Summary
This theme centers on how to evaluate LLM-based agents for scientific research and complex information seeking under realistic, controlled conditions. Representative papers argue that current evaluations lack standardized tool environments, controlled retrieval, cost-aware scoring, and strong cross-agent baselines, while showing that existing systems still struggle on reasoning-intensive research tasks.
Situation
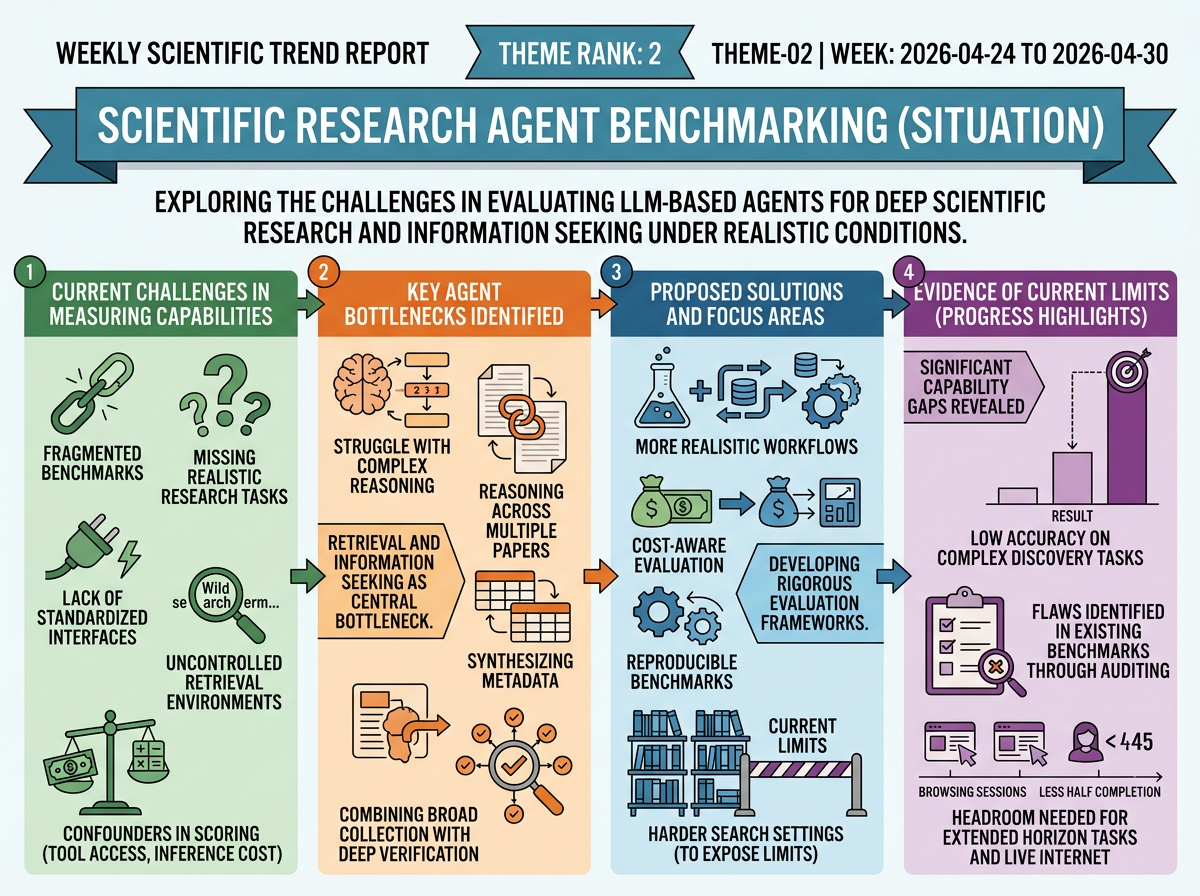
LLM agents are increasingly positioned as "deep research" systems for literature discovery, analysis, and synthesis, yet the field lacks sufficiently rigorous ways to measure their real capabilities. Existing benchmarks are fragmented, often missing authentic research tasks, standardized interfaces for general-purpose agents, controlled retrieval tools, or scoring schemes that account for confounders such as tool access and inference cost. This makes it difficult to determine whether gains come from stronger reasoning and planning or simply from better search access, looser evaluation, or more computation.
