サマリー
今週のテーマは、自己回帰型LLMの代替としての離散・マスク拡散言語モデルに焦点を当てており、特にデコード順序が能力と効率にどのように影響するかが重視されている。代表的な論文は、トークン順序、アンマスキング戦略、帰納的バイアスをこれらのモデルの核心的課題として位置づけ、推論品質、学習可能性、並列生成の実用的価値に影響を与えるとしている。
テーマの状況
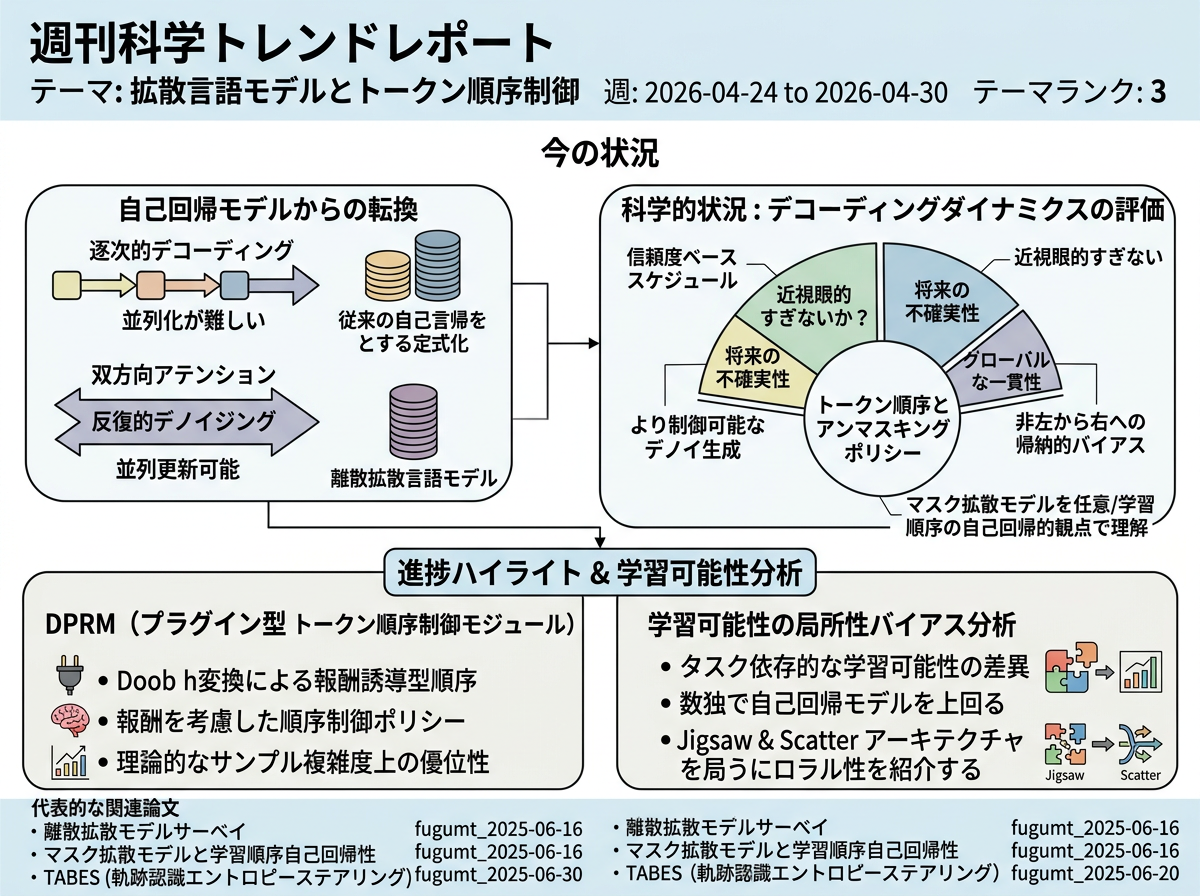
代表論文の序論では、大規模言語モデルやマルチモーダルモデルにおいて依然として主流である自己回帰パラダイムを超えようとする研究動向が示されている。自己回帰デコーディングは強力だが、本質的に逐次的であり、並列化が難しく、精密な構造制御や反復的修正には自然に適さない。離散拡散言語モデルはこれに対し、生成をトークン上での反復的デノイジングとして定式化し、双方向アテンション、並列更新、より制御可能な生成を可能にする。最近の研究では、これらのモデルがますますスケーラブルであり、同等のスケールでは自己回帰モデルと競合しつつ、異なる効率性やインタラクションのトレードオフを開くものとして位置づけられている。
この大きな変化の中で、科学的状況はモデルファミリー単独ではなく、デコーディングダイナミクスの評価によってますます特徴づけられている。序論では、マスク拡散モデルが任意順序または学習順序の自己回帰的観点から理解可能であることが強調されており、トークン順序とアンマスキングポリシーが付随的ではなく中心的な問題となっている。最近の研究は、信頼度ベースや貪欲なスケジュールが近視眼的すぎないか、順序が将来の不確実性やグローバルな一貫性にどう影響するか、そして拡散の非左から右への帰納的バイアスが自己回帰の局所性と比較していつ有利・不利になるか——特に推論、計画、その他のグローバルな依存性が強いタスクにおいて——に焦点を当てている。
- Discrete Diffusion in Large Language and Multimodal Models: A Survey
- Masked Diffusion Models are Secretly Learned-Order Autoregressive Models
- TABES: Trajectory-Aware Backward-on-Entropy Steering for Masked Diffusion Models
