Summary
This week's evaluation work highlights persistent gaps between how visual models are assessed and the conditions they face in practice. New challenge benchmarks for mobile super-resolution and multi-degradation restoration, along with a controlled synthetic aerial dataset, extend evaluation toward more realistic and multi-faceted settings.
Situation
Recent work reveals a recurring evaluation mismatch: visual models are increasingly applied to complex, high-resolution, or degraded inputs, yet the benchmarks used to measure them often remain narrow. In high-resolution image understanding, VLM evaluation reports typically rely on datasets whose average resolution is well below 1k pixels, while available high-resolution datasets are fragmented by scenario or resolution range and lack broad diagnostic coverage. This motivates unified benchmarks spanning diverse real-world scenes and resolution levels.
A parallel gap exists in image quality assessment for multi-view synthesis. Full-reference metrics require aligned ground-truth images that are unavailable for truly novel views, while no-reference and distribution-level metrics capture only global statistics and miss scene-specific detail. This drives demand for evaluation schemes that leverage multiple reference views to provide detailed, pixel-level assessment without requiring an oracle image.
Infographic (English)

Progress
The First Challenge on Mobile Real-World Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview <See Details on Fugu-MT>
Introduces a challenge benchmark for mobile real-world image super-resolution under unknown degradations at ×4 scale. Unlike prior SR benchmarks focused solely on reconstruction fidelity, this track jointly weights image-quality scores and inference speed, incorporating deployment efficiency into the evaluation.
LoViF 2026 Challenge on Real-World All-in-One Image Restoration: Methods and Results <See Details on Fugu-MT>
Establishes a competitive benchmark for all-in-one image restoration across varied real-world degradation types. Moves beyond single-distortion evaluation by requiring methods to handle multiple degradation conditions within a single model and unified protocol.
SyMTRS: Benchmark Multi-Task Synthetic Dataset for Depth, Domain Adaptation and Super-Resolution in Aerial Imagery <See Details on Fugu-MT>
