Summary
This week's representative papers address how to scale large language models more efficiently through mixture-of-experts architectures and smarter pre-training data-mixture design. The shared goal is to reduce the data, compute, and optimization cost of LLM development by improving MoE initialization, routing mechanisms, and data-mixture selection.
Situation
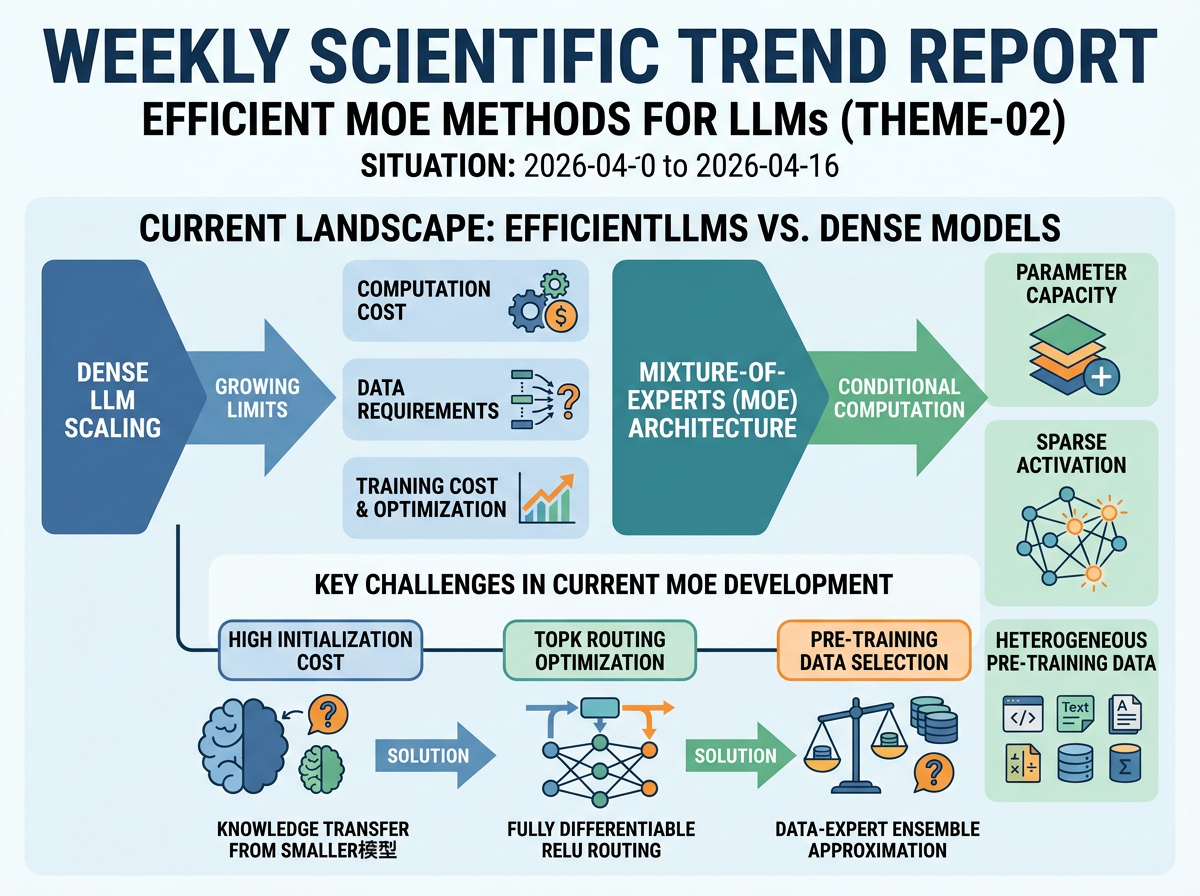
Language models continue to benefit from scale, but dense architectures face growing limits in computation, data requirements, and training cost. Mixture-of-experts (MoE) models address this by increasing parameter capacity through conditional computation—activating only a subset of experts per input—while pre-training datasets are increasingly heterogeneous and sensitive to domain-sampling choices.
Within that setting, the representative papers identify three practical bottlenecks: efficiently training large MoE systems without starting from scratch, overcoming the non-differentiable TopK routing that limits optimization, and selecting effective pre-training data mixtures without exhaustively training many proxy models. The corresponding solutions are knowledge transfer from smaller or dense models to initialize larger MoE systems (AquilaMoE), fully differentiable ReLU-based routing that preserves sparsity (ReMoE), and a data-expert ensemble that approximates mixture quality from single-domain proxy models (MDE).
Infographic (English)
Progress
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning <See Details on Fugu-MT>
Presents Nemotron 3 Super, an open 120B-total / 12B-active hybrid Mamba-attention MoE model with documented pre-training, post-training, and quantization pipelines. Extends earlier work on MoE initialization and routing toward an end-to-end system that combines a hybrid backbone with MoE sparsity and deployment-ready quantization.
CodeQuant: Unified Clustering and Quantization for Enhanced Outlier Smoothing in Low-Precision Mixture-of-Experts <See Details on Fugu-MT>
Introduces CodeQuant, a unified quantization-and-clustering scheme that absorbs activation outliers into fine-tuned cluster centroids for low-precision MoE inference. Adds an inference-time efficiency dimension to the MoE theme, reporting up to 4.15× speedup with higher accuracy than prior MoE quantization methods.
Generalization and Scaling Laws for Mixture-of-Experts Transformers <See Details on Fugu-MT>
Derives generalization bounds and compositional approximation theorems for MoE transformers, showing that error decreases with active capacity and expert count. Provides new theoretical grounding for the empirically driven MoE scaling strategies described in the representative papers.