Retrieval and information seeking are identified as central bottlenecks. Scientific literature search provides a controlled corpus for studying these systems, and current evidence shows that agents still struggle when tasks require reasoning across papers, synthesizing metadata, or combining broad information collection with deep multi-step verification. New benchmark proposals therefore focus on more realistic scientific workflows, cost-aware and reproducible evaluation, and harder search settings that expose current limits.
Infographic (English)
Progress
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery <See Details on Fugu-MT>
AutoResearchBench introduces a benchmark for autonomous scientific literature discovery with separate deep-research and wide-research task types. Even top models reach only about 9% accuracy on both task types, quantifying a much larger gap than generic web-browsing benchmarks suggest.
BenchGuard: Who Guards the Benchmarks? Automated Auditing of LLM Agent Benchmarks <See Details on Fugu-MT>
BenchGuard proposes the first automated auditing framework for execution-based agent benchmarks, identifying confirmed flaws in ScienceAgentBench and BIXBench. This shifts focus from benchmark creation alone to benchmark quality assurance, showing that task-level errors can be detected automatically at low cost.
Odysseys: Benchmarking Web Agents on Realistic Long Horizon Tasks <See Details on Fugu-MT>
Odysseys presents 200 long-horizon web tasks derived from real browsing sessions, evaluated on the live internet with rubric-based grading. It replaces binary pass/fail with multi-point rubrics averaging 6.1 grades per task; the strongest model reaches only 44.5% success, highlighting headroom on extended tasks.
Outlook
Outlook Summary
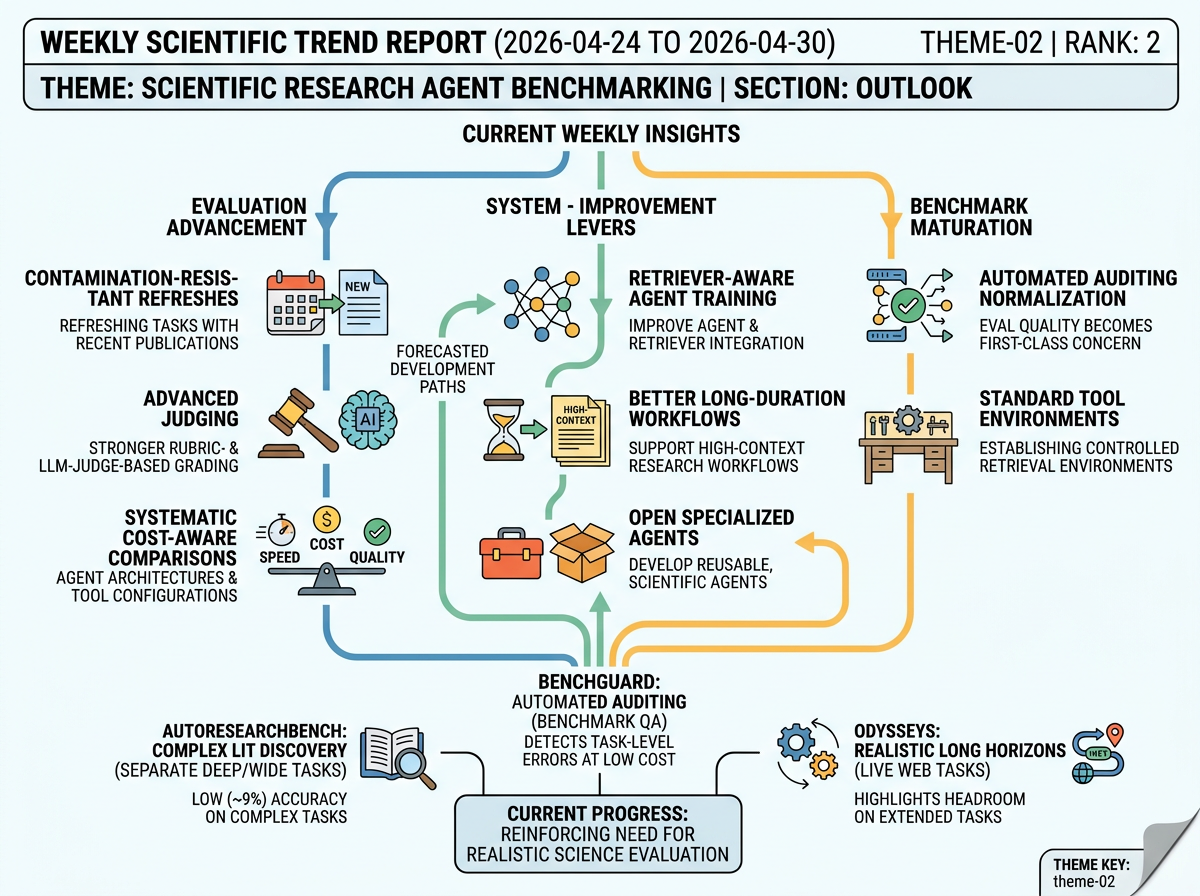
Near-term research-agent evaluation is likely to become more realistic, science-specific, and harder to game. New benchmarks now separate deep literature discovery from broad web-style search, add longer live tasks, and report low success rates for leading agents. The next steps are refreshed tasks based on recent papers, stronger rubric and LLM-judge grading, leakage checks, and more cost-aware comparisons across agent designs and tool setups. On the system side, the main improvement levers are retrieval, context handling, long-duration workflows, and retriever-aware training. Benchmark auditing is also becoming part of the research agenda, not just a background quality check.
