Summary
This week saw continued progress on using transformer-based pretraining to enable in-context adaptation in sequential decision-making without weight updates. The background spans reward-centric algorithm distillation and few-shot imitation settings, highlighting practical bottlenecks in trajectory construction, data curation, training instability, and data efficiency. New work scales Decision Pre-Trained Transformers to multi-domain environments using flow matching.
Situation
Generalist decision-making agents are a long-standing goal, but standard online reinforcement learning is difficult to scale because it depends on interactive, environment-specific training. In domains such as robotics, data collection can be expensive or unsafe, making adaptation from a small number of demonstrations or prior interaction histories especially valuable. Large autoregressive models offer a path forward: they can condition on context and adapt at inference time without updating weights. However, sequential decision making poses challenges beyond supervised settings because errors compound and the agent must handle a wide range of states.
Within that framing, the representative papers show that in-context RL depends strongly on data design and model inductive bias. One line of work extends Algorithm Distillation toward cross-domain action models trained on histories of states, actions, and rewards, seeking self-correction from offline trajectories. Another demonstrates that generalization to unseen tasks improves when context includes full or partial trajectories rather than isolated examples. A third highlights that ICRL training is often unstable and data-hungry, motivating architectural modifications such as n-gram induction heads to reduce hyperparameter sensitivity and data requirements.
Infographic (English)
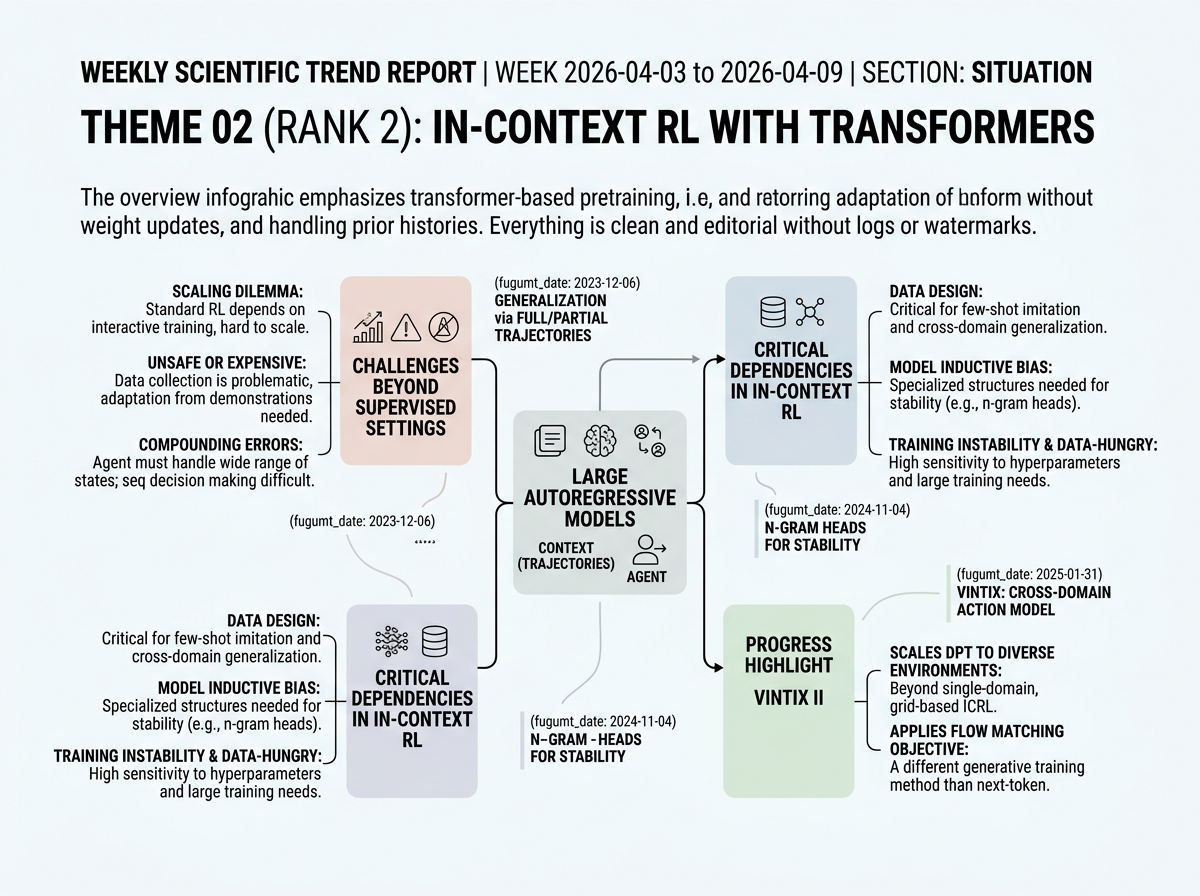
Progress
Vintix II: Decision Pre-Trained Transformer is a Scalable In-Context Reinforcement Learner <See Details on Fugu-MT>
Scales Decision Pre-Trained Transformers to diverse multi-domain environments and applies flow matching as the training objective for in-context RL. Prior work focused on single-domain or grid-based ICRL with standard next-token prediction; this extends the paradigm to broader environment coverage with a different generative training method.