Outlook
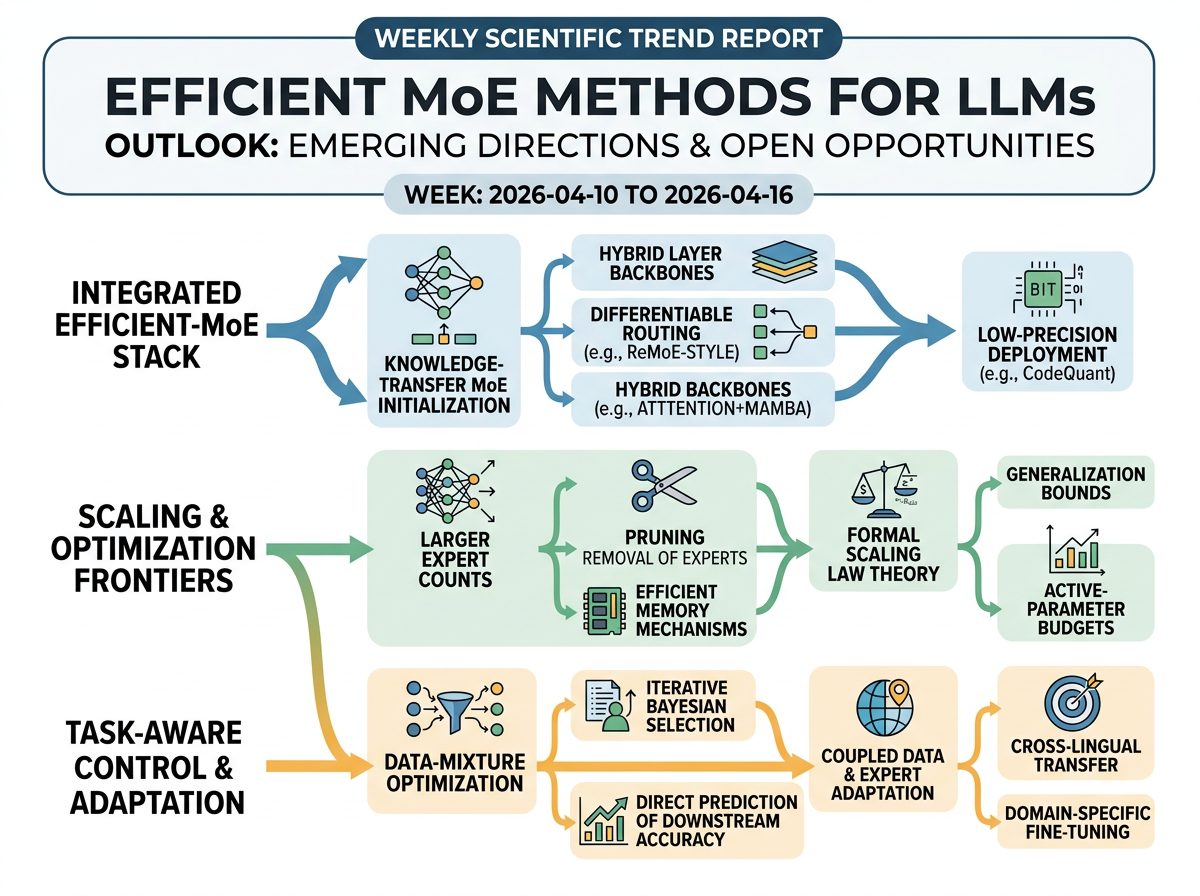
The most concrete near-term direction is a more integrated efficient-MoE stack: models trained with knowledge-transfer initialization and differentiable routing, then deployed through quantization on hybrid attention/state-space backbones. The representative papers' future work explicitly targets scaling to larger MoEs, combining ReMoE-style routing with efficient attention or memory mechanisms, and pruning less-useful experts. This week's progress reinforces that trajectory by contributing end-to-end system design (Nemotron 3 Super), low-precision inference techniques (CodeQuant), and formal scaling-law theory for active-parameter budgets.
A second direction is more task-aware control of what MoE models learn from. The data-mixture optimization work points toward iterative Bayesian mixture selection and direct prediction of downstream task accuracy, while the MoE training papers mention cross-lingual transfer and domain-specific fine-tuning. Together, these suggest that upcoming work will likely couple expert selection with data-mixture adaptation so that scaling gains translate more reliably into downstream performance.
Infographic (English)
References
- AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies - Authors: Bo-Wen Zhang, Liangdong Wang, Ye Yuan, Jijie Li, Shuhao Gu, Mengdi Zhao, Xinya Wu, Guang Liu, Chengwei Wu, Hanyu Zhao, Li Du, Yiming Ju, Quanyue Ma, Yulong Ao, Yingli Zhao, Songhe Zhu, Zhou Cao, Dong Liang, Yonghua Lin, Ming Zhang, Shunfei Wang, Yanxin Zhou, Min Ye, Xuekai Chen, Xinyang Yu, Xiangjun Huang, Jian Yang, / <See Details on Fugu-MT> / License: CC-BY-4.0
- ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing - Authors: Ziteng Wang, Jianfei Chen, Jun Zhu, / <See Details on Fugu-MT> / License: CC-BY-4.0
- Optimizing Pre-Training Data Mixtures with Mixtures of Data Expert Models - Authors: Lior Belenki, Alekh Agarwal, Tianze Shi, Kristina Toutanova, / <See Details on Fugu-MT> / License: CC-BY-SA-4.0