Summary
This week's theme centers on discrete and masked diffusion language models as an alternative to autoregressive LLMs, with particular emphasis on how decoding order shapes capability and efficiency. Representative papers frame token ordering, unmasking strategy, and inductive bias as core issues for these models, affecting reasoning quality, trainability, and the practical value of parallel generation.
Situation
The representative-paper introductions describe a field pushing beyond the autoregressive paradigm that still dominates large language and multimodal models. Autoregressive decoding is strong but intrinsically sequential, harder to parallelize, and less naturally suited to precise structural control or iterative revision. Discrete diffusion language models instead cast generation as iterative denoising over tokens, enabling bidirectional attention, parallel updates, and more controllable generation; recent work positions them as increasingly scalable and, at comparable scale, often competitive with autoregressive models while opening different efficiency and interaction trade-offs.
Within that broader shift, the scientific situation is increasingly defined by evaluation of decoding dynamics rather than model family alone. The introductions emphasize that masked diffusion models can be understood through any-order or learned-order autoregressive perspectives, making token ordering and unmasking policy central rather than incidental. Recent work focuses on whether confidence-based or greedy schedules are too myopic, how ordering affects future uncertainty and global consistency, and when diffusion's non-left-to-right inductive bias helps or hurts relative to autoregressive locality—especially on reasoning, planning, and other tasks with strong global dependencies.
Infographic (English)

Progress
DPRM: A Plug-in Doob h transform-induced Token-Ordering Module for Diffusion Language Models <See Details on Fugu-MT>
Introduces a plug-in token-ordering module (DPRM) for diffusion language models that transitions from confidence-driven progressive order to Doob h-transform reward-guided order, tested across seven host settings spanning language reasoning and scientific domains. Compared with the prior reliance on random or confidence-only unmasking, this provides a reward-aware ordering policy with theoretical sample-complexity advantages under stated tractability assumptions.
On the Trainability of Masked Diffusion Language Models via Blockwise Locality <See Details on Fugu-MT>
Analyzes masked diffusion language model trainability via controlled comparisons with autoregressive LLMs on three diagnostic tasks, and proposes two locality-aware blockwise architectures (Jigsaw and Scatter) that inject token-local left-to-right structure. Compared with the earlier broad debate over diffusion versus autoregressive decoding, this work pinpoints task-dependent trainability gaps—standard random-masking MDMs fail on linear regression but outperform AR models on Sudoku—and shows that aligning locality bias with task structure can narrow the gap.
Outlook
Outlook Summary
Near-term progress in diffusion language models is likely to focus on adaptive token ordering and decoding policies that go beyond confidence alone while staying practical at inference time. This week’s work supports plug-in reward-guided ordering, limited lookahead, better calibration of unmasking decisions, and post-training methods that handle irregular masked states. A related push is correctness-aware decoding, using lightweight verifiers, structural constraints, lower-variance schedules, caching, and schedule-agnostic training to improve the accuracy–latency tradeoff.
Infographic (English)

Three-Year Movement
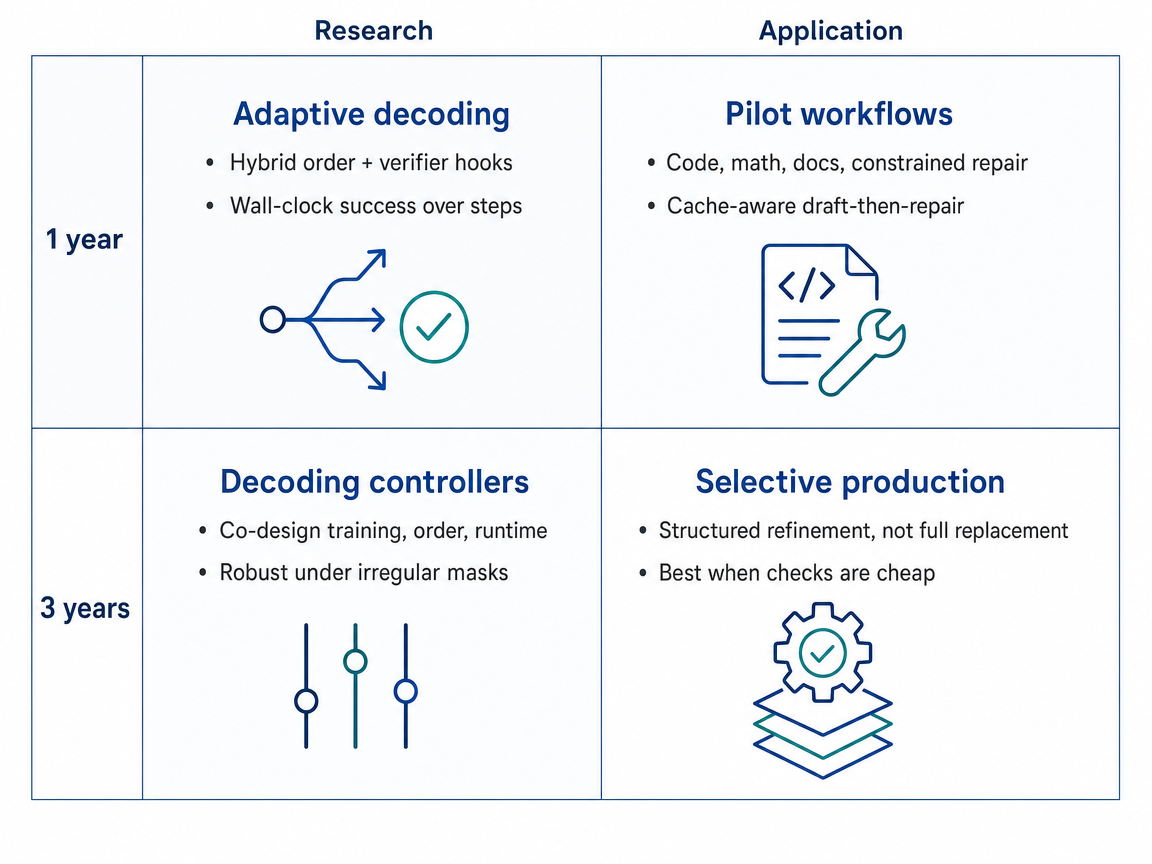
