Summary
This theme centers on how LLM outputs can be attributed to supporting documents so that generated answers are more transparent, verifiable, and trustworthy. The representative papers frame attribution as both a modeling problem and an evaluation problem: they study retrieval-free citation from pretraining data, zero-shot document attribution via entailment-style prompting, and interfaces that help users critically inspect cited answers.
Situation
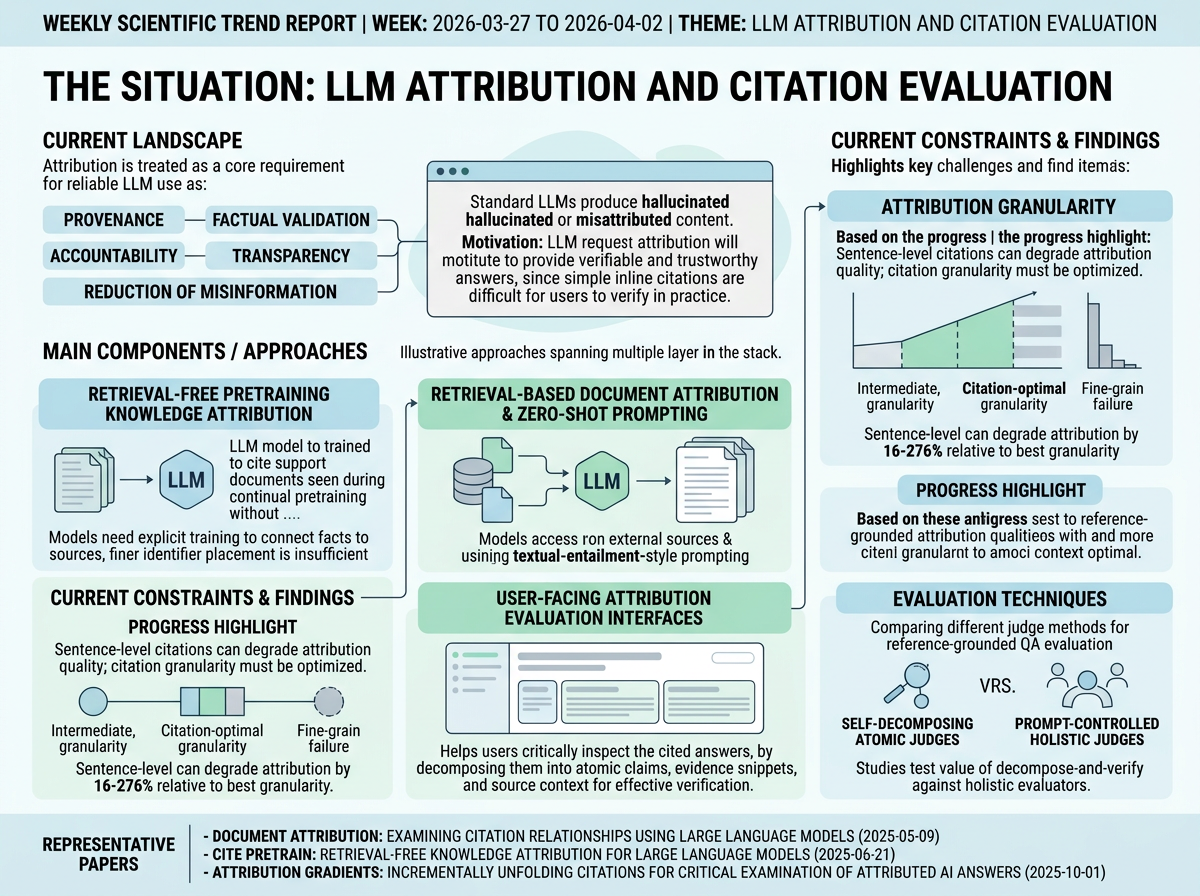
Recent work treats attribution as a core requirement for reliable LLM use, especially as models are asked to answer questions with citations. The shared motivation is that standard LLMs often produce hallucinated or misattributed content, while simple inline citations can be difficult for users to verify in practice. Across the papers, attribution is presented as necessary for provenance, factual validation, accountability, transparency, and reduction of misinformation.
The representative approaches span multiple layers of the stack. One line asks whether models can be trained to cite documents seen during continual pretraining without external retrieval, arguing that finer identifier placement alone is insufficient and that models need explicit training to connect paraphrased or compositional facts back to sources. Another examines document attribution with zero-shot textual-entailment-style prompting and attention-based classification. A third shifts to user-facing evaluation, arguing that cited AI answers require support for moving from answer to atomic claims, evidence snippets, and source context so users can more effectively examine whether citations truly support the response.
Infographic (English)
Progress
Are Finer Citations Always Better? Rethinking Granularity for Attributed Generation <See Details on Fugu-MT>
This paper demonstrates that citation granularity must be optimized rather than simply made finer, finding that sentence-level citations can degrade attribution quality by 16–276% relative to the best granularity. Whereas prior work focused on enabling citation capability, this study shows that an intermediate, citation-optimal granularity preserves answer correctness while substantially improving attribution quality.
Rethinking Atomic Decomposition for LLM Judges: A Prompt-Controlled Study of Reference-Grounded QA Evaluation <See Details on Fugu-MT>
This paper compares self-decomposing atomic judges against prompt-controlled holistic judges for reference-grounded QA evaluation. Whereas atomic claim decomposition has been assumed to improve evaluation, this study directly tests whether single-prompt decompose-and-verify judges add value over equally detailed holistic evaluators.
Outlook
Near-term progress in LLM attribution is likely to focus on making evaluation and citation structure more discriminating rather than simply finer-grained. This week's findings suggest that sentence-level citation is not always optimal and that atomic decomposition should be compared against equally controlled holistic judging. A natural next step is better-calibrated evaluation pipelines that systematically compare citation granularities and claim decomposition strategies, ideally incorporating more human validation to reduce noise from automatic judges.
On the modeling side, the representative papers point toward scaling retrieval-free attribution methods to larger models and more diverse corpora, exploring hybrid designs that combine internal citation with retrieval when model confidence is low, and improving the quality filtering of synthetic training data used for active indexing. User-facing work is expected to continue enriching the information exposed beyond simple inline citations, helping readers inspect support, contradiction, and broader context more effectively.
Infographic (English)

References
- Document Attribution: Examining Citation Relationships using Large Language Models - Authors: Vipula Rawte, Ryan A. Rossi, Franck Dernoncourt, Nedim Lipka, / <See Details on Fugu-MT> / License: CC-BY-4.0
- Cite Pretrain: Retrieval-Free Knowledge Attribution for Large Language Models - Authors: Yukun Huang, Sanxing Chen, Jian Pei, Manzil Zaheer, Bhuwan Dhingra, / <See Details on Fugu-MT> / License: CC-BY-4.0
- Attribution Gradients: Incrementally Unfolding Citations for Critical Examination of Attributed AI Answers - Authors: Hita Kambhamettu, Alyssa Hwang, Philippe Laban, Andrew Head, / <See Details on Fugu-MT> / License: CC-BY-4.0