Summary
This week's papers frame advanced video and multimodal generative systems as emerging world models rather than mere content generators. The common focus is on representing state and dynamics more explicitly, handling uncertainty beyond raw pixel prediction, and organizing capability levels for agentic world modeling.
Situation
The representative papers describe a shift in visual generation from producing realistic outputs toward modeling how scenes and environments evolve. A survey on video generation argues that recent systems increasingly resemble world models because they show physical coherence, yet they still lack key properties of classical world models: explicit state representations, clean causal decoupling, and efficient long-range reasoning. This makes persistence, causality, and the evaluation of generated behavior central concerns.
The other papers pursue this agenda through alternative representations and reasoning formats. One argues that pixel prediction is often unnecessarily expensive and not directly actionable, proposing stochastic forecasting in vision foundation model feature spaces so that future states can be decoded into semantic, geometric, or RGB outputs while retaining uncertainty awareness. Another argues that text-only chain-of-thought captures only part of problem solving, and proposes "Thinking with Generated Images," where a unified multimodal model produces visual intermediate steps as part of its reasoning process.
Infographic (English)

Progress
Visual Generation in the New Era: An Evolution from Atomic Mapping to Agentic World Modeling <See Details on Fugu-MT>
Frames visual generation as a five-stage progression from atomic mapping to agentic world modeling, identifying key technical drivers at each stage. Adds a structured taxonomy that distinguishes levels of generation capability, going beyond the general observation that video models approximate world models.
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond <See Details on Fugu-MT>
Defines three capability levels for agentic world models: local predictor, multi-step simulator respecting domain laws, and self-correcting evolver. Introduces an explicit hierarchy built around action-conditioned rollouts and model revision, sharpening the earlier discussion of missing causal structure.
GenMatter: Perceiving Physical Objects with Generative Matter Models <See Details on Fugu-MT>
Proposes a generative model that groups low-level motion cues and high-level appearance features into particles representing movable physical objects. Moves toward more explicit physical state representations compared with scene-level generation that lacks per-object decomposition.