インフォグラフィクス(日本語)
今週の進展
DPRM: A Plug-in Doob h transform-induced Token-Ordering Module for Diffusion Language Models <See Details on Fugu-MT>
拡散言語モデル向けのプラグイン型トークン順序制御モジュール(DPRM)を導入し、信頼度駆動の漸進的順序からDoob h変換による報酬誘導型順序への移行を実現。言語推論および科学分野にわたる7つのホスト設定でテストされた。 従来のランダムまたは信頼度のみに基づくアンマスキングへの依存と比較して、所定の計算可能性仮定の下で理論的なサンプル複雑度上の優位性を持つ報酬考慮型の順序制御ポリシーを提供する。
On the Trainability of Masked Diffusion Language Models via Blockwise Locality <See Details on Fugu-MT>
3つの診断タスクにおける自己回帰型LLMとの統制比較を通じてマスク拡散言語モデルの学習可能性を分析し、トークン局所的な左から右への構造を注入する2つの局所性考慮型ブロックワイズアーキテクチャ(JigsawおよびScatter)を提案。 拡散型対自己回帰型デコーディングに関する従来の広範な議論と比較して、本研究はタスク依存的な学習可能性の差異を特定した——標準的なランダムマスキングMDMは線形回帰で失敗するが数独ではARモデルを上回る——そして局所性バイアスをタスク構造に合わせることでその差を縮小できることを示した。
今後の展望
今後の展望(要約)
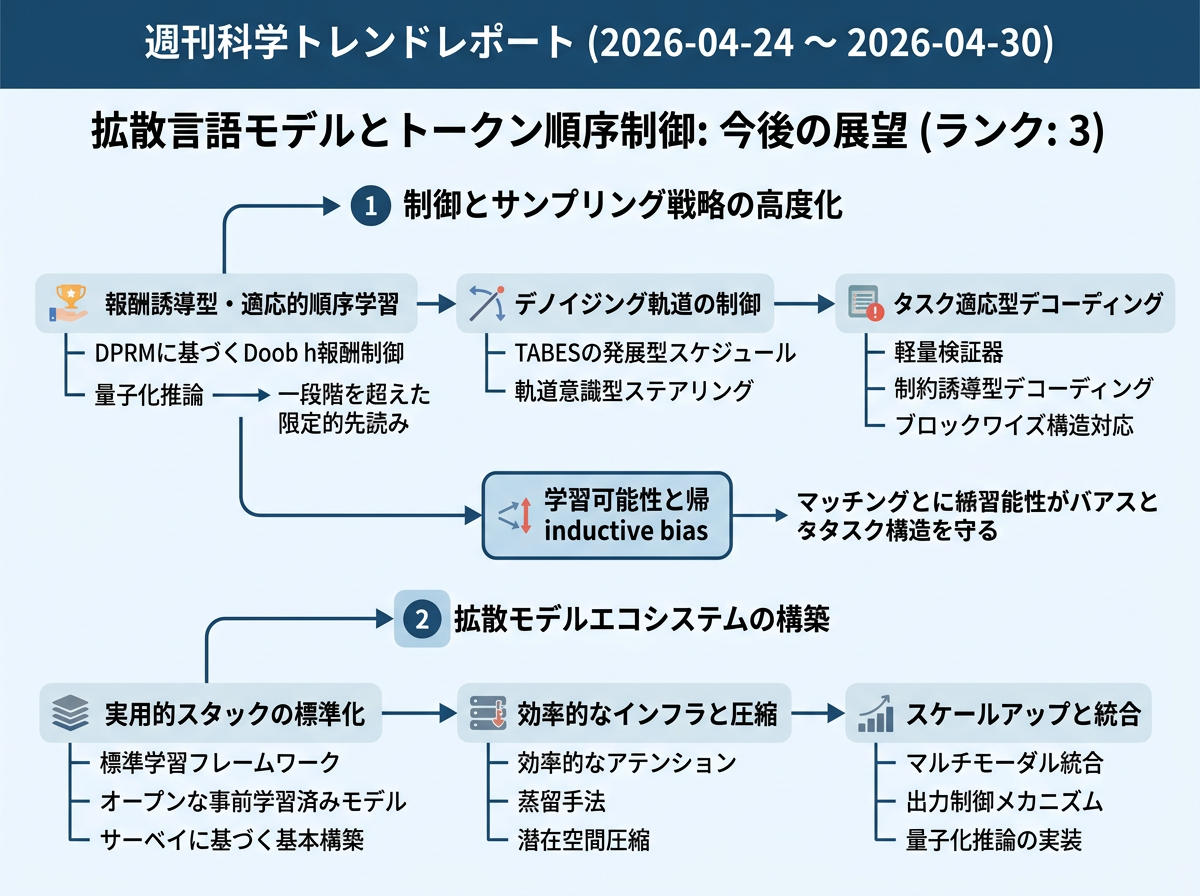
拡散型言語モデルの近い進展は、信頼度だけに頼らない適応的なトークン順序とデコード方針に向かいそうだ。ただし、推論時に実用的な計算量に収めることが重要になる。今週の研究は、報酬で導く差し替え可能な順序付け、限定的な先読み、マスク解除判断の較正改善、不規則なマスク状態に対応する事後学習を後押ししている。軽量な検証器、構造制約、分散の小さいスケジュール、キャッシュ、スケジュール非依存の学習を使い、正しさと遅延のバランスを改善する流れも強まっている。
