サマリー
今週の強化学習テーマは、カリキュラム設計とモジュール型スキル表現を通じて、エージェントがより豊かな行動を学習することに焦点を当てている。代表的な論文は、二つの関連するニーズを強調している:RLエージェントは同一タスクに対して複数の有効な行動を獲得すべきであること、そしてカリキュラム機構は大規模でオープンエンドなタスク空間を支えるのに十分な移植性とスケーラビリティを持つべきであることである。
テーマの状況
代表的な論文の導入部は共通の問題を提示している:標準的なRLポリシーは、多様な解が頑健性・適応性・変化する条件下での回復力を向上させる場合でも、単一の行動に収束しがちである。一つの研究方向はこの問題に対し、混合エキスパートポリシーと自動カリキュラム学習を組み合わせることで対処しており、異なるエキスパートが連続的なコンテキスト空間の好ましい領域に特化し、環境の境界に関する事前知識なしに複数のタスク解決モードを提供する。
第二の研究方向は、カリキュラム学習が既に多くの優れたRL成果の中核にあると主張する。特に大規模で進化する、あるいはオープンエンドなタスク空間を持つ環境においてそうであるが、カリキュラムロジックが訓練インフラと密結合しているため再利用が困難なままである。これにより、タスクのシーケンシングとポリシー最適化を分離するモジュール型カリキュラムシステムが動機付けられ、再現性の向上と多様なRLライブラリおよびより困難なドメインでの自動カリキュラムの活用を目指している。補足的なエビデンスも、継続的に拡張するスキルレパートリーへの方向性を示しており、単一ポリシー訓練から構造化されたスキル成長へのより広範なシフトを裏付けている。
- Acquiring Diverse Skills using Curriculum Reinforcement Learning with Mixture of Experts
- Syllabus: Portable Curricula for Reinforcement Learning Agents
- Guided Self-Evolving LLMs with Minimal Human Supervision
インフォグラフィクス(日本語)

今週の進展
SkillOS: Learning Skill Curation for Self-Evolving Agents <See Details on Fugu-MT>
SkillOSは、蓄積されたエージェント経験から外部スキルリポジトリを更新する学習型スキルキュレーターを導入し、自己進化する行動を可能にした。 固定的なマルチスキル構造や静的カリキュラムに依存するのではなく、成長するスキルセットの明示的な学習型キュレーションを追加し、メモリなしおよびメモリベースのベースラインに対する性能向上を報告している。
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning <See Details on Fugu-MT>
Skill1は、スキルの選択・活用・蒸留を共有タスク目標に向けて統合的に最適化する単一ポリシーを訓練する。 この統合最適化は、スキルライブラリ操作を別々のまたは競合する報酬信号で扱っていた従来のアプローチを置き換え、部分的または不整合なスキル進化を低減する。