Outlook
Outlook Summary
The next step for generative world models is likely to be a tighter link between evaluation and model design. The main bottlenecks are persistence, causality, long-horizon consistency, and action-conditioned rollout quality, not just visual realism. Near-term benchmarks will probably test whether models preserve state, support causal behavior, and produce useful future rollouts. Modeling work points toward explicit or hybrid state representations, uncertainty-aware forecasting, learned memory beyond fixed context windows, and closer integration between generation and understanding. Progress in multimodal reasoning with generated visual thoughts will also depend on efficient visual tokens and stronger post-training methods.
Infographic (English)
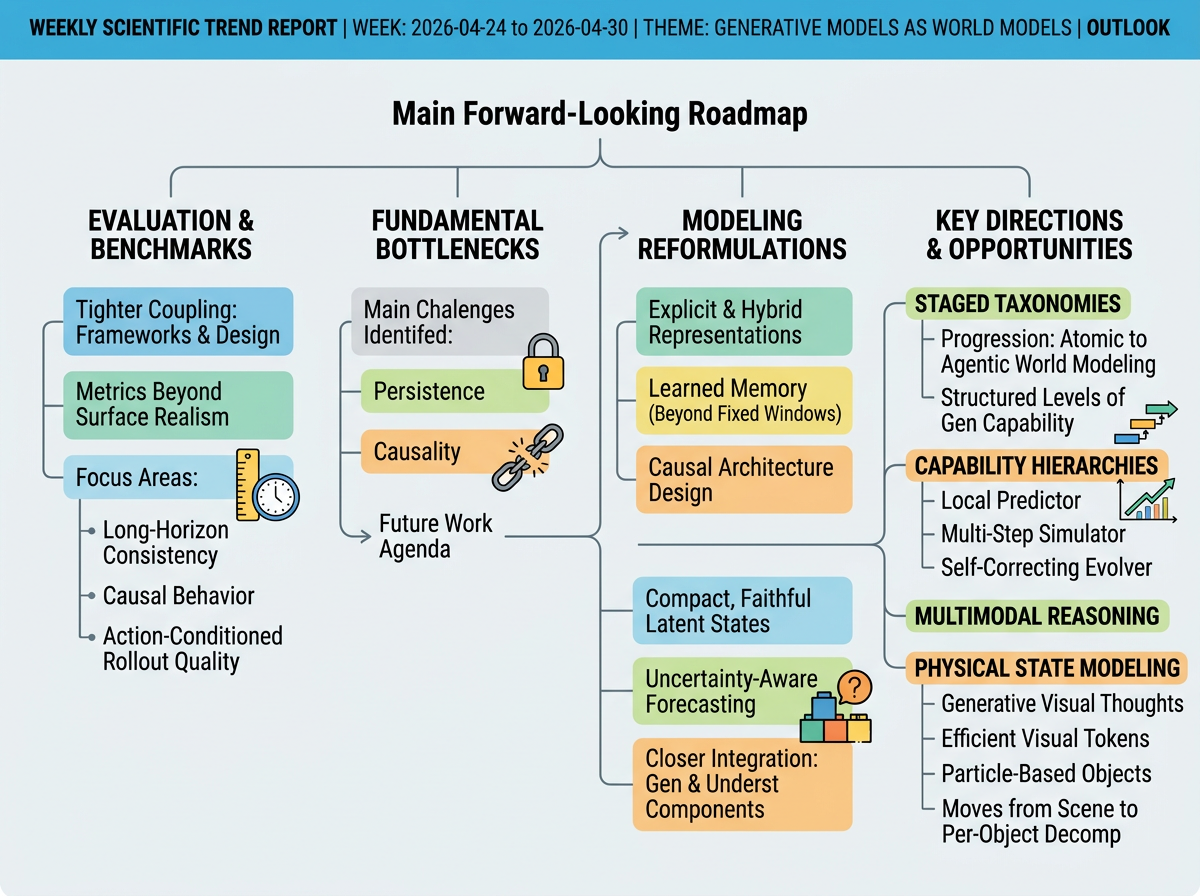
Three-Year Movement
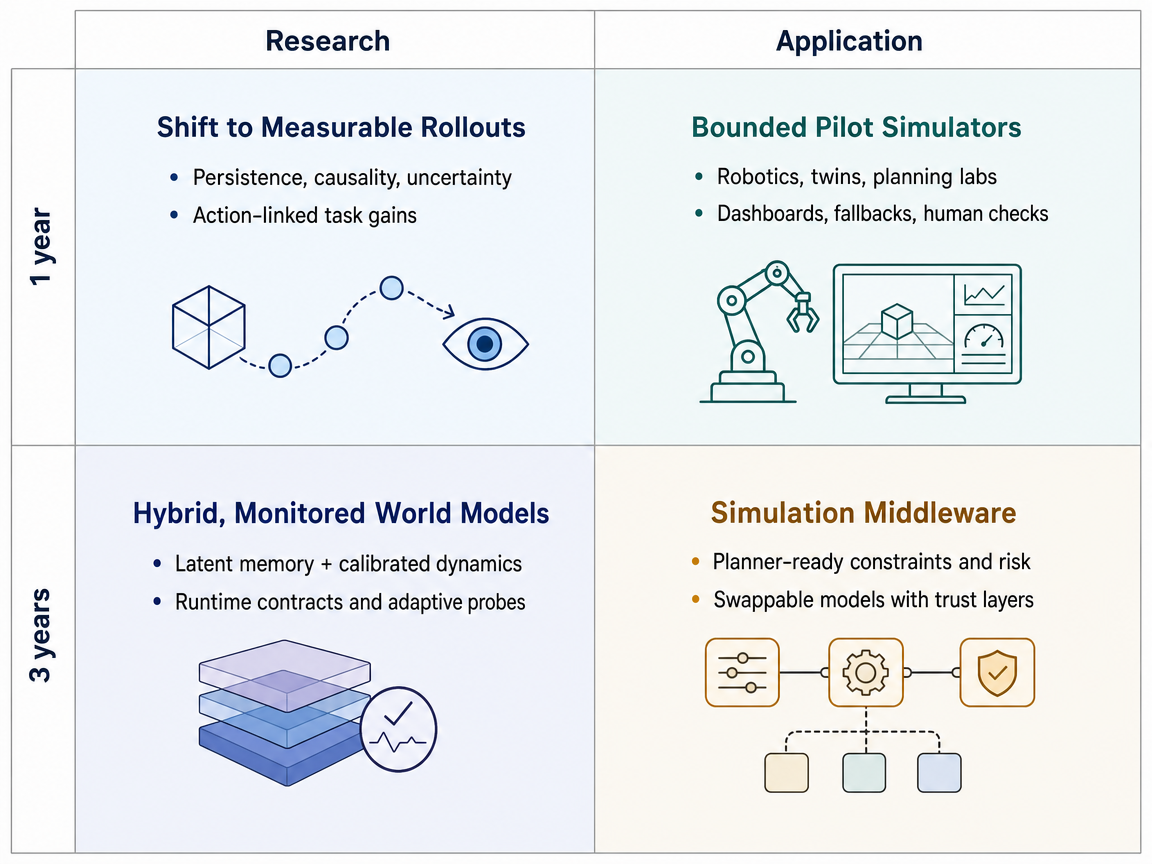
Over the next year, research is likely to judge world models by whether they track state, causality, and action-conditioned change, not only by whether their images or videos look realistic. Feature-space forecasting, generated visual thoughts, and mechanistic video evaluations all push in this direction. By about 36 months, the stronger systems should look more standardized. They will combine compressed latent state, meaning a compact internal model of the world, with persistent memory, action-conditioned dynamics, and causal tests. The central question will shift from whether a model can imagine a plausible future to whether its internal state can support interventions, counterfactuals, and reliable task outcomes. In use, these models are most likely to become bounded simulation components inside robotics policy testing, digital twins, automated design exploration, virtual training, and AI safety evaluation. They will still face compute cost, imperfect causality, and long-horizon drift, so they will work best where actions, state variables, rollout length, and success metrics are clearly defined.
Near-term work is likely to keep linking evaluation with model design, but the practical bottleneck may become usability by other systems. A planner, robot, simulator, or decision-support tool needs more than a plausible generated future. It needs calibrated confidence, where stated uncertainty matches real error, plus task-specific outputs such as geometry, affordances, constraints, and risk. Over the next year, this should expand benchmarks from feature forecasting and visual reasoning