Summary
This week's papers focus on making LLM agents more reliable on complex, long-horizon tasks by improving how they store, extract, share, and secure knowledge. The common diagnosis is that isolated agents and one-shot memory pipelines lose important context, while active extraction, cross-agent experience reuse, and shared execution histories offer paths toward more adaptive problem solving.
Situation
The representative introductions describe a shift from viewing LLM agents as standalone reasoners toward treating them as systems that need structured memory and collaboration. AutoGen motivates multi-agent conversation as a general way to decompose difficult tasks, combine complementary capabilities from differently configured agents, and incorporate tools or humans through a unified conversational interface.
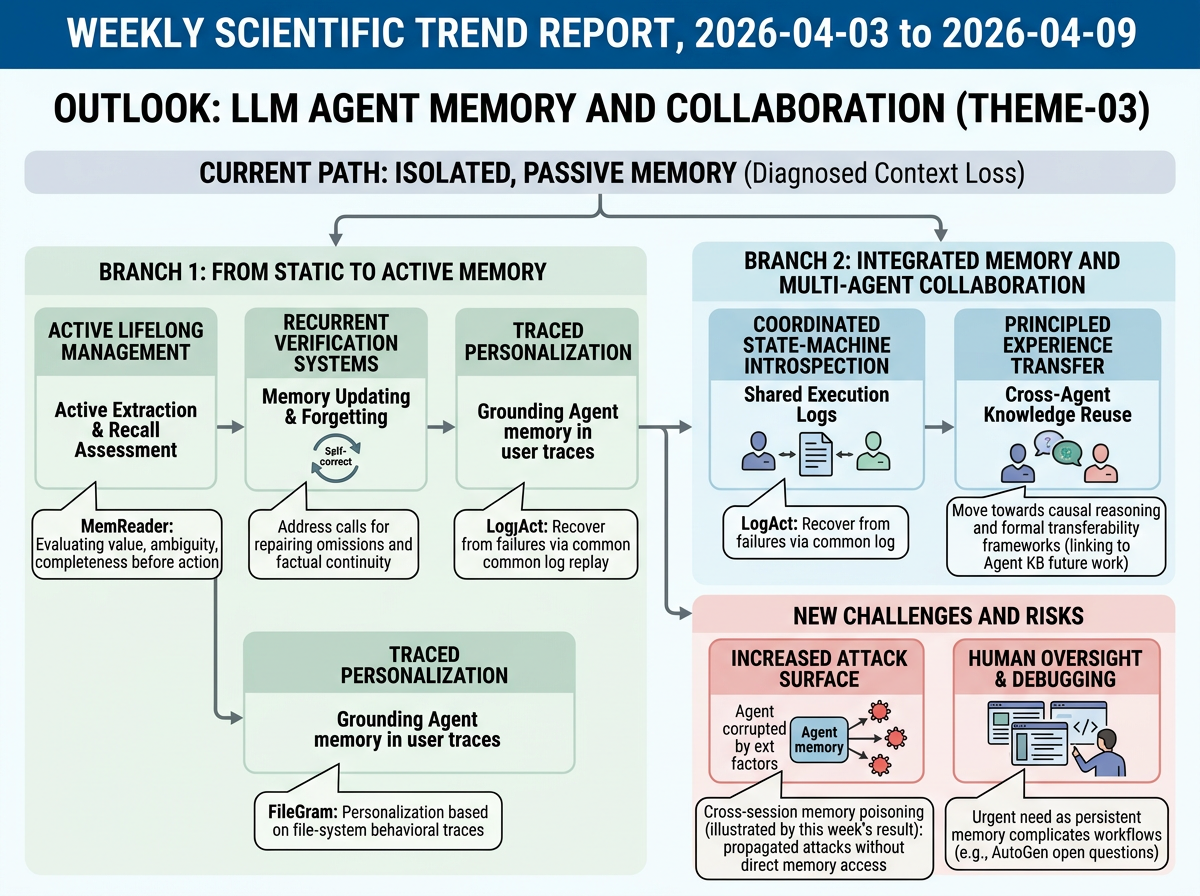
The newer agent-memory papers argue that current memory and experience mechanisms are still too brittle for real-world agentic work. Agent KB highlights that agents often remain trapped in task-specific, isolated memories and cannot transfer successful strategies across domains. Proactive memory extraction argues that ahead-of-time, one-off summarization discards small but important details and can preserve hallucinated facts. Together, these papers frame the current situation as a move toward iterative, feedback-driven, and cross-agent knowledge reuse rather than static storage or purely self-contained reasoning.
Infographic (English)

Progress
FileGram: Grounding Agent Personalization in File-System Behavioral Traces <See Details on Fugu-MT>
FileGram grounds agent personalization in file-system behavioral traces, coupling memory with observable user activity. Unlike generic memory stores, it builds an open framework specifically around trace-based personalization for file-system agents.
MemReader: From Passive to Active Extraction for Long-Term Agent Memory <See Details on Fugu-MT>
MemReader advances long-term agent memory by shifting from passive storage to active extraction that evaluates information value, referential ambiguity, and completeness before action. Compared with one-shot summarization pipelines, it introduces an explicit pre-action assessment step to filter and prioritize what enters memory.
MemMachine: A Ground-Truth-Preserving Memory System for Personalized AI Agents <See Details on Fugu-MT>
MemMachine introduces a persistent memory system that unifies short-term, long-term, and profile memory for personalized agents. It uses contextualized retrieval to expand memory nuclei with surrounding context, improving recall when relevant evidence spans multiple conversations.
LogAct: Enabling Agentic Reliability via Shared Logs <See Details on Fugu-MT>
LogAct extends the theme from individual memory to shared execution logs for multi-agent reliability. Agents replay a common log to recover from failures and self-debug, replacing isolated reasoning with coordinated state-machine introspection.
Poison Once, Exploit Forever: Environment-Injected Memory Poisoning Attacks on Web Agents <See Details on Fugu-MT>
This paper exposes persistent agent memory as a cross-session security vulnerability in web agents. It demonstrates environment-injected memory poisoning that propagates across sites and sessions without requiring direct memory access.
Outlook
Near-term work will likely push agent memory from static summaries toward active, lifelong management. This week's progress on active extraction, contextualized cross-conversation retrieval, and trace-based personalization aligns with representative papers' calls for recurrent verification and updating-and-forgetting mechanisms, pointing toward memory systems that continuously assess information value, repair omissions, and maintain factual continuity over long horizons.
A second direction is tighter integration of memory with multi-agent collaboration. Shared execution logs and cross-agent knowledge reuse move toward more principled experience transfer, consistent with Agent KB's future work on causal reasoning and formal transferability frameworks. At the same time, AutoGen's open questions on workflow debugging and human oversight grow more pressing as persistent memory enlarges the attack surface—a risk concretely illustrated by this week's cross-session poisoning result.
Infographic (English)
References
- AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation Framework - Authors: Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang / <See Details on Fugu-MT> / License: CC-BY-4.0
- Beyond Static Summarization: Proactive Memory Extraction for LLM Agents - Authors: Chengyuan Yang, Zequn Sun, Wei Wei, Wei Hu, / <See Details on Fugu-MT> / License: CC-BY-4.0