Skill Neologisms: Towards Skill-based Continual Learning <See Details on Fugu-MT>
Skill Neologismsは、学習されたソフトトークンスキル表現が重み更新なしに分布外スキルと組み合わせ可能であることを示した。 既存の行動に対するカリキュラムと比較して、新しい構成的スキルトークンを独立に作成・再利用することで、スケーラブルな継続学習への道を示している。
今後の展望
今後の展望(要約)
近い将来の研究では、多様なスキルを持つ強化学習を、難しい制御問題でより使いやすくする方向に進む。具体的には、再計画、外乱を受けた後の回復、よりサンプル効率の高いオフポリシー学習が重視される。カリキュラム研究も、単なるタスク順序の調整から、長期タスクやマルチエージェント環境で意味のあるタスク軸を設計する方向へ移る。これらは、スキルを増やし、整理し、再利用し、選別するスキルライブラリの発展と結びつき、安定性、ドリフト、正規化の問題を扱う流れになる。
インフォグラフィクス(日本語)
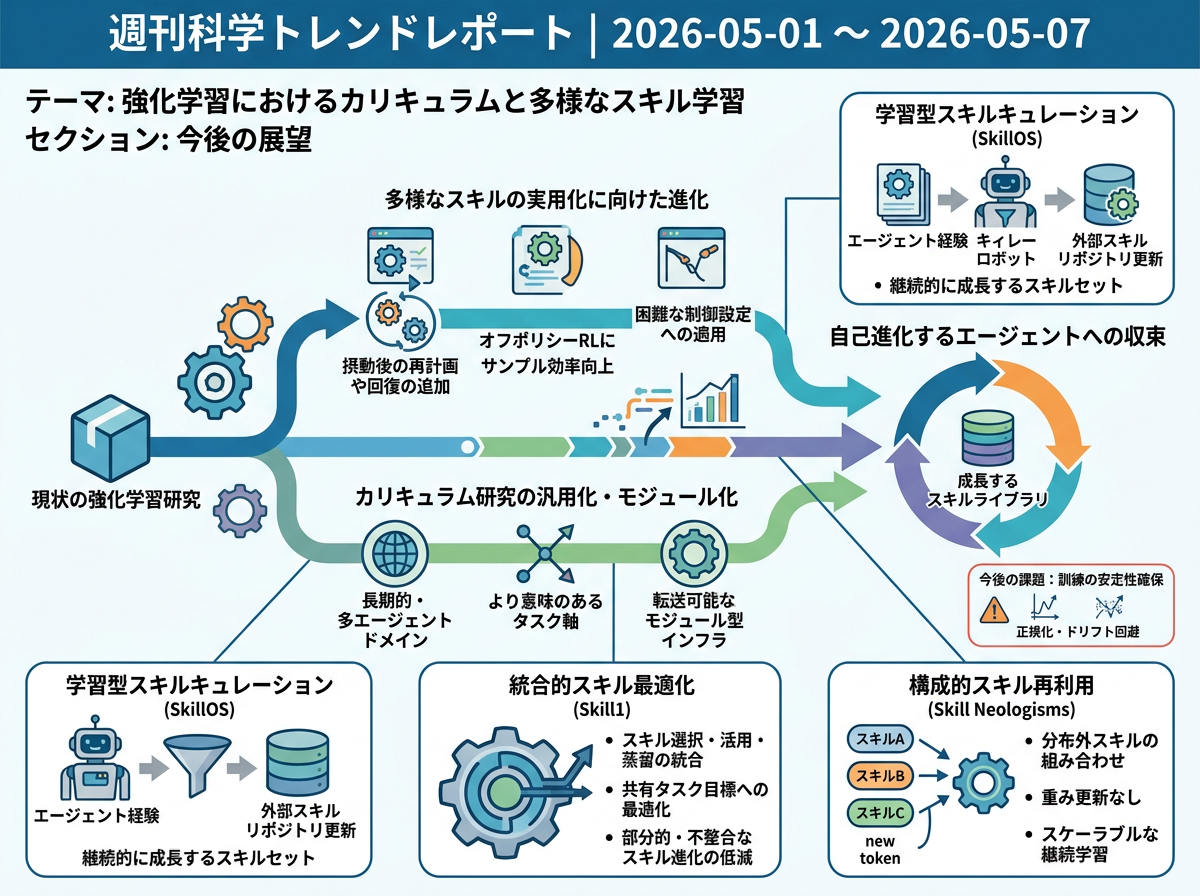
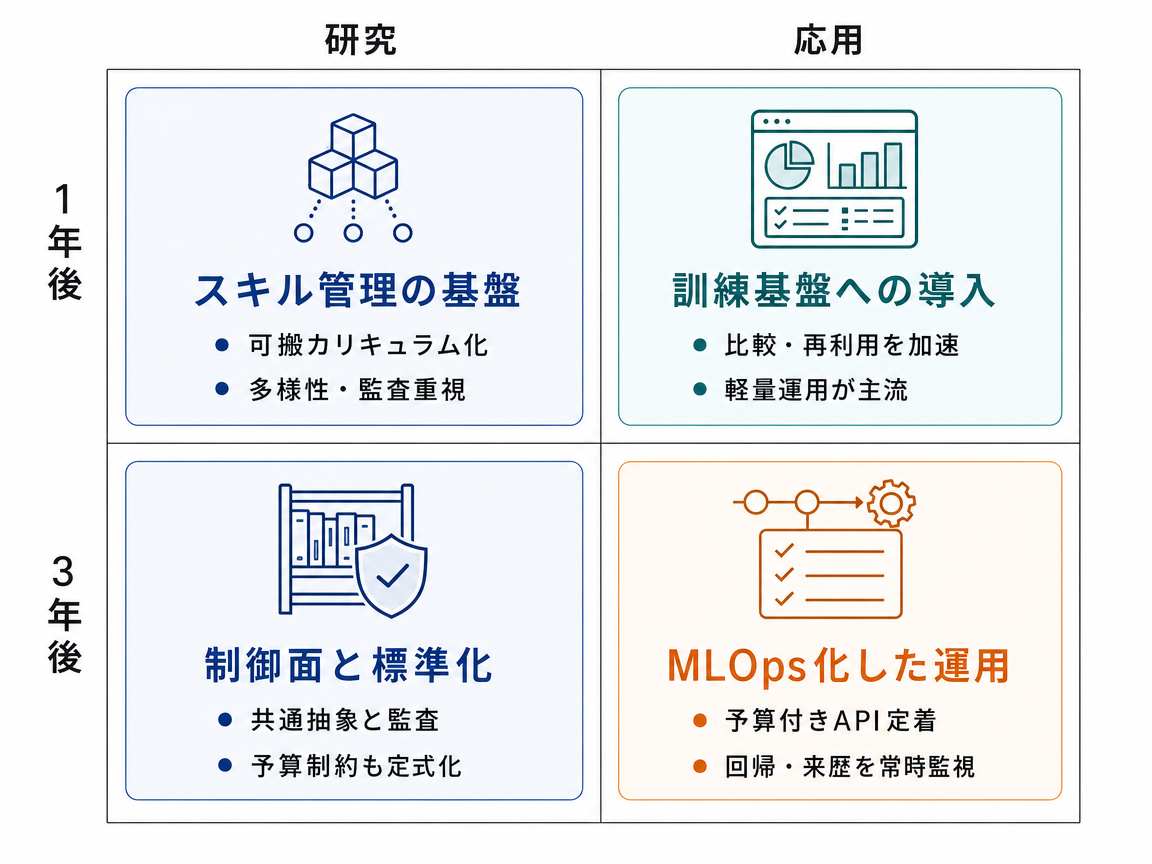
3年後を想定した動き
この標準シナリオでは、今後3年で研究ベンチマーク中心の段階から、適応的な強化学習を運用するための基盤づくりへ移る。1年目は、混合エキスパート型のカリキュラム、持ち運びやすいカリキュラムツール、自己進化型の訓練ループを、より難しい制御、長期タスク、マルチエージェント環境で主にストレステストする。評価も平均報酬だけでなく、多様性、頑健性、外乱後の回復、文脈カバレッジを測る方向に広がる。2年目には、タスクを選ぶカリキュラム生成器、状況を変える文脈サンプラー、方策を割り当てるエキスパートルーター、行動を保存するスキルリポジトリ、不安定化を検出するドリフト監視など、共通部品が見え始める。3年目には、研究室やプラットフォームチームが、カリキュラムやスキルライブラリを通常の機械学習資産のように、バージョン管理、テスト、比較、性能低下時のロールバック付きで扱う可能性がある。主な課題は、重複スキル、古くなったスキル、忘却、負の転移、変化するマルチエージェント条件になる。利用が強いのは、完全な実世界自律よりも、シミュレーション中心のロボティクス、オープンエンドなゲーム世界、ツール利用サンドボックス、複雑な意思決定訓練環境である。
この対抗シナリオでは、技術の方向性はほぼ同じだが、最大の制約がコストになる。1年目は、研究者は引き続き混合エキスパート型カリキュラム、移植しやすいカリキュラムシステム、自己進化型の訓練ループを発展させる。同時に、各エキスパートに個別のカリキュラムが必要になったり、各ソフトウェアアダプターを保守し続ける必要が出たりして、訓練コストと保守コストが大きく増えることも分かってくる。実務上の問いは、できるだけ大きなスキルライブラリを作ることから、固定されたGPU予算の中で有用な多様性をどう得るかに移る。