サマリー
今週の代表的論文は、Mixture-of-Experts(MoE)アーキテクチャとより賢い事前学習データ混合設計を通じて、大規模言語モデルをいかに効率的にスケールさせるかに取り組んでいる。共通の目標は、MoEの初期化・ルーティング機構・データ混合選択を改善することで、LLM開発におけるデータ・計算・最適化コストを削減することである。
テーマの状況
言語モデルはスケールの恩恵を受け続けているが、密なアーキテクチャは計算量・データ要件・学習コストの面で限界が拡大している。Mixture-of-Experts(MoE)モデルは、入力ごとにエキスパートの一部のみを活性化する条件付き計算によってパラメータ容量を増加させることでこの問題に対処しており、一方で事前学習データセットはますます多様化し、ドメインサンプリングの選択に敏感になっている。
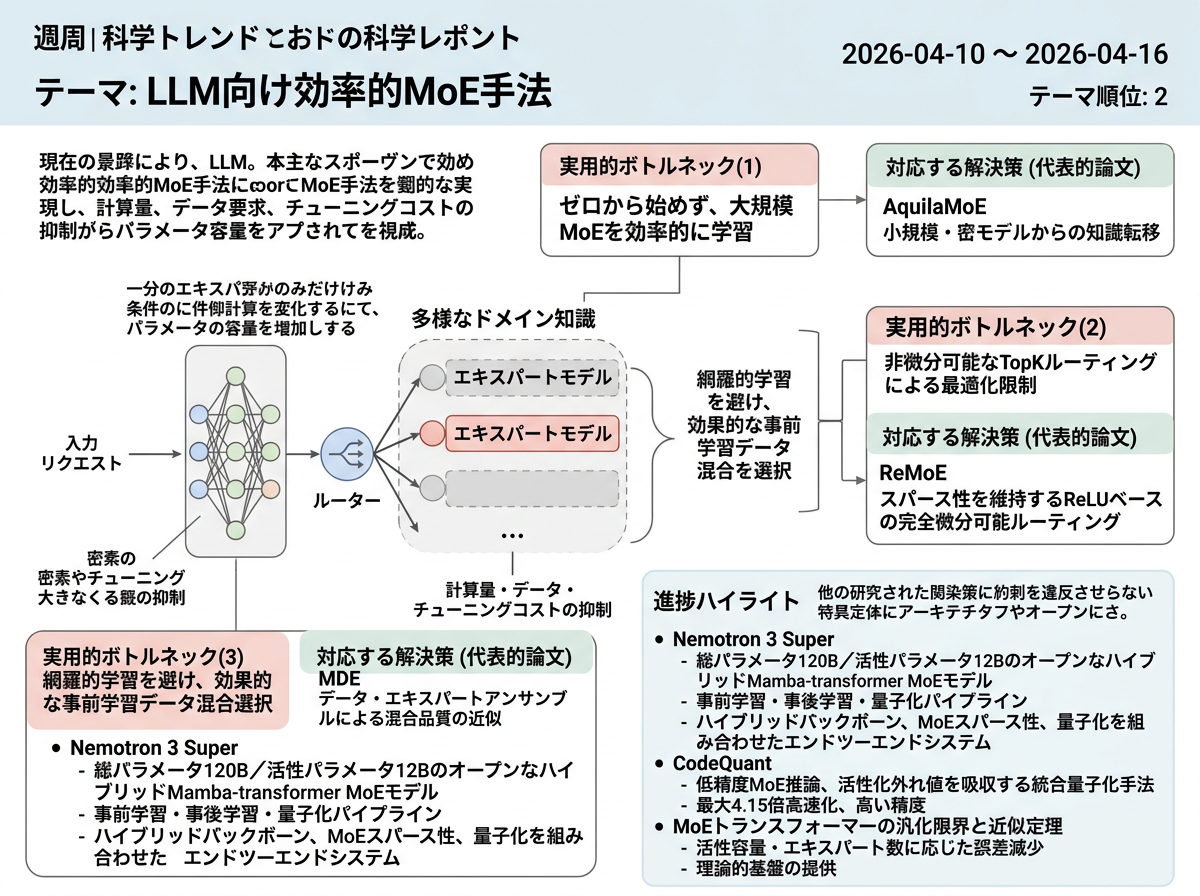
この状況において、代表的論文は3つの実用的なボトルネックを特定している。すなわち、ゼロから始めずに大規模MoEシステムを効率的に学習すること、最適化を制限する非微分可能なTopKルーティングを克服すること、そして多数のプロキシモデルを網羅的に学習せずに効果的な事前学習データ混合を選択することである。対応する解決策として、小規模または密なモデルからの知識転移によるMoE初期化(AquilaMoE)、スパース性を維持しつつ完全微分可能なReLUベースのルーティング(ReMoE)、および単一ドメインのプロキシモデルから混合品質を近似するデータ・エキスパートアンサンブル(MDE)が提案されている。
- AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
- ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing
- Optimizing Pre-Training Data Mixtures with Mixtures of Data Expert Models
インフォグラフィクス(日本語)
今週の進展
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning <See Details on Fugu-MT>