インフォグラフィクス(日本語)
3年後を想定した動き
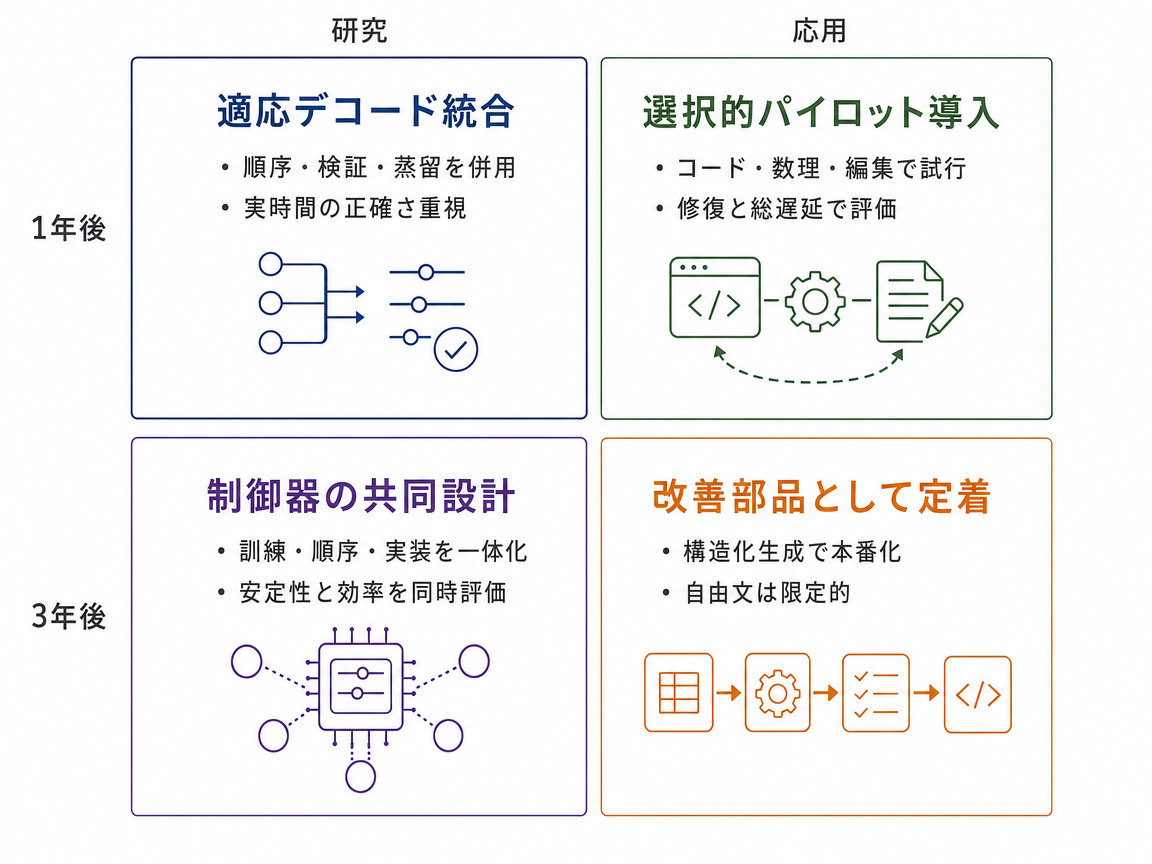
今後1年で、拡散型言語モデルの研究は、適応的デコードを中心的な最適化問題として扱うようになりそうだ。固定された公開スケジュールではなく、信頼度、短い先読み、エントロピー削減、スケジュール非依存の学習、早い段階での正しさ確認を組み合わせる。強い成果と認められるには、デコード手順の回数を減らすだけでなく、実際の実行時間での改善を示す必要がある。対象はコード、数学、長文の穴埋め、制約付き編集、文書生成などの構造化タスクになる。36か月後には、より広い意味でのデコード制御器へ進む可能性が高い。この制御器は、タスクの必要性と遅延上限に応じて、トークン順序、スキップするステップ、検証器の呼び出し、ブロックサイズ、キャッシュ動作を選ぶ。実用面では、拡散型言語モデルが自己回帰モデルを全面的に置き換えるのではなく、並列修正、制約付き生成、低遅延が重要なコーディング支援、文書編集、教育評価、構造化アシスタント、一部のマルチモーダルまたはエージェント型システムで有用になるだろう。
近い将来、適応的なトークン順序付けが十分に良くなると、主なボトルネックは配信効率になりそうだ。各リクエストが異なるマスク解除経路をたどり、異なる回数の修正ステップを使い、場合によって検証器も呼ぶと、処理のバッチ化やキャッシュ再利用が難しくなる。その結果、GPUを高い稼働率で使い続けることも難しくなる。今後1年の研究は、ブロック単位のマスク解除、疎な注意の制限、キャッシュが安定するマスクパターン、ステップを飛ばしても壊れにくい設計、コストを意識した目的関数など、ハードウェアを意識したデコードへ移るだろう。検証器は引き続き役立つが、正しさの向上が遅延コストに見合う場合に限って使われる。36か月後には、学習スケジュール、適応方針、検証器の信号、推論ランタイムを一体で設計するスタックに向かう可能性が高い。トークン順序は学習型または適応型のままだが、本番運用で予測可能な配信を実現する制約の内側で動き、用途はコード修復、文書改訂、教育評価支援、制約付きエージェント生成、マルチモーダル編集などの構造化かつ低遅延が必要な作業に集中するだろう。