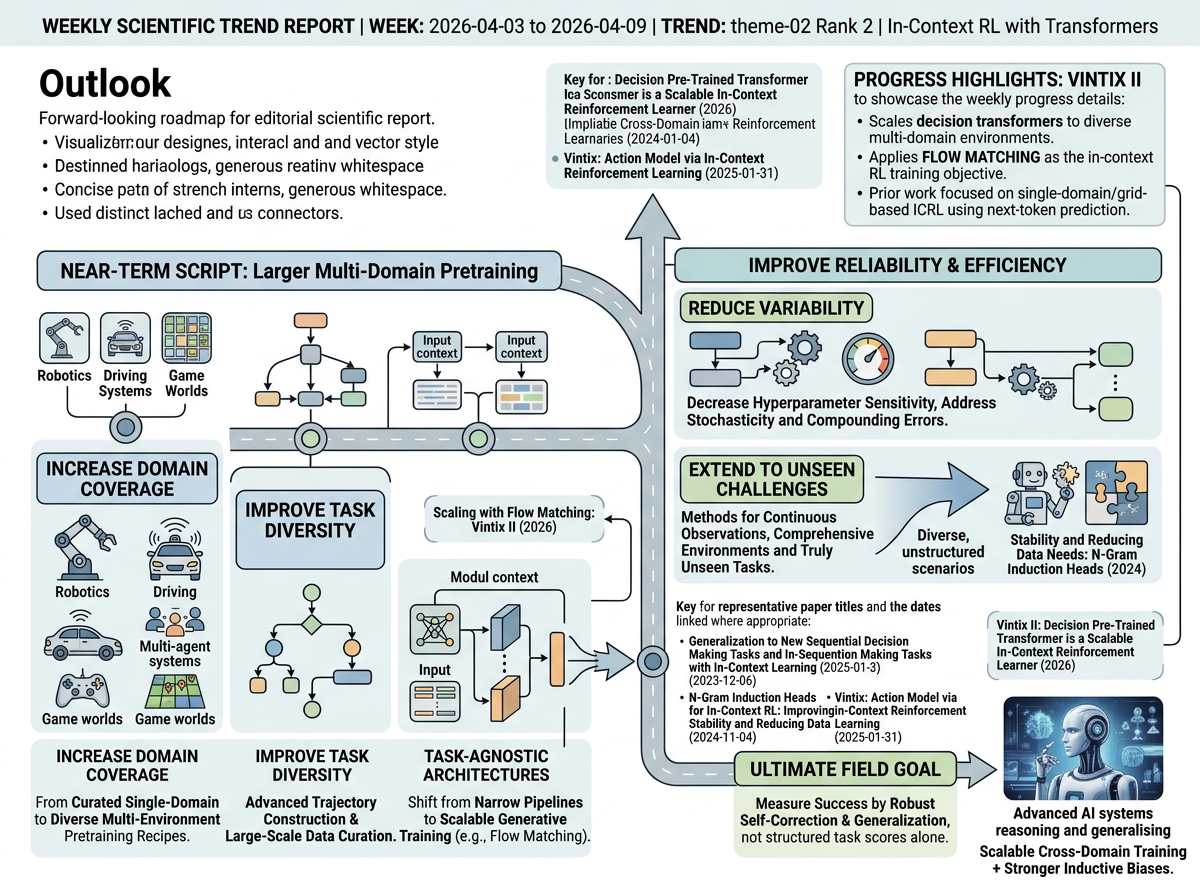
Outlook
The most likely near-term direction is a shift from carefully curated single-domain in-context RL pipelines toward larger multi-domain pretraining recipes. This week's scaling of Decision Pre-Trained Transformers across diverse domains with flow matching aligns with the representative papers' stated future-work goals: increasing domain coverage, improving task diversity and trajectory construction, and developing more task-agnostic architectures that preserve inference-time adaptation while reducing dependence on narrow data curation.
A second direction is improving reliability and data efficiency under more challenging conditions. The cited future work points to reducing hyperparameter sensitivity, extending methods to more comprehensive environments and truly unseen tasks, and addressing failure modes from stochasticity, compounding errors, and continuous observations. Together, the evidence suggests the field is moving toward scalable cross-domain training combined with stronger inductive biases and better context design, with success increasingly measured by robust self-correction and generalization rather than performance on structured training tasks alone.
Infographic (English)
References
- Generalization to New Sequential Decision Making Tasks with In-Context Learning - Authors: Sharath Chandra Raparthy, Eric Hambro, Robert Kirk, Mikael Henaff, Roberta Raileanu / <See Details on Fugu-MT> / License: CC-BY-4.0
- N-Gram Induction Heads for In-Context RL: Improving Stability and Reducing Data Needs - Authors: Ilya Zisman, Alexander Nikulin, Andrei Polubarov, Nikita Lyubaykin, Vladislav Kurenkov, / <See Details on Fugu-MT> / License: CC-BY-4.0
- Vintix: Action Model via In-Context Reinforcement Learning - Authors: Andrey Polubarov, Nikita Lyubaykin, Alexander Derevyagin, Ilya Zisman, Denis Tarasov, Alexander Nikulin, Vladislav Kurenkov, / <See Details on Fugu-MT> / License: CC-BY-4.0