サマリー
今週の論文群は、先進的な動画およびマルチモーダル生成システムを単なるコンテンツ生成器ではなく、新たな世界モデルとして位置づけている。共通する焦点は、状態とダイナミクスをより明示的に表現すること、生のピクセル予測を超えた不確実性の扱い、そしてエージェント的世界モデリングのための能力レベルの体系化にある。
テーマの状況
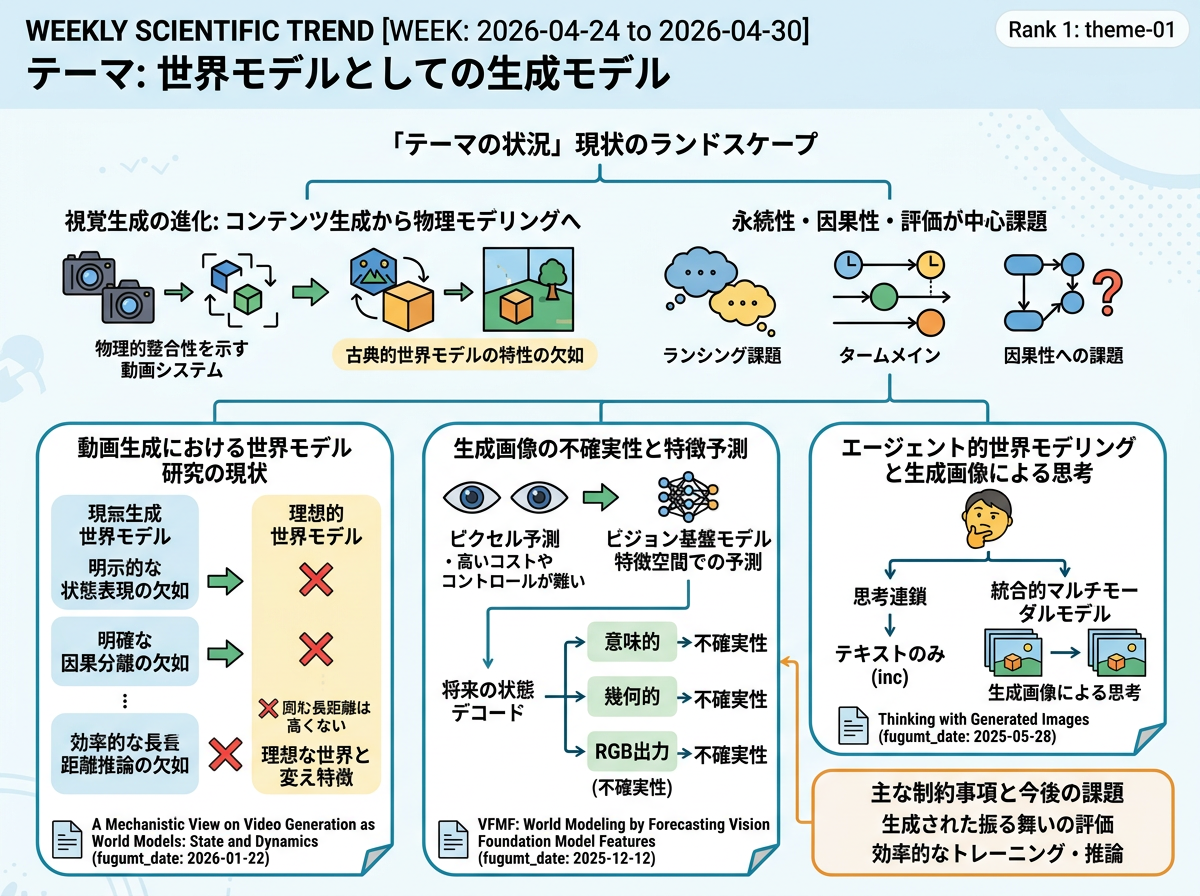
代表的な論文群は、視覚生成がリアルな出力の生成からシーンや環境の変化のモデリングへと移行していることを示している。動画生成に関するサーベイでは、近年のシステムが物理的整合性を示すことから世界モデルに近づきつつあると論じる一方、古典的な世界モデルの重要な特性——明示的な状態表現、明確な因果分離、効率的な長距離推論——がいまだ欠如していると指摘している。このため、永続性、因果性、および生成された振る舞いの評価が中心的な課題となっている。
他の論文は、代替的な表現や推論形式を通じてこの課題に取り組んでいる。一つの論文は、ピクセル予測が多くの場合不必要にコストが高く直接的に行動に結びつかないと主張し、ビジョン基盤モデルの特徴空間における確率的予測を提案している。これにより、将来の状態を意味的・幾何的・RGB出力にデコードしつつ不確実性の認識を保持できる。別の論文は、テキストのみの思考連鎖では問題解決の一部しか捉えられないと主張し、統合的なマルチモーダルモデルが推論過程の一部として視覚的な中間ステップを生成する「生成画像による思考」を提案している。
- Thinking with Generated Images
- VFMF: World Modeling by Forecasting Vision Foundation Model Features
- A Mechanistic View on Video Generation as World Models: State and Dynamics
インフォグラフィクス(日本語)
今週の進展
Visual Generation in the New Era: An Evolution from Atomic Mapping to Agentic World Modeling <See Details on Fugu-MT>