Infographic (English)
Three-Year Movement
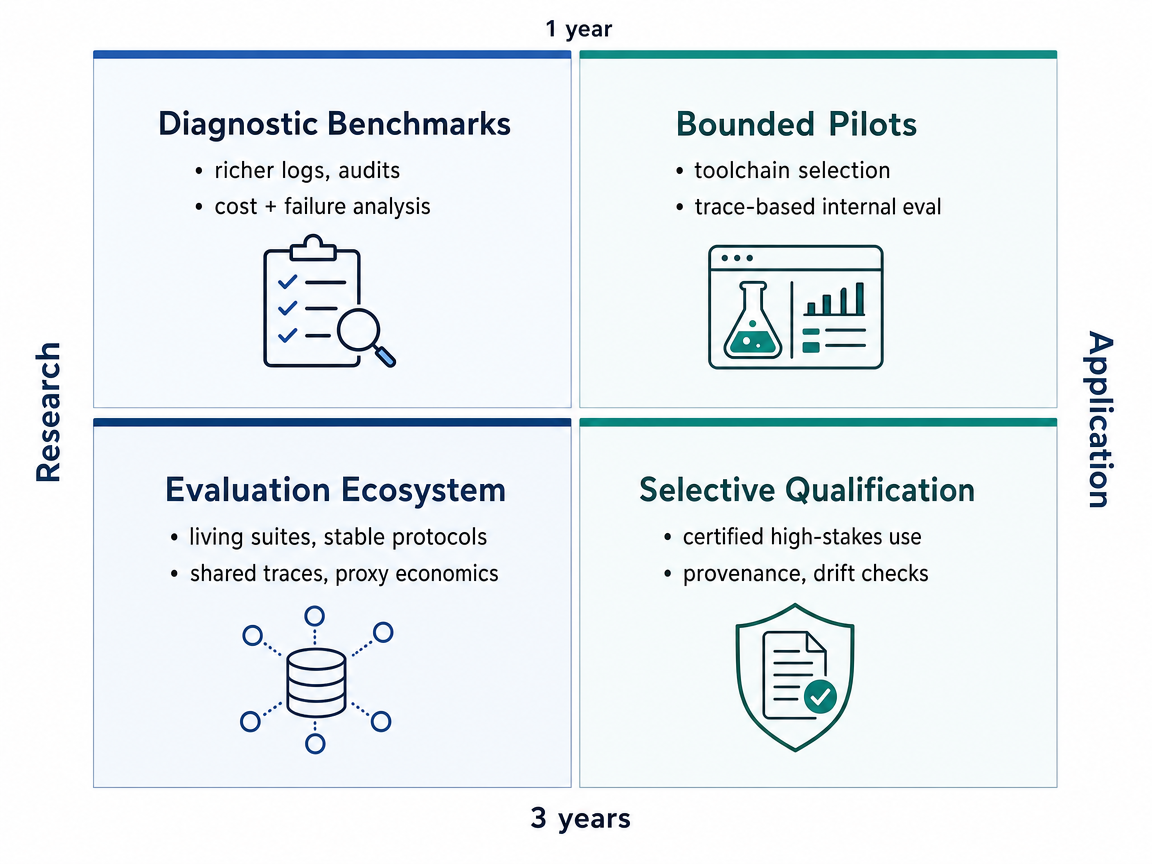
Over the next year, research-agent benchmarks should become more scientific, refreshed, and diagnostic, with controlled paper corpora, standard tool interfaces, cost tracking, logs, and leakage checks. Researchers will treat retrieval systems, context management, and tool configuration as core variables, comparing BM25, hybrid search, LLM-based retrievers, and test-time scaling under stronger grading. By about three years, this points toward living benchmark environments, meaning tests that are regularly updated with recent tasks so models cannot rely on memorized examples. Auditing before release should become expected, and norms for baselines, logs, latency, cost, and grading should become more stable. Agent designs would then shift toward long-context work, evidence tracking, query planning, citation grounding, and retriever-aware training. In use, benchmark evidence becomes a governance layer for labs, publishers, platform teams, and industrial R&D groups. This supports selective deployment in literature surveillance, evidence mapping, protocol checking, and hypothesis-landscape analysis, while still falling short of general autonomous scientific discovery.