3年後には、コストを意識したカリキュラム設計、単純で再現しやすいパイプライン、より安価なベースラインとの慎重な比較が重視される可能性が高い。ロボティクスシミュレーション、ゲームAI、エージェントベンチマークの応用チームは、再実行や監査が容易な場合、単一方策への蒸留、逐次カリキュラム、チェックポイント化されたスキルを好むかもしれない。スキルライブラリはなお重要だが、含まれる行動の数だけでなく、効率、保守しやすさ、再現性によって評価されるようになる。
この可能性シナリオでは、今後3年で多様なスキルを持つ強化学習が、訓練の問題であると同時に、来歴管理とテストの問題にもなる。1年目の出発点は、1つの壊れやすい行動だけを学ぶエージェントから、複数の行動を学び、外乱後の回復、オフポリシーのサンプル効率、コードベースをまたいで使えるカリキュラムツールを改善する方向への移行である。その結果、あるスキルがなぜ現れ、改善し、失敗し、崩壊したのかを知る必要が出てくる。そこでチームは、チェックポイントだけでなく、カリキュラムの選択、タスク文脈、エキスパート割り当て、リプレイデータ、人間が与えた基準点も記録し始める。3年後には、スキルライブラリに対する回帰テストが進み、エージェントは最高報酬だけでなく、多様性とカバレッジについても確認されるようになる可能性が高い。チェックポイントは、エージェントの得点だけを示すものではなく、そのスキルを生んだ訓練経路に関するメタデータも持つようになる。これにより、スキルがドリフトしたり、消えたり、狭くなりすぎたりしたときに、長期タスクを扱うエージェントを比較、デバッグ、保守しやすくなる。
1年後・3年後の研究/応用インフォグラフィクス
参照論文
- Acquiring Diverse Skills using Curriculum Reinforcement Learning with Mixture of Experts - 著者: Onur Celik, Aleksandar Taranovic, Gerhard Neumann / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- Syllabus: Portable Curricula for Reinforcement Learning Agents - 著者: Ryan Sullivan, Ryan Pégoud, Ameen Ur Rahmen, Xinchen Yang, Junyun Huang, Aayush Verma, Nistha Mitra, John P. Dickerson, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- Guided Self-Evolving LLMs with Minimal Human Supervision - 著者: Wenhao Yu, Zhenwen Liang, Chengsong Huang, Kishan Panaganti, Tianqing Fang, Haitao Mi, Dong Yu, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0