視覚生成を原子的マッピングからエージェント的世界モデリングまでの5段階の進化として定式化し、各段階の主要な技術的推進要因を特定している。 動画モデルが世界モデルに近似するという一般的な見解を超え、生成能力のレベルを区別する体系的な分類法を提示している。
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond <See Details on Fugu-MT>
エージェント的世界モデルの3つの能力レベル——局所予測器、ドメイン法則を遵守するマルチステップシミュレータ、自己修正型エボルバ——を定義している。 行動条件付きロールアウトとモデル修正を中心に構築された明示的な階層構造を導入し、因果構造の欠如に関する従来の議論をより精緻化している。
GenMatter: Perceiving Physical Objects with Generative Matter Models <See Details on Fugu-MT>
低レベルの動き手がかりと高レベルの外観特徴をパーティクルにグループ化し、移動可能な物理オブジェクトを表現する生成モデルを提案している。 オブジェクトごとの分解を欠くシーンレベルの生成と比較して、より明示的な物理的状態表現に向けて前進している。
今後の展望
今後の展望(要約)
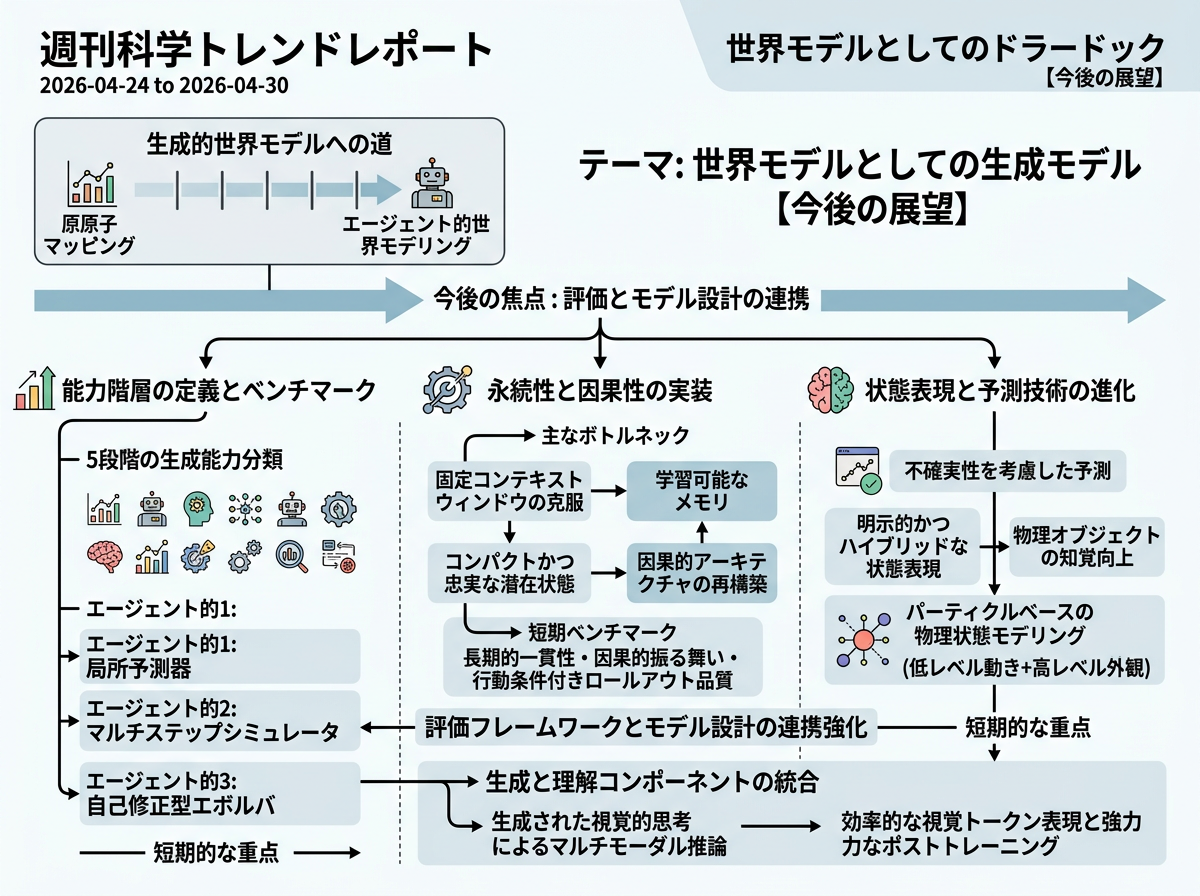
生成型ワールドモデルの次の段階では、評価方法とモデル設計をより強く結びつける流れが進みそうです。主な課題は、見た目のリアルさだけでなく、状態の持続性、因果関係、長い時間幅での一貫性、行動を条件にした将来予測の品質です。近い将来のベンチマークは、モデルが状態を保てるか、因果的なふるまいを扱えるか、実用的な未来の展開を生成できるかを試すものになるでしょう。研究面では、明示的またはハイブリッドな状態表現、不確実性を考慮した予測、固定長コンテキストを超える学習済みメモリ、生成と理解のより密な統合が重要になります。生成された視覚的思考を使うマルチモーダル推論の進展も、効率的な視覚トークンと、より強い事後学習手法に左右されます。
インフォグラフィクス(日本語)
3年後を想定した動き
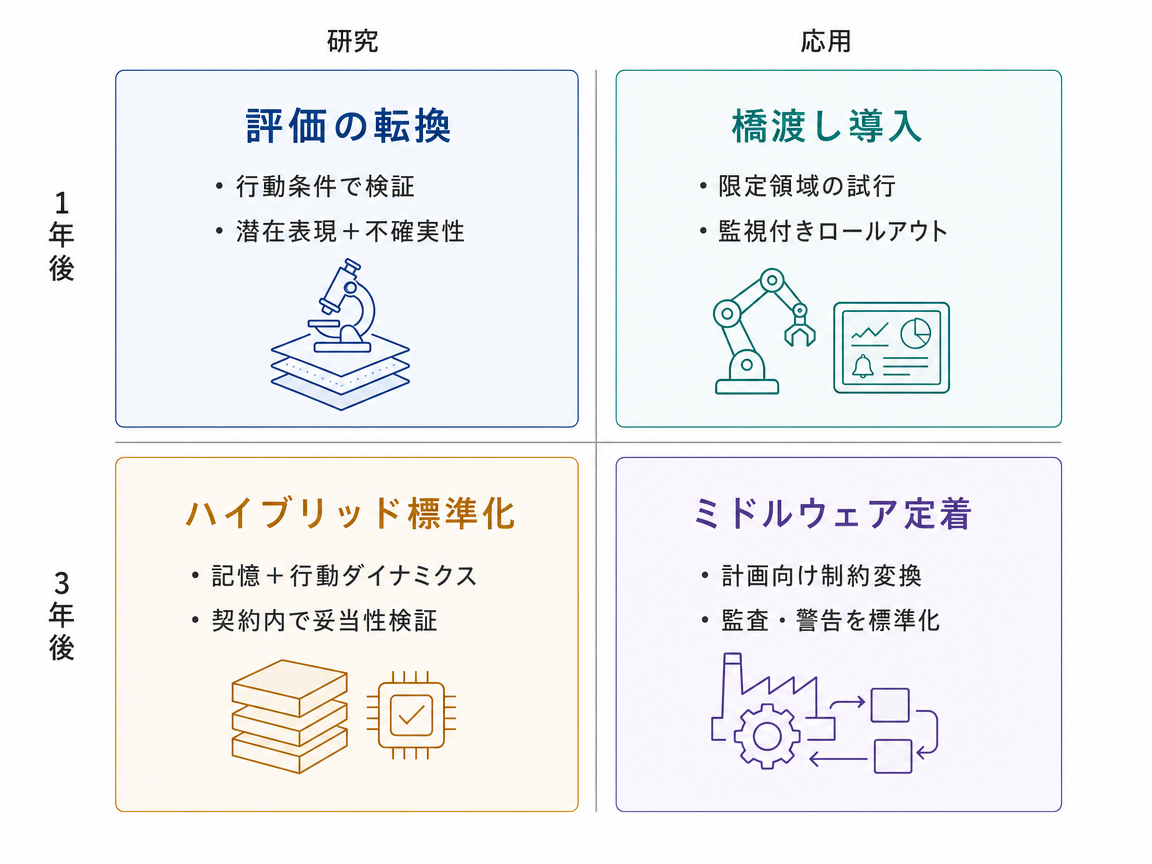