Over the next year, diffusion language model research is likely to turn adaptive decoding into a central optimization problem. Instead of using fixed reveal schedules, models will combine confidence, short lookahead, entropy reduction, schedule-agnostic training, and early correctness checks. The stronger results will need to show wall-clock gains, not only fewer decoding steps, on structured tasks such as code, math, long-context infill, constrained editing, and document synthesis. By 36 months, this points toward broader decoding controllers. A controller would choose token order, skipped steps, verifier calls, block size, and cache behavior based on task needs and latency limits. In practice, diffusion language models would not replace autoregressive models everywhere, but would become useful in workflows where parallel revision, constrained generation, and low latency matter, especially coding tools, document editing, educational assessment, structured assistants, and some multimodal or agentic systems.
Near-term work is likely to make adaptive token ordering good enough that serving efficiency becomes the main bottleneck. If each request follows a different unmasking path, uses a different number of refinement steps, or calls a verifier, it becomes harder to batch work, reuse cached computation, and keep GPUs fully used. Over the next year, research therefore shifts toward hardware-aware decoding, with block-level unmasking, sparse attention limits, cache-stable mask patterns, skipped-step robustness, and cost-aware objectives. Verifiers would still help, but only when their correctness gain is worth the latency cost. By 36 months, the likely movement is a co-designed stack where training schedules, adaptive policies, verifier signals, and inference runtimes are built together. Token order remains learned or adaptive, but inside constraints that make production serving predictable. Applications would focus on structured, latency-sensitive workflows such as code repair, document revision, educational assessment support, constrained agent generation, and multimodal editing, rather than fully free-form adaptivity everywhere.
Near-term progress is likely to make adaptive diffusion language models most useful as repair layers for structured outputs. A verifier, meaning a tool such as a compiler, unit test, schema checker, equation checker, or constraint engine, can mark where an output is invalid. Over the next year, research would test whether verifier-shaped masks help models revisit the spans that matter for correctness, instead of only filling the most confident tokens first. The key question is whether these correctness-aware orders beat confidence-only decoding when total compute time is measured fairly. By 36 months, the movement would be from single decoding tricks to full repair-trajectory design. Training data, verifier feedback, token-order policies, distillation, cache behavior, and remasking rules would be designed together. In real systems, adaptive diffusion language models would act as fast parallel refinement engines inside coding tools, document systems, education software, agent loops, cloud NLP services, and multimodal editors, reducing slow serial retry cycles by finding broken regions and repairing several constrained spans at once.
1-Year / 3-Year Research-Application Infographic
References
- Discrete Diffusion in Large Language and Multimodal Models: A Survey - Authors: Runpeng Yu, Qi Li, Xinchao Wang, / <See Details on Fugu-MT> / License: CC-BY-4.0
- Masked Diffusion Models are Secretly Learned-Order Autoregressive Models - Authors: Prateek Garg, Bhavya Kohli, Sunita Sarawagi, / <See Details on Fugu-MT> / License: CC-BY-4.0
- TABES: Trajectory-Aware Backward-on-Entropy Steering for Masked Diffusion Models - Authors: Shreshth Saini, Avinab Saha, Balu Adsumilli, Neil Birkbeck, Yilin Wang, Alan C. Bovik, / <See Details on Fugu-MT> / License: CC-BY-4.0