サマリー
今週の評価研究は、視覚モデルの評価方法と実際の運用条件との間に根強いギャップがあることを浮き彫りにしている。モバイル超解像および多種劣化復元に関する新たなチャレンジベンチマーク、さらに制御された合成航空画像データセットにより、より現実的かつ多面的な設定への評価の拡張が進んでいる。
テーマの状況
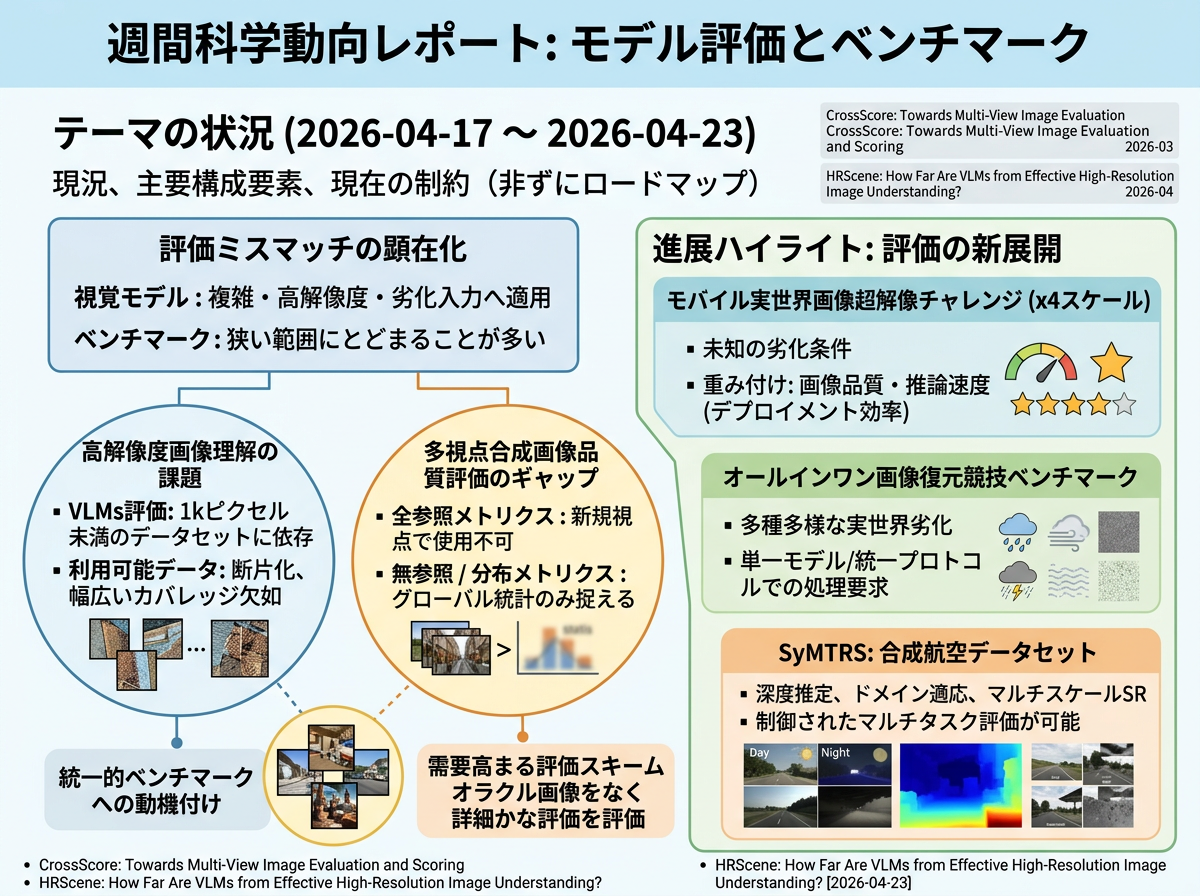
近年の研究は、評価における繰り返し生じるミスマッチを明らかにしている。視覚モデルは複雑・高解像度・劣化した入力への適用が進む一方、それらを測定するベンチマークは依然として狭い範囲にとどまることが多い。高解像度画像理解において、VLMの評価報告は通常、平均解像度が1kピクセルを大きく下回るデータセットに依存しており、利用可能な高解像度データセットはシナリオや解像度範囲ごとに断片化され、幅広い診断的カバレッジを欠いている。このことが、多様な実世界シーンと解像度レベルにまたがる統一的なベンチマークの必要性を動機づけている。
同様のギャップは、多視点合成における画像品質評価にも存在する。全参照メトリクスは、真に新規な視点では利用できない位置合わせされたグランドトゥルース画像を必要とし、無参照メトリクスや分布レベルのメトリクスはグローバルな統計量しか捉えられず、シーン固有の詳細を見逃す。これにより、オラクル画像を必要とせずに複数の参照ビューを活用して詳細なピクセルレベルの評価を提供する評価スキームへの需要が高まっている。
- CrossScore: Towards Multi-View Image Evaluation and Scoring
- HRScene: How Far Are VLMs from Effective High-Resolution Image Understanding?