into action-conditioned tests that ask whether rollouts improve navigation, safety testing, design choices, or scientific triage. By about 36 months, research may settle around hybrid systems with generative models, understanding modules, memory, stochastic rollout engines, calibration layers, and functional benchmarks. The goal would be to certify when a rollout is valid for a particular task, action, time horizon, and domain. In application, world models could become middleware inside simulation and planning pipelines, translating imagined futures into constraints, affordances, counterfactuals, and risk envelopes that planners and human experts can use.
Near-term progress may not come only from a new architecture that solves state and causality inside the model. Some teams may instead wrap world models with runtime checks, which are monitors that run while the model is being used. Over the next year, this would move evaluation from offline benchmark scores toward online probes, uncertainty monitors, state-consistency scores, and causal-violation detectors during rollouts. Feature-space forecasts and generated visual reasoning steps fit this path because they create structured signals that are easier to inspect than raw pixels. By about 36 months, this could become an adaptive observability layer around world models. Such systems would detect bad rollouts and trigger re-simulation, model switching, memory refresh, or planner fallback, while formal contracts define acceptable state transitions, uncertainty levels, or causal responses. In application, robotics, industrial simulation, automated design, and scientific-planning workflows might choose world-model backends based on whether they satisfy these runtime contracts, with trust metrics, alerts, audit trails, and orchestration hooks becoming the more durable layer.
1-Year / 3-Year Research-Application Infographic
References
- Thinking with Generated Images - Authors: Ethan Chern, Zhulin Hu, Steffi Chern, Siqi Kou, Jiadi Su, Yan Ma, Zhijie Deng, Pengfei Liu, / <See Details on Fugu-MT> / License: CC-BY-SA-4.0
- VFMF: World Modeling by Forecasting Vision Foundation Model Features - Authors: Gabrijel Boduljak, Yushi Lan, Christian Rupprecht, Andrea Vedaldi, / <See Details on Fugu-MT> / License: CC-BY-4.0
- A Mechanistic View on Video Generation as World Models: State and Dynamics - Authors: Luozhou Wang, Zhifei Chen, Yihua Du, Dongyu Yan, Wenhang Ge, Guibao Shen, Xinli Xu, Leyi Wu, Man Chen, Tianshuo Xu, Peiran Ren, Xin Tao, Pengfei Wan, Ying-Cong Chen, / <See Details on Fugu-MT> / License: CC-BY-4.0