近い進展では、適応的な拡散型言語モデルは、構造化出力の修復層として最も有用になるかもしれない。ここでいう検証器とは、コンパイラ、単体テスト、スキーマ検査器、方程式チェッカー、制約エンジンのように、出力のどこが不正かを示せる道具である。今後1年の研究では、検証器が作るマスクによって、モデルが単に最も自信のあるトークンから埋めるのではなく、正しさに重要な範囲を再訪できるかが試される。重要な問いは、総計算時間を公平に測ったとき、こうした正しさを意識した順序が信頼度だけのデコードを上回るかどうかである。36か月後には、単発のデコード技法から、修復の軌跡全体を設計する方向へ進むだろう。学習データ、検証器フィードバック、トークン順序方針、蒸留、キャッシュ動作、再マスク規則がまとめて設計される。実システムでは、適応的な拡散型言語モデルが、コーディングツール、文書システム、教育ソフト、エージェントループ、クラウドNLPサービス、マルチモーダル編集器の中で高速な並列修正エンジンとして働き、壊れた領域を見つけて複数の制約付き範囲を同時に直すことで、遅い逐次的な再試行を減らすだろう。
1年後・3年後の研究/応用インフォグラフィクス
参照論文
- Discrete Diffusion in Large Language and Multimodal Models: A Survey - 著者: Runpeng Yu, Qi Li, Xinchao Wang, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- Masked Diffusion Models are Secretly Learned-Order Autoregressive Models - 著者: Prateek Garg, Bhavya Kohli, Sunita Sarawagi, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- TABES: Trajectory-Aware Backward-on-Entropy Steering for Masked Diffusion Models - 著者: Shreshth Saini, Avinab Saha, Balu Adsumilli, Neil Birkbeck, Yilin Wang, Alan C. Bovik, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0