インフォグラフィクス(日本語)
今週の進展
The First Challenge on Mobile Real-World Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview <See Details on Fugu-MT>
未知の劣化条件下での×4スケールのモバイル実世界画像超解像に関するチャレンジベンチマークを導入した。 再構成忠実度のみに焦点を当てた従来のSRベンチマークとは異なり、本トラックは画像品質スコアと推論速度を同時に重み付けし、デプロイメント効率を評価に組み込んでいる。
LoViF 2026 Challenge on Real-World All-in-One Image Restoration: Methods and Results <See Details on Fugu-MT>
多様な実世界劣化タイプにまたがるオールインワン画像復元の競技ベンチマークを確立した。 単一劣化の評価を超え、単一モデルと統一プロトコルの下で複数の劣化条件を処理することを手法に要求する。
SyMTRS: Benchmark Multi-Task Synthetic Dataset for Depth, Domain Adaptation and Super-Resolution in Aerial Imagery <See Details on Fugu-MT>
深度推定、ドメイン適応、マルチスケール超解像のためのペアアセットを備えた大規模合成航空データセット(SyMTRS)を提供した。 ピクセル精度の深度マップ、昼夜の対応画像、2048×2048での×2/×4/×8低解像度バリアントを提供し、既存の実世界航空データセットでは実現できない制御されたマルチタスク評価を可能にしている。
今後の展望
今後の展望(要約)
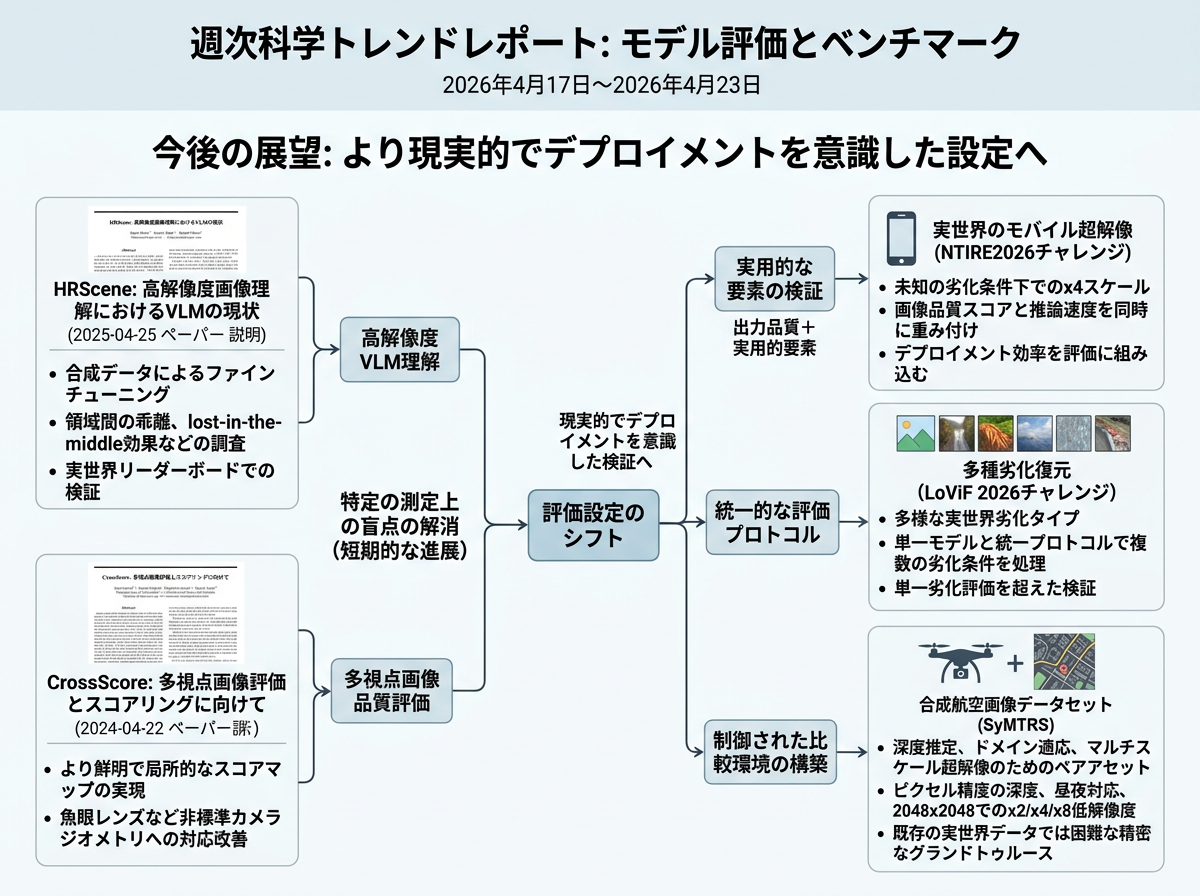
評価は、出力品質だけでなく実運用上の制約も測る、より現実的で配備を意識したテストへ移りつつある。新しいベンチマークは、速度を含むモバイル超解像、複数劣化の画像復元、正確な正解付き航空画像、高解像度VLMの失敗、多視点品質評価を完全な参照なしで扱う。近い将来は、領域ごとの失敗、長い入力の中央部分を見落とす問題、局所的なスコアマップ、難しいカメラ幾何への対応が重要になる。
インフォグラフィクス(日本語)
3年後を想定した動き
今後1年ほどで、現実的な視覚モデル評価は、完全なテストを行う流れと、安価な代理テストを使う流れに分かれる可能性が高い。大規模研究所は、HRSceneのような高解像度研究や、CrossScoreのような多視点品質テストを実行できる。一方で多くの研究グループは、小さな入力、データの一部、または簡略化した手順に頼ることになる。これによりベンチマークに基づく有用な調整は進むが、論文や製品の結果を互いに比較しにくくなる。3年程度先には、完全評価の診断力を保ったまま、安価なベンチマーク部分集合をどう設計するかが主要課題になりそうだ。研究者は完全監査と代理スイートを比べ、順位や失敗診断がどの条件で変わるかを測るだろう。実務では、大企業や安全性が重要な用途は完全な高解像度・多視点監査に費用をかけ、多くの利用者は予算と日程に合う代理テストを使う二層構造になりやすい。