Nemotron 3 Superを提示。総パラメータ120B/活性パラメータ12BのオープンなハイブリッドMamba-attention MoEモデルであり、事前学習・事後学習・量子化パイプラインが文書化されている。 MoEの初期化とルーティングに関する先行研究を拡張し、ハイブリッドバックボーンとMoEスパース性およびデプロイ可能な量子化を組み合わせたエンドツーエンドシステムへと発展させている。
CodeQuant: Unified Clustering and Quantization for Enhanced Outlier Smoothing in Low-Precision Mixture-of-Experts <See Details on Fugu-MT>
CodeQuantを導入。活性化の外れ値を微調整されたクラスタ重心に吸収する統合的な量子化・クラスタリング手法であり、低精度MoE推論を実現する。 MoEテーマに推論時の効率性という次元を追加し、従来のMoE量子化手法より高い精度で最大4.15倍の高速化を報告している。
Generalization and Scaling Laws for Mixture-of-Experts Transformers <See Details on Fugu-MT>
MoEトランスフォーマーの汎化限界および合成近似定理を導出し、活性容量とエキスパート数に応じて誤差が減少することを示した。 代表的論文で記述された経験的なMoEスケーリング戦略に対して、新たな理論的基盤を提供している。
今後の展望
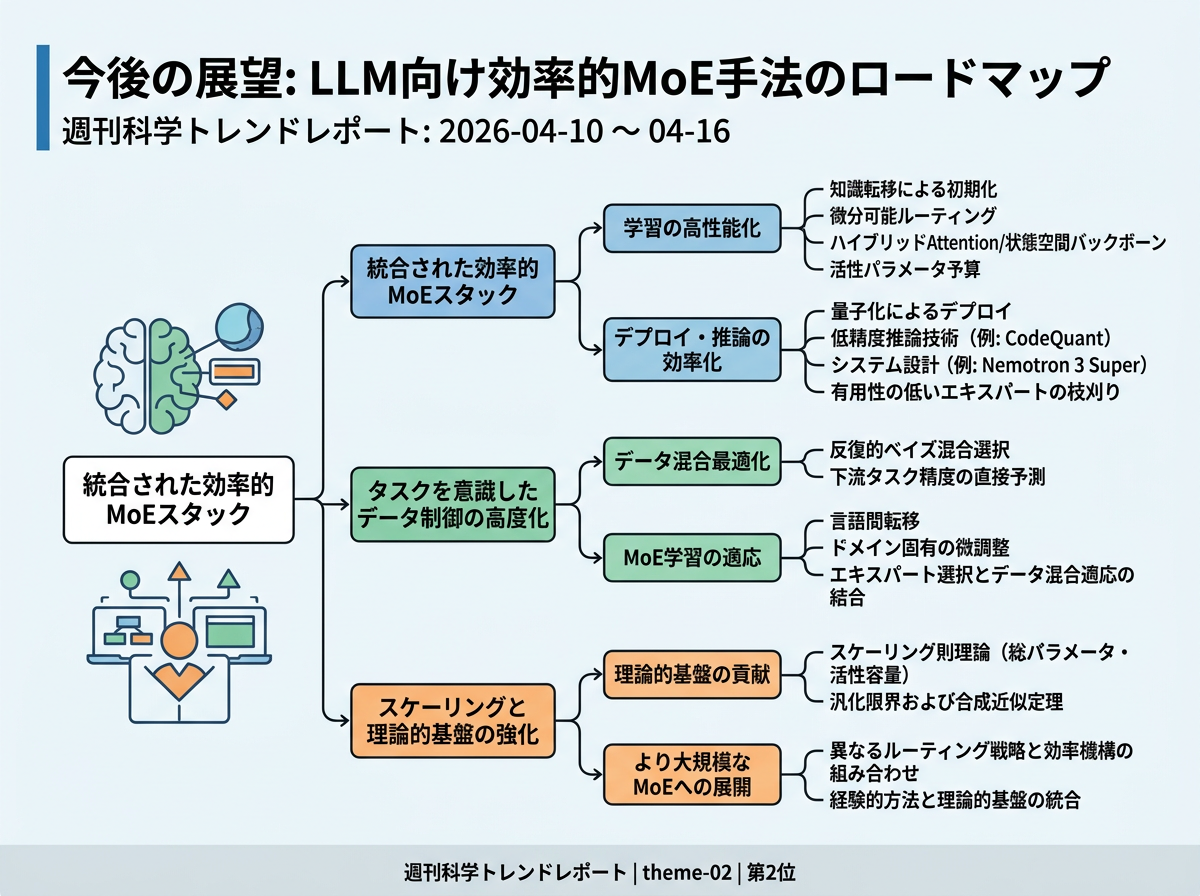
最も具体的な短期的方向性は、より統合された効率的MoEスタックである。知識転移による初期化と微分可能ルーティングで学習されたモデルを、ハイブリッドattention/状態空間バックボーン上で量子化を通じてデプロイするというものである。代表的論文の今後の課題では、より大規模なMoEへのスケーリング、ReMoEスタイルのルーティングと効率的なアテンションやメモリ機構の組み合わせ、および有用性の低いエキスパートの枝刈りが明示的に目標とされている。今週の進展は、エンドツーエンドのシステム設計(Nemotron 3 Super)、低精度推論技術(CodeQuant)、および活性パラメータ予算に関する形式的なスケーリング則理論の貢献により、この方向性を強化している。