今後1年ほどは、ワールドモデルの評価基準が、画像や動画がどれだけ本物らしく見えるかだけではなく、状態、因果関係、行動に応じた変化を追跡できるかに移っていく可能性が高いです。特徴空間での予測、生成された視覚的思考、動画モデルの機械的な評価は、どれもこの方向を後押ししています。約36か月後には、強いシステムほど構成が標準化されていくでしょう。つまり、世界を圧縮して表す潜在状態、持続的なメモリ、行動条件付きのダイナミクス、因果性を調べるテストを組み合わせる形です。中心的な問いは、もっともらしい未来を想像できるかではなく、その内部状態が介入、反事実、信頼できるタスク結果を支えられるかに移ります。応用面では、ロボット方策のテスト、デジタルツイン、自動設計探索、仮想訓練、AI安全性評価の中に、範囲を限定したシミュレーション部品として組み込まれる可能性が高いです。ただし、計算コスト、不完全な因果性、長期予測のずれは残るため、行動、状態変数、予測の長さ、成功指標が明確に定義された場面で最も有効に働くでしょう。
近い将来の研究では、評価とモデル設計を結びつける流れが続く一方で、実用上のボトルネックは他のシステムから使いやすいかどうかになるかもしれません。プランナー、ロボット、シミュレータ、意思決定支援ツールが必要とするのは、もっともらしい未来の生成だけではありません。実際の誤差と合った信頼度、つまり校正された不確実性に加えて、形状、アフォーダンス、制約、リスクなどのタスク固有の出力が必要です。今後1年ほどで、ベンチマークは特徴予測や視覚推論から、ナビゲーション、安全性テスト、設計判断、科学的な候補選別に予測展開が役立つかを問う行動条件付きテストへ広がるでしょう。約36か月後には、生成モデル、理解モジュール、メモリ、確率的な展開エンジン、校正層、機能的ベンチマークを組み合わせたハイブリッドシステムに研究が収れんする可能性があります。目標は、あるタスク、行動、時間幅、領域に対して、その予測展開が有効だと認定できるようにすることです。応用では、ワールドモデルがシミュレーションや計画パイプラインのミドルウェアとなり、想像された未来を、プランナーや人間の専門家が使える制約、アフォーダンス、反事実、リスク範囲へ変換する役割を担うかもしれません。
近い将来の進歩は、状態や因果性をモデル内部だけで解決する新しいアーキテクチャから来るとは限りません。一部のチームは、ワールドモデルをランタイムチェックで包む方法を選ぶかもしれません。ここでいうランタイムチェックとは、モデルが使われている最中に動く監視器のことです。今後1年ほどで、評価はオフラインのベンチマーク点数から、ロールアウト中のオンラインプローブ、不確実性モニター、状態一貫性スコア、因果違反検出器へ移っていく可能性があります。