近い将来、この分野は単にデータセットを増やす段階から、あるベンチマーク得点が新しい環境でも信頼できるのかを問う段階へ進みそうだ。HRScene型の研究では、解像度、画像内の領域、物体サイズ、タスク種別ごとの結果が報告される可能性がある。CrossScore型の研究では、局所的な品質マップ、不確実性推定、魚眼、航空、広角、産業用画像への対応が追加されるかもしれない。これは3年程度の動きとして、評価が孤立した学術リーダーボードではなく、検証インフラになるという方向につながる。ベンチマークは、実運用条件での性能を予測できるかという予測的妥当性で判断されるようになるだろう。評価パイプラインは、高解像度診断、正解なしの多視点指標、幾何アダプタ、不確実性報告、失敗マップ、速度や頑健性の確認を組み合わせる。応用現場では、調達担当、審査委員会、産業QA部門、オープンソースツールが、高解像度VLMや多視点視覚システムの承認前に、校正された証拠を求めるようになる可能性がある。
近い将来の研究では、評価を単なる順位表ではなく、モデル改善のための手がかりとして扱う傾向が強まりそうだ。チームは、大きな画像を有用な部分に分ける動的タイリングや、重要領域を追加処理に送るクロップルーティングを試すだろう。また、不確かな領域をモデルに再確認させる領域再問い合わせも使われる可能性がある。既知の失敗モードを明らかにする人工的な訓練例、つまり合成診断用ファインチューニングも利用されるかもしれない。この流れが3年ほど続けば、モデルは評価器を意識した検査ループを設計の一部として持つようになる。モデル論文やモデルカードでは、総合精度だけでなく、画像領域、カメラ視点、幾何タイプ、劣化、計算コストごとの振る舞いを報告する必要が出てくる。配備時の検証は、局所的な高解像度診断、正解不要の多視点チェック、速度・メモリ試験、頑健性試験、用途別ストレスケースをまとめた監査パックを中心に整理されるだろう。
1年後・3年後の研究/応用インフォグラフィクス

参照論文
- CrossScore: Towards Multi-View Image Evaluation and Scoring - 著者: Zirui Wang, Wenjing Bian, Omkar Parkhi, Yuheng Ren, Victor Adrian Prisacariu, / <See Details on Fugu-MT> / ライセンス: CC-BY-SA-4.0
- HRScene: How Far Are VLMs from Effective High-Resolution Image Understanding? - 著者: Yusen Zhang, Wenliang Zheng, Aashrith Madasu, Peng Shi, Ryo Kamoi, Hao Zhou, Zhuoyang Zou, Shu Zhao, Sarkar Snigdha Sarathi Das, Vipul Gupta, Xiaoxin Lu, Nan Zhang, Ranran Haoran Zhang, Avitej Iyer, Renze Lou, Wenpeng Yin, Rui Zhang, / <See Details on Fugu-MT> / ライセンス: CC-BY-4.0