In the next year, the push toward realistic scientific evaluation is likely to run into a cost constraint. Full benchmark runs may need many agent trials, large scientific corpora, controlled tools, and expert review, so researchers will test cheaper subsets, proxy tasks, and live-web shortcuts against full suites. Papers should report cost, run counts, and uncertainty more often, but repeated full evaluations will mostly be available to well-funded labs. By about three years, this could create a two-level evaluation ecosystem. A small set of tier-one groups would maintain refreshed, contamination-resistant benchmarks and trusted leaderboards, while many other researchers would depend on cheaper proxies that are harder to compare. In practice, large AI labs, pharmaceutical firms, materials teams, and benchmark owners would validate agents more thoroughly for literature review, hypothesis generation, and workflow support. This would improve trust in some high-budget or regulated settings, but it could also make credible validation expensive and reinforce a two-tier market.
In the next year, scientific-agent evaluation may move from final scores toward trace-level diagnosis. A trace is a structured record of an agent run, including tool calls, retrieval results, intermediate steps, costs, and evaluator decisions. Benchmarks would then ask not only whether the agent succeeded, but whether it failed through bad retrieval, wrong tool order, context overflow, or weak synthesis after collecting useful evidence. By about three years, the field could converge on a shared trace ontology, meaning a common way to describe scientific-agent steps across tools and domains. That would allow large-scale analysis of many successful and failed runs, and automated systems could detect repeated failure patterns during live tasks. Benchmarking and monitoring deployed agents would become closely linked because both would use the same observability stack. In application, scientific-agent platforms would compete on provenance, audit trails, debugging quality, and regression detection, while high-stakes organizations could ask for trace-level evidence when agent-assisted claims matter.
1-Year / 3-Year Research-Application Infographic
References
- DeepWideSearch: Benchmarking Depth and Width in Agentic Information Seeking - Authors: Tian Lan, Bin Zhu, Qianghuai Jia, Junyang Ren, Haijun Li, Longyue Wang, Zhao Xu, Weihua Luo, Kaifu Zhang, / <See Details on Fugu-MT> / License: CC-BY-4.0
- AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite - Authors: Jonathan Bragg, Mike D'Arcy, Nishant Balepur, Dan Bareket, Bhavana Dalvi, Sergey Feldman, Dany Haddad, Jena D. Hwang, Peter Jansen, Varsha Kishore, Bodhisattwa Prasad Majumder, Aakanksha Naik, Sigal Rahamimov, Kyle Richardson, Amanpreet Singh, Harshit Surana, Aryeh Tiktinsky, Rosni Vasu, Guy Wiener, Chloe Anastasiades, Stefan Candra, Jason Dunkelberger, Dan Emery, Rob Evans, Malachi Hamada, Regan Huff, Rodney Kinney, Matt Latzke, Jaron Lochner, Ruben Lozano-Aguilera, Cecile Nguyen, Smita Rao, Amber Tanaka, Brooke Vlahos, Peter Clark, Doug Downey, Yoav Goldberg, Ashish Sabharwal, Daniel S. Weld, / <See Details on Fugu-MT> / License: CC-BY-4.0
- SAGE: Benchmarking and Improving Retrieval for Deep Research Agents - Authors: Tiansheng Hu, Yilun Zhao, Canyu Zhang, Arman Cohan, Chen Zhao, / <See Details on Fugu-MT> / License: CC-BY-4.0