasu, Guy Wiener, Chloe Anastasiades, Stefan Candra, Jason Dunkelberger, Dan Emery, Rob Evans, Malachi Hamada, Regan Huff, Rodney Kinney, Matt Latzke, Jaron Lochner, Ruben Lozano-Aguilera, Cecile Nguyen, Smita Rao, Amber Tanaka, Brooke Vlahos, Peter Clark, Doug Downey, Yoav Goldberg, Ashish Sabharwal, Daniel S. Weld, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- SAGE: Benchmarking and Improving Retrieval for Deep Research Agents - 著者: Tiansheng Hu, Yilun Zhao, Canyu Zhang, Arman Cohan, Chen Zhao, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0