第二の方向性は、MoEモデルが何から学習するかに対する、よりタスクを意識した制御である。データ混合最適化の研究は、反復的ベイズ混合選択や下流タスク精度の直接予測を志向しており、MoE学習の論文では言語間転移やドメイン固有の微調整が言及されている。これらを総合すると、今後の研究ではエキスパート選択とデータ混合適応を結合し、スケーリングによる性能向上がより確実に下流タスクの性能に反映されるようになる可能性が高い。
インフォグラフィクス(日本語)
参照論文
- AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies - 著者: Bo-Wen Zhang, Liangdong Wang, Ye Yuan, Jijie Li, Shuhao Gu, Mengdi Zhao, Xinya Wu, Guang Liu, Chengwei Wu, Hanyu Zhao, Li Du, Yiming Ju, Quanyue Ma, Yulong Ao, Yingli Zhao, Songhe Zhu, Zhou Cao, Dong Liang, Yonghua Lin, Ming Zhang, Shunfei Wang, Yanxin Zhou, Min Ye, Xuekai Chen, Xinyang Yu, Xiangjun Huang, Jian Yang, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing - 著者: Ziteng Wang, Jianfei Chen, Jun Zhu, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- Optimizing Pre-Training Data Mixtures with Mixtures of Data Expert Models - 著者: Lior Belenki, Alekh Agarwal, Tianze Shi, Kristina Toutanova, / <See Details on Fugu-MT> / ライセンス: CC-BY-SA-4.0