Provides a large-scale synthetic aerial dataset (SyMTRS) with paired assets for depth estimation, domain adaptation, and multi-scale super-resolution. Offers pixel-perfect depth maps, day-night counterparts, and ×2/×4/×8 low-resolution variants at 2048×2048, enabling controlled multi-task evaluation that existing real-world aerial datasets cannot support.
Outlook
Outlook Summary
Evaluation is shifting toward realistic, deployment-aware tests that measure practical constraints as well as output quality. New benchmarks cover mobile super-resolution with speed, multi-degradation restoration, aerial imagery with exact ground truth, high-resolution VLM failures, and multi-view quality without perfect references. Near-term work should target regional failures, lost-in-the-middle effects, localized score maps, and difficult camera geometries.
Infographic (English)
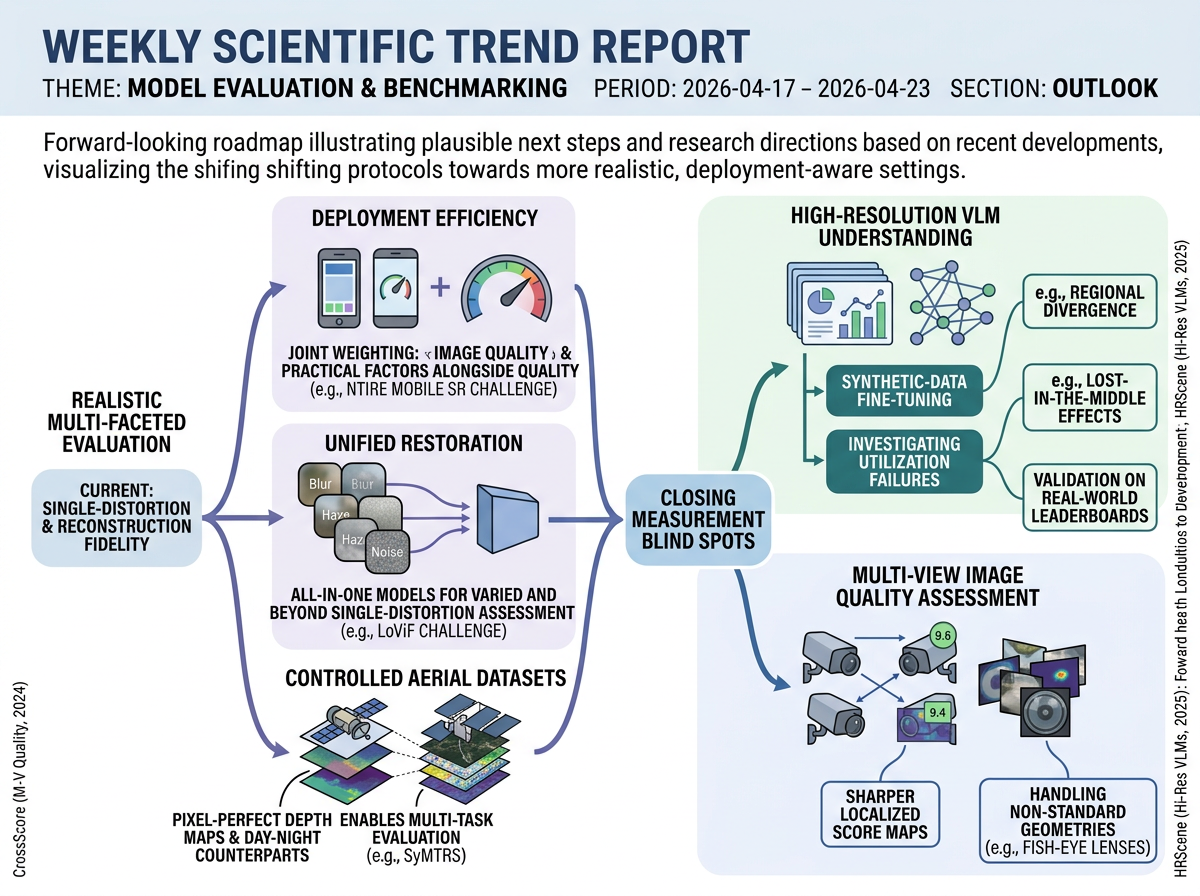
Three-Year Movement
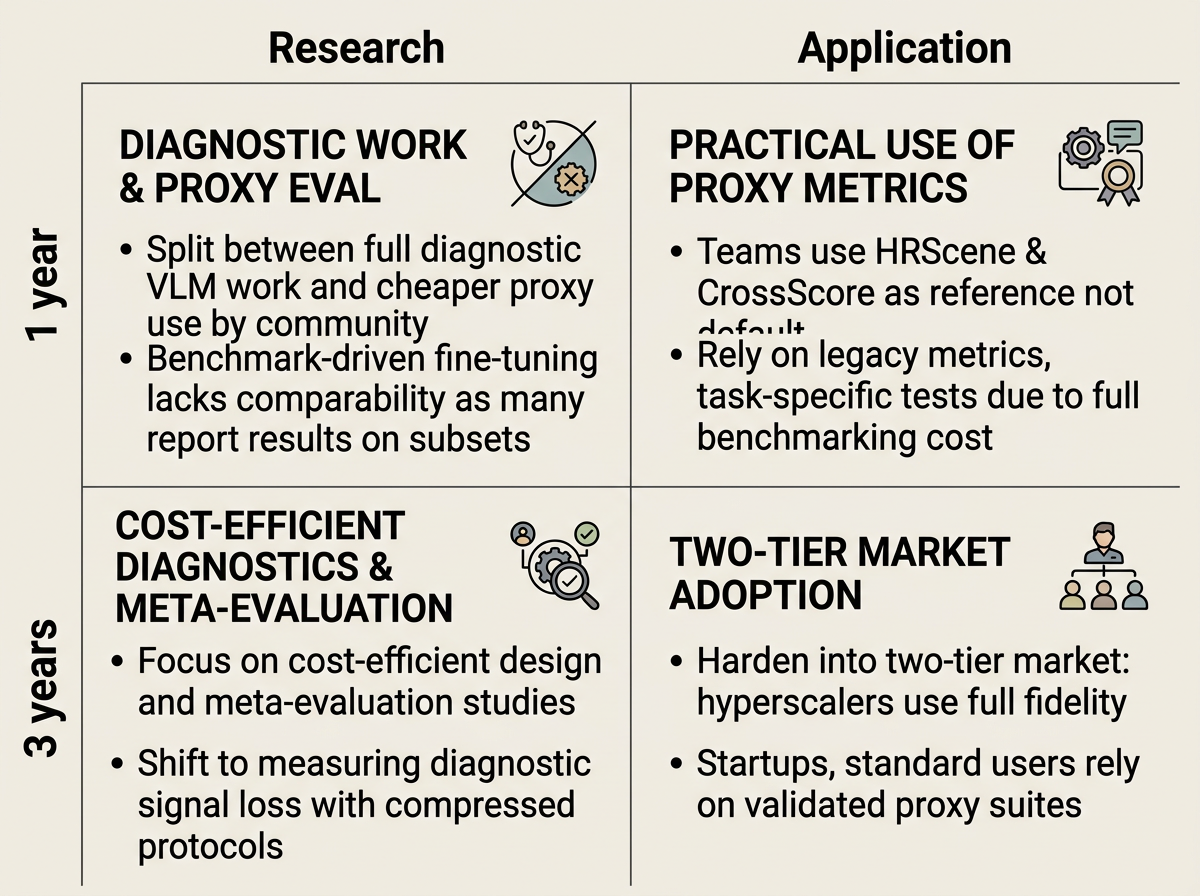
Over the next year, realistic visual-model evaluation will probably split into a full-test track and a cheaper proxy track. Large labs may run HRScene-style high-resolution studies and CrossScore-style multi-view quality tests, while many groups use smaller inputs, subsets, or simplified protocols. This will create useful benchmark-driven tuning, but it will also make results harder to compare across papers and products. Around three years out, the main research problem may become how to design cheap benchmark subsets that still preserve the diagnostic signal of the full evaluations. Researchers will compare full audits with proxy suites and measure when rankings or failure diagnoses change. In practice, a two-tier system is likely: large firms and safety-critical programs pay for full high-resolution and multi-view audits, while most users rely on proxy tests that fit budget and schedule limits. Standards may mention deployment-aware evaluation, but detailed rules will lag until cheaper tests are proven reliable.
In the near term, the field is likely to move from simply adding datasets toward asking when a benchmark score can be trusted in a new setting. HRScene-style work may report slices by resolution, image region, object size, and task type, while CrossScore-like work may add local quality maps, uncertainty estimates, and support for fish-eye, aerial, wide-angle, and industrial imagery. This connects directly to the three-year movement: evaluation could become validation infrastructure rather than isolated academic leaderboards. Benchmarks would be judged