特徴空間での予測や生成された視覚的推論ステップは、生のピクセルより調べやすい構造化された信号を作るため、この方向に合っています。約36か月後には、ワールドモデルの周囲に適応的な観測可能性レイヤーが作られるかもしれません。そのようなシステムは、悪いロールアウトを検出して、再シミュレーション、モデル切り替え、メモリ更新、プランナーへのフォールバックを起動し、同時に形式的な契約が許容される状態遷移、不確実性水準、因果反応を定義します。応用では、ロボット、産業シミュレーション、自動設計、科学的計画のワークフローが、こうしたランタイム契約を満たすかどうかでワールドモデルのバックエンドを選び、信頼指標、警告、監査記録、オーケストレーション用フックがより長く残る層になる可能性があります。
1年後・3年後の研究/応用インフォグラフィクス
参照論文
- Thinking with Generated Images - 著者: Ethan Chern, Zhulin Hu, Steffi Chern, Siqi Kou, Jiadi Su, Yan Ma, Zhijie Deng, Pengfei Liu, / <See Details on Fugu-MT> / ライセンス: CC-BY-SA-4.0
- VFMF: World Modeling by Forecasting Vision Foundation Model Features - 著者: Gabrijel Boduljak, Yushi Lan, Christian Rupprecht, Andrea Vedaldi, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0
- A Mechanistic View on Video Generation as World Models: State and Dynamics - 著者: Luozhou Wang, Zhifei Chen, Yihua Du, Dongyu Yan, Wenhang Ge, Guibao Shen, Xinli Xu, Leyi Wu, Man Chen, Tianshuo Xu, Peiran Ren, Xin Tao, Pengfei Wan, Ying-Cong Chen, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0