by predictive validity, meaning whether they forecast performance under real deployment conditions. Evaluation pipelines may combine high-resolution diagnostics, no-ground-truth multi-view metrics, geometry adapters, uncertainty reporting, failure maps, and speed or robustness checks. In applications, procurement teams, review boards, industrial QA groups, and open-source toolkits could require calibrated evidence before approving high-resolution VLMs or multi-view vision systems. A generic leaderboard rank would still matter, but less than showing that the score transfers to the user’s real camera, resolution, latency limit, and risk profile.
Near-term work is likely to treat evaluation as a guide for improving models, not only as a scoreboard. Teams may test dynamic tiling, which splits a large image into useful parts, crop routing, which sends important regions through extra processing, and region re-querying, which asks the model to inspect uncertain areas again. They may also use synthetic diagnostic fine-tuning, meaning artificial training examples built to expose known failure modes. If this path continues for about three years, models could include evaluator-aware inspection loops as part of their design. Model papers and model cards may need to report behavior across image regions, camera views, geometry types, degradations, and compute costs, not just total accuracy. Deployment validation may become organized around audit packs that combine local high-resolution diagnostics, ground-truth-free multi-view checks, speed and memory tests, robustness tests, and domain-specific stress cases. This would give buyers, safety reviewers, and platform teams a more concrete way to judge whether a visual model is trustworthy for its exact high-resolution or multi-view operating conditions.
1-Year / 3-Year Research-Application Infographic
References
- CrossScore: Towards Multi-View Image Evaluation and Scoring - Authors: Zirui Wang, Wenjing Bian, Omkar Parkhi, Yuheng Ren, Victor Adrian Prisacariu, / <See Details on Fugu-MT> / License: CC-BY-SA-4.0
- HRScene: How Far Are VLMs from Effective High-Resolution Image Understanding? - Authors: Yusen Zhang, Wenliang Zheng, Aashrith Madasu, Peng Shi, Ryo Kamoi, Hao Zhou, Zhuoyang Zou, Shu Zhao, Sarkar Snigdha Sarathi Das, Vipul Gupta, Xiaoxin Lu, Nan Zhang, Ranran Haoran Zhang, Avitej Iyer, Renze Lou, Wenpeng Yin, Rui Zhang, / <See Details on Fugu-MT> / License: CC-BY-4.0